
eBook - ePub
Fast Facts: Medical Statistics
Understanding Clinical Trial Results
- 108 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
About this book
Using real examples from oncology trials, but keeping it simple, this concise resource explains the basic principles of medical statistics so that you can better appraise clinical trial results. Key concepts covered in this book include: ; hypothesis testing ; Kaplan–Meier curves and other graphic representations of data ; calculating the power of a study ; the stopping rules for efficacy and futility. ' Fast Facts: Medical Statistics' is aimed at all clinicians, clinical scientists, medical writers and regulatory personnel who need a better understanding of the statistical terms and methods used in the planning of studies and the analysis of clinical trial data. If you have ever wanted to know what a type I error is, how an odds ratio is calculated or what a forest plot is really all about, then this is the book for you.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
| 1 | Statistical inference |
In clinical trials, an endpoint is an outcome value that is measured for each individual subject in the trial. The values of these endpoints are then summarized for a group of subjects (summary statistics): for example, a summary value for all subjects who received a particular treatment. This summary value can then be compared with the summary value of other groups in the trial. These results and the conclusions drawn from them are then extrapolated to the population as a whole.
Endpoint types
The type of statistical method used to analyze trial data depends on the type of endpoint that is measured. Common endpoint types are:
•continuous
•score
•count
•binary
•ordered categorical
•time to event.
Continuous endpoints are measured on a continuum of possible values over time: for example, a change in bone mineral density or blood pressure.
Score endpoints are endpoints that arise from scales constructed to capture a discrete value for something that cannot be measured in a continuous way. Examples include scales that provide a score for quality of life or severity of depression.
Count endpoints measure the number of items or events during a specified period: for example, the number of migraine headaches over 28 days.
Binary endpoints represent a dichotomy: a ‘yes or no’ type of measurement (e.g. success/failure, progression/no progression, survival/death). A common example in oncology is responder versus non-responder, where a responder is a patient whose best response is a complete or partial response, and where a non-responder is a patient whose best response is stable disease or disease progression.
Ordered categorical endpoints occur when an outcome is measured in categories and the categories have an implicit order. In oncology, the response evaluation criteria in solid tumors (RECIST) – complete response, partial response, stable disease or disease progression – are an example. However, when the endpoint is collapsed (e.g. responder versus non-responder), the ordered categorical endpoint is reduced to a binary endpoint.
Time to event. Many endpoints in oncology measure the time to event (see Chapter 2). Examples include overall survival, which measures time to death, and progression-free survival, which measures the time to death or progression, whichever occurs first. Time-to-event endpoints are usually measured from the point of randomization, but not always. Duration of response is an endpoint that is measured from the time of first response to progression.
Summary statistics
Summary statistics provide a quick and simple description of a set of data values. Usually, the sample’s average (mean), middle (median) or most common (mode) value is used.
Example 1.1
Five women are diagnosed with breast cancer at ages 45, 50, 52, 54 and 54. To calculate the mean age of diagnosis:
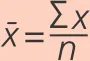
where x is a value, x̅ is the mean, ∑ x is the sum of all x values and n is the number of values.

The mean age of diagnosis in this sample is 51.
Mean. The mean is the arithmetic average, i.e. the sum of all values divided by the number of values. It is denoted by x̅.
The mean is a good measure of comparison to use for sample groups with continuous and score endpoints, provided the endpoint data have a symmetric distribution (Figure 1.1a).
The mean is also a good measure of comparison for samples with count endpoints, but these are usually calculated as means per unit of time to account for different observation periods for different patients.
Median. When the data distribution is skewed (see Figure 1.1b,c), i.e. some of the values are a lot smaller or larger than the others, the mean is not usually the best measure of average. In these cases, the median is often the preferred measurement. The median is the middle value when the data values are placed in order from smallest to largest. It is sometimes denoted by x̅.
Mode. The mode is the most common value (see Figure 1.1). It is used to describe the most frequently occurring outcome, but in general it is of limited value in clinical trials.
Proportions. Comparing the means of binary endpoints makes no sense. Instead, proportions are compared; in this book the symbol r is used to denote a proportion.

Figure 1.1 Position of the mean, median and mode, depending on the distribution of data. (a) The mean is a good measure to use when the spread of data is similar on each side of the mid-point (symmetric distribution). A common example of this is normal (or Gaussian) distribution. When the data are (b) negatively or (c) positively skewed, the median is the preferred measurement for average. The mode is rarely used.
Proportions for ordered categorical endpoints are also compared between treatment groups, but in such cases the order needs to be taken into account; the statistical procedures that are used take account of the order.
Kaplan–Meier curves are used to compare time-to-event endpoints (see Chapter 2).
Standard deviation (SD) is a measure of patient-to-patient variability. It is particularly important in the analysis of continuous and score endpoints. The SD is the average distance of all data values from the mean. It is not the simple average but a weighted average that gives rather more weight to the points well away from the mean.
SD is most frequently used for data with a symmetric distribution (Figure 1.2).

Figure 1.2 For data with a normal distribution, a range of one standard deviation (SD) above and below the mean (± 1SD) includes 68.2% of the values. ± 2SD includes 95.4% of the data. ± 3SD includes 99.7% of the data.
Sample and population
The sample of patients recruited into a clinical trial will be drawn from the population of interest. This population is defined by the inclusion and exclusion criteria, i.e. a set of characteristics, such as stage of disease or previous treatments, that are used to define a subject’s eligibility (or ineligibility) for the study.
Inference. Statisticians talk about making inferences about the population based on data from a sample of patients drawn from that population.
Example 1.2
Of 100 patients chosen from the p...
Table of contents
- Cover
- Title Page
- Copyright
- Contents
- List of abbreviations
- Glossary
- Introduction
- 1. Statistical inference
- 2. Analysis of time-to-event endpoints
- 3. Power and sample size
- 4. Multiplicity
- 5. Interim analysis
- 6. Modeling
- 7. Graphical methods
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Fast Facts: Medical Statistics by Richard Kay,Richard, Kay in PDF and/or ePUB format, as well as other popular books in Medicine & Public Health, Administration & Care. We have over one million books available in our catalogue for you to explore.