![]()
1Einleitung
Ulf Troppens · Nils Haustein
Ziel und Gliederung des Kapitels
In diesem Kapitel wollen wir die Grundidee des vorliegenden Buchs vermitteln. Dazu erläutern wir zunächst die Speicherhierarchie vom Prozessor über den Hauptspeicher zu Solid-State-Disks (SSDs), Festplatten und Bändern (Abschnitt 1.1). Danach stellen wir die beiden Speicherarchitekturen vor, die sich über Jahrzehnte bewährt haben: Wir erklären die serverzentrierte IT-Architektur und zeigen an einem Beispiel deren Nachteile (Abschnitt 1.2). Im Anschluss beschreiben wir als Alternative die speicherzentrierte IT-Architektur (Abschnitt 1.3) und erklären ihre Vorteile am Beispiel »Austausch eines Anwendungsservers« (Abschnitt 1.4). Dann beleuchten wir den Paradigmenwechsel von verteilten Systemen zu Pervasive Computing und Cloud Computing und die damit verbundenen neuen Anforderungen an die Verarbeitung und Speicherung von Daten (Abschnitt 1.5). Abschließend stellen wir die Gliederung des gesamten Buchs vor und benennen, welche Themen wir nicht behandeln (Abschnitt 1.6).
1.1Speicherhierarchie
Flüchtiger Speicher
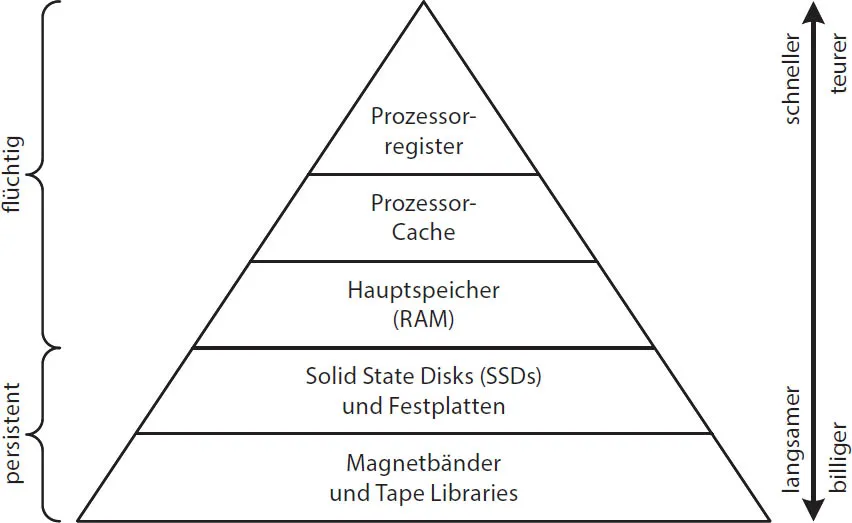
Seit Jahrzehnten ist die Architektur von Rechnern (Servern), Betriebssystemen und Anwendungen von einer Speicherhierarchie geprägt (Abb. 1–1). In und nahe an den Prozessoren (Central Processing Units, CPUs) findet sich schneller, flüchtiger Speicher wie Prozessorregister, Prozessor-Cache und Hauptspeicher (Random Access Memory, RAM). Flüchtig heißt, der Speicher verliert die gespeicherten Daten, wenn er nicht mehr mit Strom versorgt wird, wie bereits bei einer kurzen Stromunterbrechung.
Abb. 1–1Speicherhierarchie
Die Architektur von Servern, Betriebssystemen und Anwendungen ist von einer Speicherhierarchie geprägt.
Persistenter Speicher
Deswegen wird flüchtiger Speicher immer mit persistentem Speicher wie Solid-State-Disks (SSDs), Festplatten und Bändern kombiniert, der weiter von den Prozessoren entfernt ist. Persistent heißt, der Speicher behält die gespeicherten Daten auch dann, wenn er lange nicht mit Strom versorgt wird.
Zusammenspiel von flüchtigem und persistentem Speicher
Programmcode von Betriebssystem und Anwendungen und die eigentlichen Daten werden deswegen zunächst auf persistentem Speicher abgelegt. Betriebssystem und Anwendungen kopieren den Programmcode und die Daten vom persistenten Speicher in den flüchtigen, um dort den Code auszuführen und die Daten zu verarbeiten. Neue und veränderte Daten werden wiederum auf den persistenten Speicher geschrieben, um diese langfristig zu speichern.
Speicherhierarchie
Aus dem Zusammenspiel von flüchtigem und persistentem Speicher ergibt sich eine Speicherhierarchie. Es gilt, dass Speicher umso schneller und umso teurer ist, je dichter er am Prozessor ist. Deswegen sind Server in der Regel mit erheblich mehr persistentem Speicher ausgestattet als mit flüchtigem und es werden nur die Programmcodes und die Daten in flüchtigen Speicher kopiert, die man gerade benötigt. Alle anderen Programme und Daten verbleiben im persistenten Speicher.
Pervasive Computing
Die über Jahrzehnte bewährte Speicherhierarchie wird derzeit an zwei Stellen aufgebrochen. In der Vergangenheit wurden Daten überwiegend zentral auf einem oder wenigen Servern verarbeitet. Mit dem Einzug von Internet, Smartphones und Internet of Things (IoT) werden immer mehr Daten auf dezentralen, mobilen Geräten erzeugt, verarbeitet und gespeichert. Diese dezentralen Daten werden immer mehr mit zentral gespeicherten Daten verknüpft, sodass geschäftskritische Daten nun auch außerhalb der etablierten Speicherhierarchie verarbeitet werden. Diese neue Form der dezentralen Datenerzeugung, Datenverarbeitung und Datenspeicherung wird auch als Pervasive Computing bezeichnet.
Non-Volatile Memory (NVM)
Zum anderen ist es mit der Entwicklung von persistentem Hauptspeicher (Non-Volatile Memory, NVM) möglich, in einem Server persistenten Speicher nahe am Prozessor zu integrieren, sodass dieser darauf auf die gleiche Art und Weise zugreifen kann wie auf Hauptspeicher. Es sind erhebliche Änderungen an der Architektur der über Jahrzehnte gewachsenen Programme und Betriebssysteme notwendig, um daraus vollen Nutzen zu schöpfen. Diese Technologie steht heute (2018) erst noch am Anfang. Es deutet sich aber an, dass NVM die Architektur von Anwendungen und Betriebssystemen verändern wird.
Weitere Vorgehensweise
Im weiteren Verlauf dieses Kapitels werden wir uns zunächst mit Architekturen für herkömmliche verteilte Systeme beschäftigen (Abschnitte 1.2 bis 1.4) und dann mit dem Pervasive Computing auf die neue dezentrale Speicherung und Verarbeitung von Daten eingehen (Abschnitt 1.5). Techniken für die Einbindung von persistenten Hauptspeicher beschreiben wir später (Abschnitt 3.6.4).
1.2Die serverzentrierte IT-Architektur und ihre Beschränkungen
Serverzentrierte IT-Architektur
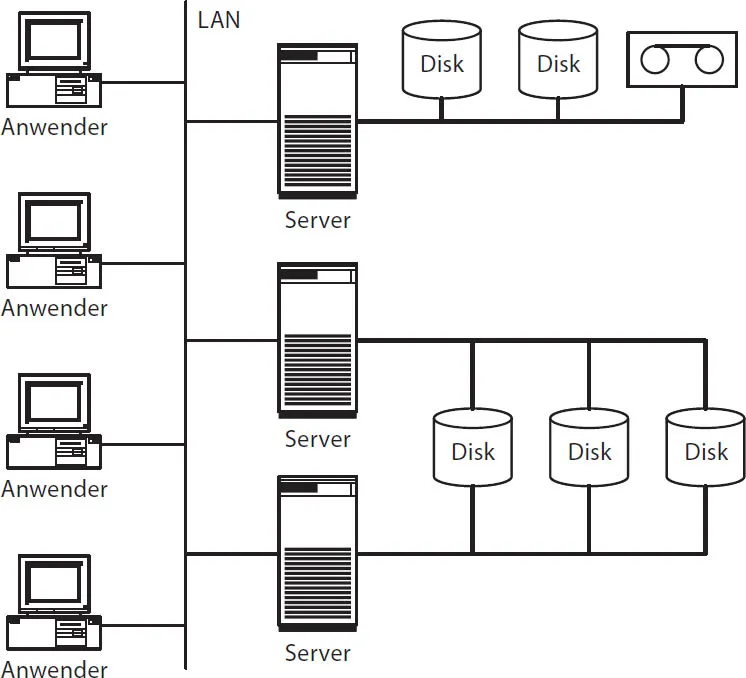
Die serverzentrierte IT-Architektur war bis etwa zum Jahr 2000 die vorherrschende Architektur für verteilte Systeme. In serverzentrierten IT-Architekturen werden Speichergeräte in der Regel nur an einen einzelnen Server angeschlossen (Abb. 1–2). Zur Erhöhung der Verfügbarkeit werden Speichergeräte manchmal auch mit zwei Servern verbunden (Twin-tailed Cabling), wobei zu einem Zeitpunkt aber immer nur ein Server das Speichergerät wirklich nutzen kann. In beiden Fällen existiert Speicher immer nur in Abhängigkeit von den Servern, an die er angeschlossen ist. Andere Server können nicht direkt auf die Daten zugreifen; sie müssen immer über den Server gehen, an dem der Speicher angeschlossen ist.
Abb. 1–2Serverzentrierte IT-Architektur
In der serverzentrierten IT-Architektur existiert Speicher nur in Abhängigkeit von Servern.
Mangelnde Verfügbarkeit der Daten
Wie bereits erwähnt existiert in herkömmlichen serverzentrierten IT-Architekturen Speicher immer nur in Abhängigkeit von den ein bis zwei Servern, an die er angeschlossen ist. Fallen diese beiden Server aus, so kann nicht mehr auf die Daten zugegriffen werden, wenn es keine weiteren Kopien gibt. Dies ist für viele Anwendungen nicht mehr akzeptabel: Zumindest ein Teil der Unternehmensdaten (zum Beispiel Patientendaten, Webseiten) muss rund um die Uhr verfügbar sein.
Unflexibel: Zuweisung freier Speicherkapazität
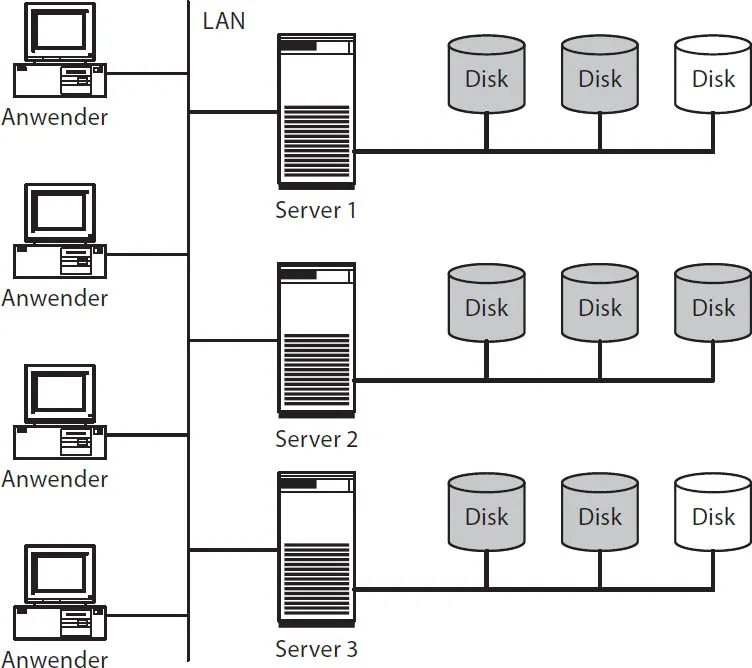
In serverzentrierten IT-Architekturen ist Speicher den Servern statisch zugeordnet, an die er angeschlossen wird. Klassische Anwendungen können nicht auf Speicher zugreifen, der mit anderen Servern verbunden ist. Wenn also ein Datenbanksystem mehr Speicher benötigt, als an einem Server angeschlossen ist, so nützt es überhaupt nichts, dass an anderen Servern noch Speicher vorhanden ist, der gerade nicht benötigt wird (Abb. 1–3).
Abb. 1–3Unflexible Zuweisung freier Speicherkapazität
Auf Server 2 ist die Speicherkapazität erschöpft. Anwendungen können nicht davon profitieren, dass an den Servern 1 und 3 noch Speicher frei ist.
1.3Die speicherzentrierte IT-Architektur und ihre Vorteile
Speichernetze
Speichernetze lösen die soeben geschilderten Einschränkungen der serverzentrierten IT-Architektur. Darüber hinaus bieten Speichernetze neue Möglichkeiten, Daten zu verwalten. Die Idee von Speichernetzen ist, die Kabel zwischen Server und Speicher durch ein Netz zu ersetzen, das zusätzlich zu dem bereits existierenden Rechnernetz (LAN) installiert und überwiegend für den Datenaustausch zwischen Servern und Speichergeräten genutzt wird (Abb. 1–4).
Speicherzentrierte IT-Architektur
Im Gegensatz zur serverzentrierten IT-Architektur existiert Speicher in Speichernetzen völlig unabhängig von irgendwelchen Servern. Über das Speichernetz können mehrere Server direkt auf dasselbe Speichergerät zugreifen, ohne dass dabei zwangsläufig ein anderer Server involviert ist. Speichergeräte rücken damit in das Zentrum der IT-Architektur; Server hinge...