![]()
1 Grundlegende Konzepte
Dieses Kapitel macht Sie mit den Ideen einer dezentralen Versionsverwaltung vertraut und zeigt die Unterschiede zu einer zentralen Versionsverwaltung auf. Anschließend erfahren Sie, wie dezentrale Repositorys funktionieren und warum Branching und Merging keine fortgeschrittenen Themen in Git sind.
1.1 Dezentrale Versionsverwaltung – alles anders?
Bevor wir uns den Konzepten dezentraler Versionsverwaltung widmen, werfen wir einen kurzen Blick auf die klassische Architektur zentraler Versionsverwaltungen.
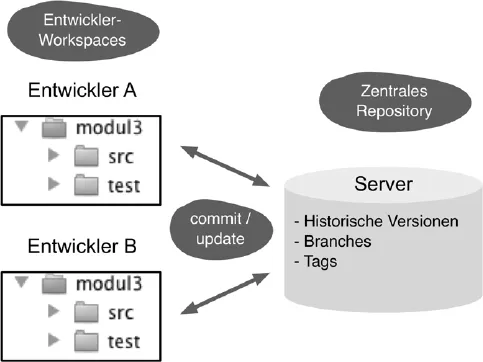
Abb. 1-1 Zentrale Versionsverwaltung
Abbildung 1-1 zeigt die typische Aufteilung einer zentralen Versions-verwaltung, z. B. von CVS oder Subversion. Jeder Entwickler hat auf seinem Rechner ein Arbeitsverzeichnis (Workspace) mit allen Projektdateien. Diese bearbeitet er, und er schickt die Änderungen regelmäßig per Commit an den zentralen Server. Per Update holt er die Änderungen der anderen Entwickler ab. Der zentrale Server speichert die aktuellen und historischen Versionen der Dateien (Repository). Parallele Entwicklungsstränge (Branches) und benannte Versionen (Tags) werden auch zentral verwaltet.
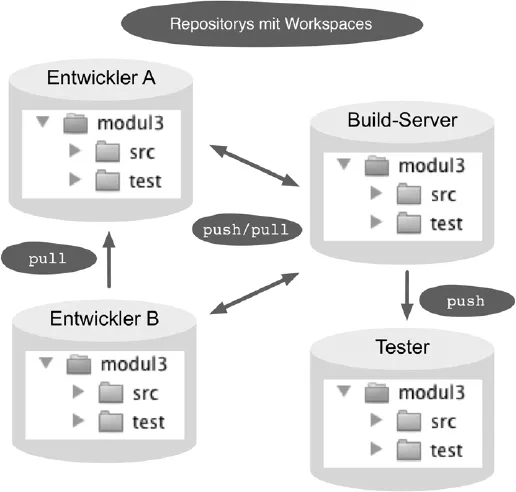
Abb. 1-2 Dezentrale Versionsverwaltung
Das Repository → Seite 37
Was sind Commits? → Seite 19
Austausch zwischen Repositorys → Seite 73
Bei einer dezentralen Versionsverwaltung (Abbildung 1-2) gibt es keine Trennung zwischen Entwickler- und Serverumgebung. Jeder Entwickler hat sowohl einen Workspace mit den in Arbeit befindlichen Dateien als auch ein eigenes lokales Repository (genannt Klon) mit allen Versionen, Branches und Tags. Änderungen werden auch hier durch ein Commit festgeschrieben, jedoch zunächst nur im lokalen Repository. Andere Entwickler sehen die neuen Versionen nicht sofort. Push- und Pull-Befehle übertragen Änderungen dann von einem Repository zum anderen. Technisch gesehen sind in der dezentralen Architektur alle Repositorys gleichwertig. Theoretisch bräuchte es keinen Server: Man könnte alle Änderungen direkt von Entwicklerrechner zu Entwicklerrechner übertragen. In der Praxis spielen Repositorys auf Servern auch in Git eine wichtige Rolle, zum Beispiel in Form von folgenden spezifischen Repositorys:
Blessed Repository: Aus diesem Repository werden die »offiziellen« Releases erstellt.
Ein Projekt aufsetzen → Seite 111
Shared Repository: Dieses Repository dient dem Austausch zwischen den Entwicklern im Team. In kleinen Projekten kann hierzu auch das Blessed Repository genutzt werden. Bei einer Multisite-Entwicklung kann es auch mehrere geben.
Workflow Repository: Ein solches Repository wird nur mit Änderungen befüllt, die einen bestimmten Status im Workflow erreicht haben, z. B. nach erfolgreichem Review.
Fork Repository: Dieses Repository dient der Entkopplung von der Entwicklungshauptlinie (zum Beispiel für große Umbauten, die nicht in den normalen Releasezyklus passen) oder für experimentelle Entwicklungen, die vielleicht nie in den Hauptstrang einfließen sollen.
Folgende Vorteile ergeben sich aus dem dezentralen Vorgehen:
Hohe Performance: Fast alle Operationen werden ohne Netzwerkzugriff lokal durchgeführt.
Effiziente Arbeitsweisen: Entwickler können lokale Branches benutzen, um schnell zwischen verschiedenen Aufgaben zu wechseln.
Offline-Fähigkeit: Entwickler können ohne Serververbindung Commits durchführen, Branches anlegen, Versionen taggen etc. und diese erst später übertragen.
Flexibilität der Entwicklungsprozesse: In Teams und Unternehmen können spezielle Repositorys angelegt werden, um mit anderen Abteilungen, z. B. den Testern, zu kommunizieren. Änderungen werden einfach durch ein Push in dieses Repository freigegeben.
Backup: Jeder Entwickler hat eine Kopie des Repositorys mit einer vollständigen Historie. Somit ist die Wahrscheinlichkeit minimal, durch einen Serverausfall Daten zu verlieren.
Wartbarkeit: Knifflige Umstrukturierungen kann man zunächst auf einer Kopie des Repositorys erproben, bevor man sie in das Original-Repository überträgt.
1.2 Das Repository – die Grundlage dezentralen Arbeitens
Das Repository ist im Kern ein effizienter Datenspeicher. Im Wesentlichen enthält es:
Das Repository → Seite 37
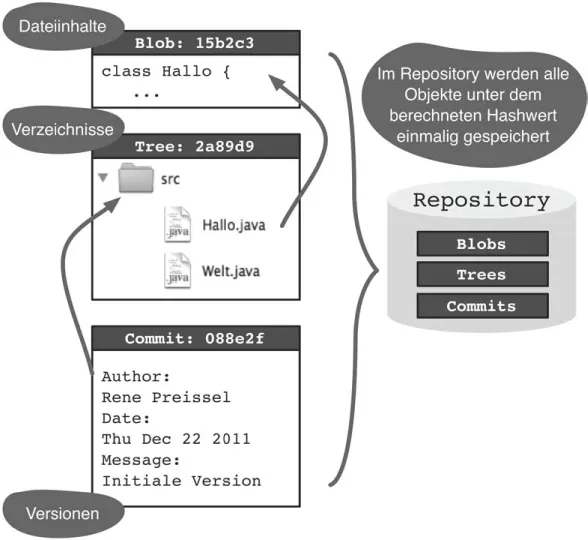
Inhalte von Dateien (Blobs): Dies sind Texte oder binäre Daten. Die Daten werden unabhängig von Dateinamen gespeichert.
Verzeichnisse (Trees): Verzeichnisse verknüpfen Dateinamen mit Inhalten. Verzeichnisse können wiederum andere Verzeichnisse beinhalten.
Versionen (Commits): Versionen definieren einen wiederherstellbaren Zustand eines Verzeichnisses. Beim Anlegen einer neuen Version werden der Autor, die Uhrzeit, ein Kommentar und die Vorgänger-version gespeichert.
Abb. 1-3 Ablage von Objekten im Repository
Für alle Daten wird ein hexadezimaler Hashwert berechnet, z. B. 1632acb65b01c6b621d6e1105205773931bb1a41. Diese Hashwerte dienen als Referenz zwischen den Objekten und als Schlüssel, um die Daten später wiederzufinden (Abbildung 1-3).
Die Hashwerte von Commits sind die »Versionsnummern« von Git. Haben Sie so einen Hashwert erhalten, können Sie überprüfen, ob diese Version im Repository enthalten ist, und können das zugehörige Verzeichnis im Workspace wiederherstellen. Falls die Version nicht vorhanden ist, können Sie das Commit mit allen referenzierten Objekten aus einem anderen Repository importieren (Pull).
Folgende Vorteile ergeben sich aus der Verwendung von Hashwerten und der Repository-Struktur:
Hohe Performance: Der Zugriff auf Daten über den Hashwert geht sehr schnell.
Redundanzfreie Speicherung: Identische Dateiinhalte müssen nur einmal abgelegt werden.
Dezentrale Versionsnummern: Da sich die Hashwerte aus den Inhalten der Dateien, dem Autor und dem Zeitpunkt berechnen, können Versionen auch »offline« erzeugt werden, ohne dass es später zu Konflikten kommt.
Effizienter Abgleich zwischen Repositorys: Werden Commits von einem Repository in ein anderes Repository übertragen, müssen nur die noch nicht vorhandenen Objekte kopiert werden. Das Erkennen, ob ein Objekt bereits vorhanden ist, ist dank der Hashwerte sehr performant.
Integrität der Daten: Der Hashwert wird aus dem Inhalt der Daten berechnet. Man kann Git jederzeit prüfen lassen, ob Daten und Hash-werte zueinanderpassen. Unabsichtliche Veränderungen oder böswillige Manipulationen der Daten werden so erkannt.
Automatische Erkennung von Umbenennungen: Werden Dateien umbenannt, wird das automatisch erkannt, da sich der Hashwert des Inhaltes nicht ändert. Es sind somit keine speziellen Befehle zum Umbenennen und Verschieben notwendig.
1.3 Branching und Merging – ganz einfach!
Branches verzweigen → Seite 45
Die Entwicklung aufzuzwei...