
eBook - ePub
Shared Memory Application Programming
Concepts and Strategies in Multicore Application Programming
Victor Alessandrini
This is a test
- 556 Seiten
- English
- ePUB (handyfreundlich)
- Über iOS und Android verfügbar
eBook - ePub
Shared Memory Application Programming
Concepts and Strategies in Multicore Application Programming
Victor Alessandrini
Angaben zum Buch
Buchvorschau
Inhaltsverzeichnis
Quellenangaben
Über dieses Buch
Shared Memory Application Programming presents the key concepts and applications of parallel programming, in an accessible and engaging style applicable to developers across many domains. Multithreaded programming is today a core technology, at the basis of all software development projects in any branch of applied computer science. This book guides readers to develop insights about threaded programming and introduces two popular platforms for multicore development: OpenMP and Intel Threading Building Blocks (TBB). Author Victor Alessandrini leverages his rich experience to explain each platform's design strategies, analyzing the focus and strengths underlying their often complementary capabilities, as well as their interoperability.
The book is divided into two parts: the first develops the essential concepts of thread management and synchronization, discussing the way they are implemented in native multithreading libraries (Windows threads, Pthreads) as well as in the modern C++11 threads standard. The second provides an in-depth discussion of TBB and OpenMP including the latest features in OpenMP 4.0 extensions to ensure readers' skills are fully up to date. Focus progressively shifts from traditional thread parallelism to modern task parallelism deployed by modern programming environments. Several chapter include examples drawn from a variety of disciplines, including molecular dynamics and image processing, with full source code and a software library incorporating a number of utilities that readers can adapt into their own projects.
- Designed to introduce threading and multicore programming to teach modern coding strategies for developers in applied computing
- Leverages author Victor Alessandrini's rich experience to explain each platform's design strategies, analyzing the focus and strengths underlying their often complementary capabilities, as well as their interoperability
- Includes complete, up-to-date discussions of OpenMP 4.0 and TBB
- Based on the author's training sessions, including information on source code and software libraries which can be repurposed
Häufig gestellte Fragen
Wie kann ich mein Abo kündigen?
Gehe einfach zum Kontobereich in den Einstellungen und klicke auf „Abo kündigen“ – ganz einfach. Nachdem du gekündigt hast, bleibt deine Mitgliedschaft für den verbleibenden Abozeitraum, den du bereits bezahlt hast, aktiv. Mehr Informationen hier.
(Wie) Kann ich Bücher herunterladen?
Derzeit stehen all unsere auf Mobilgeräte reagierenden ePub-Bücher zum Download über die App zur Verfügung. Die meisten unserer PDFs stehen ebenfalls zum Download bereit; wir arbeiten daran, auch die übrigen PDFs zum Download anzubieten, bei denen dies aktuell noch nicht möglich ist. Weitere Informationen hier.
Welcher Unterschied besteht bei den Preisen zwischen den Aboplänen?
Mit beiden Aboplänen erhältst du vollen Zugang zur Bibliothek und allen Funktionen von Perlego. Die einzigen Unterschiede bestehen im Preis und dem Abozeitraum: Mit dem Jahresabo sparst du auf 12 Monate gerechnet im Vergleich zum Monatsabo rund 30 %.
Was ist Perlego?
Wir sind ein Online-Abodienst für Lehrbücher, bei dem du für weniger als den Preis eines einzelnen Buches pro Monat Zugang zu einer ganzen Online-Bibliothek erhältst. Mit über 1 Million Büchern zu über 1.000 verschiedenen Themen haben wir bestimmt alles, was du brauchst! Weitere Informationen hier.
Unterstützt Perlego Text-zu-Sprache?
Achte auf das Symbol zum Vorlesen in deinem nächsten Buch, um zu sehen, ob du es dir auch anhören kannst. Bei diesem Tool wird dir Text laut vorgelesen, wobei der Text beim Vorlesen auch grafisch hervorgehoben wird. Du kannst das Vorlesen jederzeit anhalten, beschleunigen und verlangsamen. Weitere Informationen hier.
Ist Shared Memory Application Programming als Online-PDF/ePub verfügbar?
Ja, du hast Zugang zu Shared Memory Application Programming von Victor Alessandrini im PDF- und/oder ePub-Format sowie zu anderen beliebten Büchern aus Computer Science & Hardware. Aus unserem Katalog stehen dir über 1 Million Bücher zur Verfügung.
Information
Thema
Computer ScienceThema
HardwareChapter 1
Introduction and Overview
Abstract
Basic concepts and features of current computing platforms and environments are reviewed, preparing the ground for the central subject of this book, the controlled execution of several independent, asynchronous flows of instructions. Particular attention is paid to architectural issues having an impact on efficient software development, like the hierarchical organization of memory accesses, the impact of the ongoing multicore evolution of computing architectures, or the increasing impact of heterogeneous computing systems involving, in addition to the standard processing units, and innovative architectures like Intel Xeon Phi or GPU accelerators.
Keywords
Processes
SMP platform
Distributed memory platform
Memory system
External devices
1.1 Processes and Threads
Multithreading is today a mandatory software technology for taking full advantage of the capabilities of modern computing platforms of any kind, and a good understanding of the overall role and impact of threads, as well as the place they take in the computational landscape, is useful before embarking on a detailed discussion of this subject.
We are all permanently running standalone applications in all kinds of computing devices: servers, laptops, smartphones, or multimedia devices. All the data processing devices available in our environment have a master piece of software—the operating system (OS)—that controls and manages the device, running different applications at the user’s demands. A standalone application corresponds to a process run by the operating system. A process can be seen as a black box that owns a number of protected hardware and software resources; namely, a block of memory, files to read and write data, network connections to communicate eventually with other processes or devices, and, last but not least, code in the form of a list of instructions to be executed. Process resources are protected in the sense that no other process running on the same platform can access and use them. A process has also access to one or several central processing units—called CPU for short—providing the computing cycles needed to execute the application code.
One of the most basic concepts we will be using is the notion of concurrency, which is about two or more activities happening at the same time. Concurrency is a natural part of life: we all can, for example, walk and talk at the same time. In computing platforms, we speak of concurrency when several different activities can advance and make progress at the same time, rather than one after the other. This is possible because CPU cycles are not necessarily exclusively owned by one individual process. The OS can allocate CPU cycles to several different processes at the same time (a very common situation in general). It allocates, for example, successive time slices on a given CPU to different processes, thereby providing the illusion that the processes are running simultaneously. This is called multitasking. In this case, processes are not really running simultaneously but, at a human time scale, they advance together, which is why it is appropriate to speak about concurrent execution.
One special case of concurrency happens when there are sufficient CPU resources so that they do not need to be shared: each activity has exclusive ownership of the CPU resource it needs. In this optimal case, we may speak of parallel execution. But remember that parallel execution is just a special case of concurrency.
As stated, a process incorporates a list of instructions to be executed by the CPU. An ordinary sequential application consists of a single thread of execution, i.e., a single list of instructions that are bound to be executed on a single CPU. In a C-C++ programming environment, this single thread of execution is coded in the main() function. In a multithreaded application, a process integrates several independent lists of instructions that execute asynchronously on one or several CPU. Chapter 3 shows in detail how the different multithreading programming environments allow the initial main thread to install other execution streams, equivalent to main() but totally disconnected from it. Obviously, multithreading is focused on enhancing the process performance, either by isolating independent tasks that can be executed concurrently by different threads, or by activating several CPUs to share the work needed to perform a given parallel task.
1.2 Overview of Computing Platforms
A computing platform consists essentially of one or more CPUs and a memory block where the application data and code are stored. There are also peripheral devices to communicate with the external world, like DVD drives, hard disks, graphic cards, or network interfaces.
Figure 1.1 shows a schematic view of a personal computer. For the time being, think of the processor chip as corresponding to a single CPU, which used to be the case until the advent of the multicore evolution, circa 2004, when processor chips started to integrate several CPUs. The data processing performance of the simple platform shown in Figure 1.1 depends basically on the performance of the CPU, i.e., the rate at which the CPU is able to execute the basic instructions of the instruction set. But it also depends critically on the rate at which data can be moved to and from the memory: a fast processor is useless if it has no data to work upon.
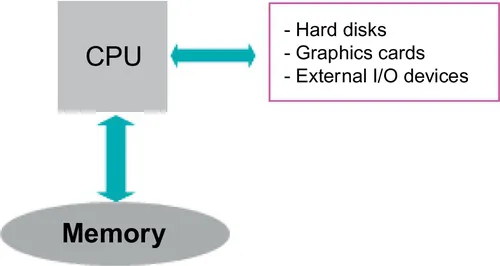
Figure 1.1 Schematic architecture of a simple computing platform.
The rate at which the CPU is able to execute basic instructions is determined by the internal processor clock speed. Typically, the execution of a basic low-level instruction may take up to a few cycles, depending on the instruction complexity. The clock frequency is directly related to the peak performance, which is the theoretical performance in an ideal context in which processor cycles are not wasted. The original Intel 8086 processor in the late 70 s ran at 5 MHz (i.e., 5 millions of cycles per second). Today, processors run at about 3 GHz (3000 millions of cycles per second). This represents a 600× increase in frequency, achieved in just over 20 years.
Memory performance is a completely different issue. The time T needed to move to or from memory a data block of N bytes is given by:

where L is the latency, namely, the access time needed to trigger the transfer, and B is the bandwidth, namely, the speed at which data is moved once the transfer has started.
It is important to keep in mind that, in the case we are considering, moving data from memory to the processor or vice versa:
• The bandwidth is a property of the network connecting the two devices. Bandwidths are controlled by network technologies.
• The latency is an intrinsic property of the memory device.
It turns out that memory latencies are very difficult to tame. At the time of the 8086, memory latencies were close to the processor clock, so it was possible to feed the processor at a rate guaranteeing roughly the execution of one instruction per clock cycle. But memory latencies have not decreased as dramatically as processor frequencies have increased. Today, it takes a few hundreds of clock cycles to trigger a memory access. Therefore, in ordinary memory bound applications the processors tend to starve, and typically their sustained performances are a small fraction (about 10%) of the theoretical peak performance promised by the processor frequency. As we will see again and again, this is the crucial issue for application performance, and lots of ingenuity in the design of hardware and system software has gone into taming this bottleneck, which is called the memory wall.
1.2.1 Shared Memory Multiprocessor Systems
The next step in computing platform complexity are the so-called symmetric multiprocessor (SMP) systems, where a network interconnect links a number of processor chips to a common, shared memory block. Symmetric means that all CPUs have an equivalent status with respect to memory accesses. Memory is shared, and all CPUs can access the whole common memory address space. They are shown in Figure 1.2.
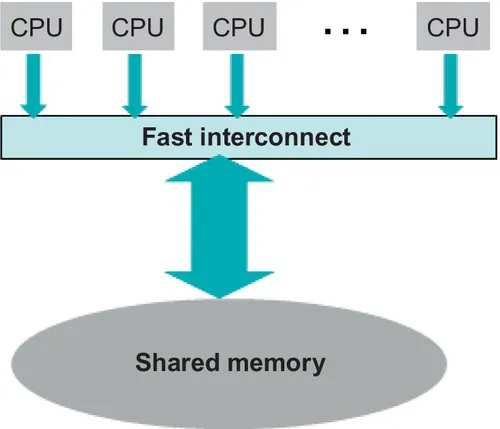
Figure 1.2 Symmetric multiprocessor shared memory platform.
For reasons that will be discussed in Chapter 7, coherency in shared memory accesses prevents SMP platforms from scaling to very large numbers of CPUs. Today, shared memory systems do not exceed 60 CPUs. This limit will perhaps increase in the future, but it is bound to remain limited. These systems are very useful as medium-size servers. They can perform efficient multitasking by allocating different applications on different CPUs. On the other hand, a multithreaded application can benefit from the availability of a reasonable number of CPUs to enhance the process performance.
However, note that the SMP computing platforms are not perfectly symmetric. The reason ...
Inhaltsverzeichnis
- Cover image
- Title page
- Table of Contents
- Copyright
- Preface
- Biography
- Acknowledgments
- Chapter 1: Introduction and Overview
- Chapter 2: Introducing Threads
- Chapter 3: Creating and Running Threads
- Chapter 4: Thread-Safe Programming
- Chapter 5: Concurrent Access to Shared Data
- Chapter 6: Event Synchronization
- Chapter 7: Cache Coherency and Memory Consistency
- Chapter 8: Atomic Types and Operations
- Chapter 9: High-Level Synchronization Tools
- Chapter 10: OpenMP
- Chapter 11: Intel Threading Building Blocks
- Chapter 12: Further Thread Pools
- Chapter 13: Molecular Dynamics Example
- Chapter 14: Further Data Parallel Examples
- Chapter 15: Pipelining Threads
- Chapter 16: Using the TBB Task Scheduler
- Annex A: Using the Software
- Annex B: C++ Function Objects and Lambda Expressions
- Bibliography
- Index
Zitierstile für Shared Memory Application Programming
APA 6 Citation
Alessandrini, V. (2015). Shared Memory Application Programming ([edition unavailable]). Elsevier Science. Retrieved from https://www.perlego.com/book/1809484/shared-memory-application-programming-concepts-and-strategies-in-multicore-application-programming-pdf (Original work published 2015)
Chicago Citation
Alessandrini, Victor. (2015) 2015. Shared Memory Application Programming. [Edition unavailable]. Elsevier Science. https://www.perlego.com/book/1809484/shared-memory-application-programming-concepts-and-strategies-in-multicore-application-programming-pdf.
Harvard Citation
Alessandrini, V. (2015) Shared Memory Application Programming. [edition unavailable]. Elsevier Science. Available at: https://www.perlego.com/book/1809484/shared-memory-application-programming-concepts-and-strategies-in-multicore-application-programming-pdf (Accessed: 15 October 2022).
MLA 7 Citation
Alessandrini, Victor. Shared Memory Application Programming. [edition unavailable]. Elsevier Science, 2015. Web. 15 Oct. 2022.