
eBook - ePub
Data Architecture: A Primer for the Data Scientist
A Primer for the Data Scientist
W.H. Inmon,Daniel Linstedt,Mary Levins
This is a test
- 431 Seiten
- English
- ePUB (handyfreundlich)
- Über iOS und Android verfügbar
eBook - ePub
Data Architecture: A Primer for the Data Scientist
A Primer for the Data Scientist
W.H. Inmon,Daniel Linstedt,Mary Levins
Angaben zum Buch
Buchvorschau
Inhaltsverzeichnis
Quellenangaben
Über dieses Buch
Over the past 5 years, the concept of big data has matured, data science has grown exponentially, and data architecture has become a standard part of organizational decision-making. Throughout all this change, the basic principles that shape the architecture of data have remained the same. There remains a need for people to take a look at the "bigger picture" and to understand where their data fit into the grand scheme of things.
Data Architecture: A Primer for the Data Scientist, Second Edition addresses the larger architectural picture of how big data fits within the existing information infrastructure or data warehousing systems. This is an essential topic not only for data scientists, analysts, and managers but also for researchers and engineers who increasingly need to deal with large and complex sets of data. Until data are gathered and can be placed into an existing framework or architecture, they cannot be used to their full potential. Drawing upon years of practical experience and using numerous examples and case studies from across various industries, the authors seek to explain this larger picture into which big data fits, giving data scientists the necessary context for how pieces of the puzzle should fit together.
- New case studies include expanded coverage of textual management and analytics
- New chapters on visualization and big data
- Discussion of new visualizations of the end-state architecture
Häufig gestellte Fragen
Wie kann ich mein Abo kündigen?
Gehe einfach zum Kontobereich in den Einstellungen und klicke auf „Abo kündigen“ – ganz einfach. Nachdem du gekündigt hast, bleibt deine Mitgliedschaft für den verbleibenden Abozeitraum, den du bereits bezahlt hast, aktiv. Mehr Informationen hier.
(Wie) Kann ich Bücher herunterladen?
Derzeit stehen all unsere auf Mobilgeräte reagierenden ePub-Bücher zum Download über die App zur Verfügung. Die meisten unserer PDFs stehen ebenfalls zum Download bereit; wir arbeiten daran, auch die übrigen PDFs zum Download anzubieten, bei denen dies aktuell noch nicht möglich ist. Weitere Informationen hier.
Welcher Unterschied besteht bei den Preisen zwischen den Aboplänen?
Mit beiden Aboplänen erhältst du vollen Zugang zur Bibliothek und allen Funktionen von Perlego. Die einzigen Unterschiede bestehen im Preis und dem Abozeitraum: Mit dem Jahresabo sparst du auf 12 Monate gerechnet im Vergleich zum Monatsabo rund 30 %.
Was ist Perlego?
Wir sind ein Online-Abodienst für Lehrbücher, bei dem du für weniger als den Preis eines einzelnen Buches pro Monat Zugang zu einer ganzen Online-Bibliothek erhältst. Mit über 1 Million Büchern zu über 1.000 verschiedenen Themen haben wir bestimmt alles, was du brauchst! Weitere Informationen hier.
Unterstützt Perlego Text-zu-Sprache?
Achte auf das Symbol zum Vorlesen in deinem nächsten Buch, um zu sehen, ob du es dir auch anhören kannst. Bei diesem Tool wird dir Text laut vorgelesen, wobei der Text beim Vorlesen auch grafisch hervorgehoben wird. Du kannst das Vorlesen jederzeit anhalten, beschleunigen und verlangsamen. Weitere Informationen hier.
Ist Data Architecture: A Primer for the Data Scientist als Online-PDF/ePub verfügbar?
Ja, du hast Zugang zu Data Architecture: A Primer for the Data Scientist von W.H. Inmon,Daniel Linstedt,Mary Levins im PDF- und/oder ePub-Format sowie zu anderen beliebten Büchern aus Betriebswirtschaft & Business Intelligence. Aus unserem Katalog stehen dir über 1 Million Bücher zur Verfügung.
Information
Chapter 1.1
An Introduction to Data Architecture
Abstract
Corporate data include everything found in the corporation in the way of data. The most basic division of corporate data is by structured data and unstructured data. As a rule, there are much more unstructured data than structured data. Unstructured data have two basic divisions—repetitive data and nonrepetitive data. Big data is made up of unstructured data. Nonrepetitive big data has a fundamentally different form than repetitive unstructured big data. In fact, the differences between nonrepetitive big data and repetitive big data are so large that they can be called the boundaries of the “great divide.” The divide is so large; many professionals are not even aware that there is this divide. As a rule, nonrepetitive big data has MUCH greater business value than repetitive big data.
Keywords
Structured data; Unstructured data; Corporate data; Repetitive data; Nonrepetitive data; Business value; The great divide of data; Big data
Data architecture is about the larger picture of data and how it fits together in a typical organization. The natural starting point for looking at the big picture of how data fit together in a corporation begins naturally enough with all the data in the corporation.
Fig. 1.1.1 depicts symbolically all the data—of every kind—in the corporation.

Fig. 1.1.1 depicts every kind of data found in the corporation. It depicts data generated by running transactions. It depicts e-mail. It depicts telephone conversations. It depicts data found in personal computers. It depicts metering data. It depicts office memos. It depicts contracts, safety reports, and time sheets. It depicts pay ledgers.
In a word, if it is data and it is in the corporation, it is depicted by the bar shown in Fig. 1.1.1.
Subdividing Data
There are many ways to subdivide the data shown in Fig. 1.1.1. The way that is shown is only one of many ways data can be understood.
One way to understand the data found in the corporation is to look at structured data and nonstructured data. Fig. 1.1.2 shows this subdivision of data.

Structured data are data that are well defined. Structured data are typically repetitive. The same structure of data recurs repeatedly. The only difference between one occurrence of data and another is in the contents of the data. As a simple example of structured data, there are records of the sale of a good—an “SKU”—made by a retailer. Each time Walmart makes a sale the item sold, the amount of the sale, the tax paid, and the date and location of the sale are recorded. In a day's time, Walmart will create many records of the sale of many items. From a structural standpoint, the sale of one item will be identical to the sale of another item. The data are called “structured” because of the similarity of the structure of the records.
The high degree of structure and definition of the records make the records easy to handle inside a database management system.
However, structured records are hardly the only kind of data in the corporation. In fact, structured data typically represent only a small fraction of the data found in the corporation. The other kind of data found in the corporation is called unstructured data.
Repetitive/Nonrepetitive Unstructured Data
There are two basic kinds of unstructured data in the corporation—repetitive unstructured data and nonrepetitive unstructured data.
Fig. 1.1.3 depicts the different kinds of unstructured data in the corporation.
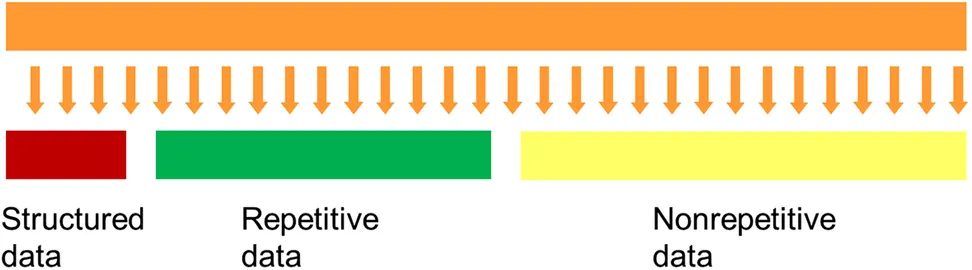
A typical form of repetitive unstructured data in the corporation might be the data generated by an analog machine. For example, a farmer has a machine that reads the identification of railroad cars as the railroad cars pass through the farmer's property. Trains pass through the property night and day. The electronic eye reads and records the passage of each car on the track.
Nonrepetitive unstructured data are data that are nonrepetitive, such as e-mails. Each e-mail can be long or short. The e-mail can be in English or Spanish (or some other languages.) The author of the e-mail can say anything that he/she pleases. It is only a pure accident if the contents of any e-mail are identical to the contents of any other e-mail. And there are many forms of nonrepetitive unstructured data. There are voice recordings, there are contracts, there are customer feedback messages, etc.
Because of its irregular form, unstructured data do not fit well with standard database management systems.
The Great Divide of Data
It is not obvious at all, but the dividing line in unstructured data between unstructured repetitive data and unstructured nonrepetitive data is very significant. In fact, the dividing line between unstructured repetitive data and unstructured nonrepetitive data is so important that the division can be called the “great divide” of data.
Fig. 1.1.4 shows the great divide of data.

It is hardly obvious why there should be this great divide of data. But there are some very good reasons for the divide:
- Repetitive data usually have very limited business value, wh...