1.1 Introduction—The Senses
Of the five senses—vision, hearing, smell, taste, and touch—vision is undoubtedly the one that we have come to depend upon above all others, and indeed the one that provides most of the data we receive. Not only do the input pathways from the eyes provide megabits of information at each glance, but the data rate for continuous viewing probably exceed 10 megabits per second. However, much of this information is redundant and is compressed by the various layers of the visual cortex, so that the higher centers of the brain have to interpret abstractly only a small fraction of the data. Nonetheless, the amount of information the higher centers receive from the eyes must be at least two orders of magnitude greater than all the information they obtain from the other senses.
Another feature of the human visual system is the ease with which interpretation is carried out. We see a scene as it is—trees in a landscape, books on a desk, widgets in a factory. No obvious deductions are needed, and no overt effort is required to interpret each scene. In addition, answers are effectively immediate and are normally available within a tenth of a second. Just now and again some doubt arises—for example, a wire cube might be “seen” correctly or inside out. This and a host of other optical illusions are well known, although for the most part we can regard them as curiosities—irrelevant freaks of nature. Somewhat surprisingly, it turns out that illusions are quite important, since they reflect hidden assumptions that the brain is making in its struggle with the huge amounts of complex visual data it is receiving. We have to bypass this topic here (though it surfaces now and again in various parts of this book). However, the important point is that we are for the most part unaware of the complexities of vision. Seeing is not a simple process: it is just that vision has evolved over millions of years, and there was no particular advantage in evolution giving us any indication of the difficulties of the task. (If anything, to have done so would have cluttered our minds with worthless information and quite probably slowed our reaction times in crucial situations.)
Thus, ignorance of the process of human vision abounds. However, being by nature inventive, the human species is now trying to get machines to do much of its work. For the simplest tasks there should be no particular difficulty in mechanization, but for more complex tasks the machine must be given our prime sense, that of vision. Efforts have been made to achieve this, sometimes in modest ways, for well over 30 years. At first such tasks seemed trivial, and schemes were devised for reading, for interpreting chromosome images, and so on. But when such schemes were challenged with rigorous practical tests, the problems often turned out to be more difficult. Generally, researchers react to their discovery that apparent “trivia” are getting in the way by intensifying their efforts and applying great ingenuity. This was certainly the case with some early efforts at vision algorithm design. Hence, it soon became plain that the task is a complex one, in which numerous fundamental problems confront the researcher, and the ease with which the eye can interpret scenes has turned out to be highly deceptive.
Of course, one way in which the human visual system surpasses the machine is that the brain possesses some 1010 cells (or neurons), some of which have well over 10,000 contacts (or synapses) with other neurons. If each neuron acts as a type of microprocessor, then we have an immense computer in which all the processing elements can operate concurrently. Probably, the largest single man-made computer still contains less than 100 million processing elements, so the majority of the visual and mental processing tasks that the eye-brain system can perform in a flash have no chance of being performed by present-day man-made systems. Added to these problems of scale is the problem of how to organize such a large processing system and how to program it. Clearly, the eye-brain system is partly hard-wired by evolution, but there is also an interesting capability to program it dynamically by training during active use. This need for a large parallel processing system with the attendant complex control problems clearly illustrates that machine vision must indeed be one of the most difficult intellectual problems to tackle.
So what are the problems involved in vision that make it apparently so easy for the eye and yet so difficult for the machine? In the next few sections we attempt to answer this question.
1.2 The Nature of Vision
1.2.1 The Process of Recognition
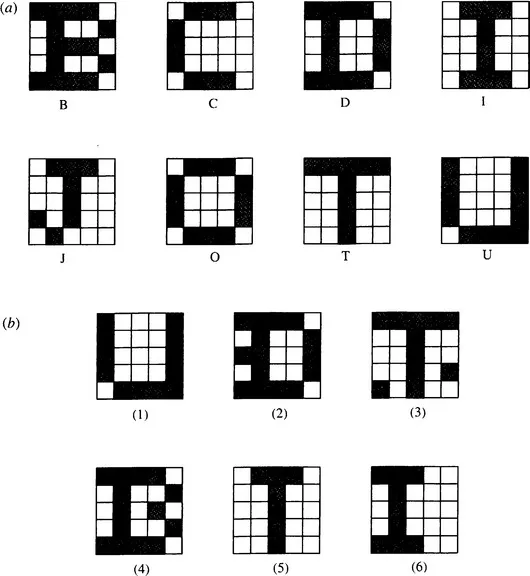
This section illustrates the intrinsic difficulties of implementing machine vision, starting with an extremely simple example—that of character recognition. Consider the set of patterns shown in Fig. 1.1a. Each pattern can be considered as a set of 25 bits of information, together with an associated class indicating its interpretation. In each case, imagine a computer learning the patterns and their classes by rote. Then any new pattern may be classified (or “recognized”) by comparing it with this previously learned “training set,” and assigning it to the class of the nearest pattern in the training set. Clearly, test pattern (1) (Fig. 1.1b) will be allotted to class U on this basis. Chapter 24 shows that this method is a simple form of the nearest-neighbor approach to pattern recognition.
The scheme we have outlined in Fig. 1.1 seems straightforward and is indeed highly effective, even being able to cope with situations where distortions of the test patterns occur or where noise is present: this is illustrated by test patterns (2) and (3). However, this approach is not always foolproof. First, in some situations distortions or noise is so excessive that errors of interpretation arise. Second, patterns may not be badly distorted or subject to obvious noise and, yet, are misinterpreted: this situation seems much more serious, since it indicates an unexpected limitation of the technique rather than a reasonable result of noise or distortion. In particular, these problems arise where the test pattern is displaced or erroneously oriented relative to the appropriate training set pattern, as with test pattern (6).
As will be seen in Chapter 24, a powerful principle is operative here, indicating why the unlikely limitation we have described can arise: it is simply that there are insufficient training set patterns and that those that are present are insufficiently representative of what will arise during tests. Unfortunately, this presents a major difficulty inasmuch as providing enough training set patterns incurs a serious storage problem, and an even more serious search problem when patterns are tested. Furthermore, it is easy to see that these problems are exacerbated as patterns become larger and more real. (Obviously, the examples of Fig. 1.1 are far from having enough resolution even to display normal type fonts.) In fact, a combinatorial explosion1 takes place. Forgetting for the moment that the patterns of Fig. 1.1 have familiar shapes, let us temporarily regard them as random bit patterns. Now the number of bits in these N × N patterns is N2, and the number of possible patterns of this size is 2N: even in a case where N = 20, remembering all these patterns and their interpretations would be impossible on any practical machine, and searching systematically through them would take impracticably long (involving times of the order of the age of the universe). Thus, it is not only impracticable to consider such brute-force means of solving the recognition problem, but also it is effectively impossible theoretically. These considerations show that other means are required to tackle the problem.
1.2.2 Tackling the Recognition Problem
An obvious means of tackling the recognition problem is to normalize the images in some way. Clearly, normalizing the position and orientation of any 2-D picture object would help considerably. Indeed, this would reduce the number ofdegrees of freedom by three. Methods for achieving this involve centralizing the objects—arranging that their centroids are at the center of the normalized image—and making their major axes (deduced by moment calculations, for example) vertical or horizontal. Next, we can make use of the order that is known to be present in the image—and here it may be noted that very few patterns of real interest are indistinguishable from random dot patterns. This approach can be taken further: if patterns are to be nonrandom, isolated noise points may be eliminated. Ultimately, all these methods help by making the test pattern closer to a restricted set of training set patterns (although care has to be taken to process the training set patterns initially so that they are representative of the processed test patterns).
It is useful to consider character recognition further. Here we can make additional use of what is known about the structure of characters—namely, that they consist of limbs of roughly constant width. In that case, the width carries no useful information, so the patterns can be thinned to stick figures (called skeletons—see Chapter 6). Then, hopefully, there is an even greater chance that the test patterns will be similar to appropriate training set patterns (Fig. 1.2). This process can be regarded as another instance of reducing the number of degrees of freedom in the image, and hence of helping to minimize the combinatorial explosion—or, from a practical point of view, to minimize the size of the training set necessary for effective recognition.
Next, consider a rather different way of looking at the problem. Recognition is necessarily a problem of discrimination—that is, of discriminating between patterns of different classes. In practice, however, considering the natural variation of patterns, including the effects of noise and distortions (or even the effects of breakages or occlusions), there is also a problem of generalizing over patterns of the same class. In practical problems a tension exists between the need to discriminate and the need to generalize. Nor is this a fixed situation. Even for the character recognition task, some classes are so close to others (n’s and h’s will be similar) that less general...