
eBook - ePub
Data Science und Advanced Analytics für alle
Eine einfache Einführung in die Welt der künstlichen Intelligenz
This is a test
- 352 Seiten
- German
- ePUB (handyfreundlich)
- Über iOS und Android verfügbar
eBook - ePub
Data Science und Advanced Analytics für alle
Eine einfache Einführung in die Welt der künstlichen Intelligenz
Angaben zum Buch
Buchvorschau
Inhaltsverzeichnis
Quellenangaben
Über dieses Buch
Eine einfache Einführung in Data Science und Advanced Analytics für alle Interessierten, unabhängig von Wissensstand und Ausbildung. Wenn Sie verstehen wollen, was Künstliche Intelligenz ist, welche Fragen mit Data Science beantwortet werden können, wie die solchen Systemen zugrundeliegende Technologie funktioniert und was damit möglich ist (und vielleicht noch wichtiger – was nicht), dann haben Sie genau den richtigen Text vor sich.
Häufig gestellte Fragen
Gehe einfach zum Kontobereich in den Einstellungen und klicke auf „Abo kündigen“ – ganz einfach. Nachdem du gekündigt hast, bleibt deine Mitgliedschaft für den verbleibenden Abozeitraum, den du bereits bezahlt hast, aktiv. Mehr Informationen hier.
Derzeit stehen all unsere auf Mobilgeräte reagierenden ePub-Bücher zum Download über die App zur Verfügung. Die meisten unserer PDFs stehen ebenfalls zum Download bereit; wir arbeiten daran, auch die übrigen PDFs zum Download anzubieten, bei denen dies aktuell noch nicht möglich ist. Weitere Informationen hier.
Mit beiden Aboplänen erhältst du vollen Zugang zur Bibliothek und allen Funktionen von Perlego. Die einzigen Unterschiede bestehen im Preis und dem Abozeitraum: Mit dem Jahresabo sparst du auf 12 Monate gerechnet im Vergleich zum Monatsabo rund 30 %.
Wir sind ein Online-Abodienst für Lehrbücher, bei dem du für weniger als den Preis eines einzelnen Buches pro Monat Zugang zu einer ganzen Online-Bibliothek erhältst. Mit über 1 Million Büchern zu über 1.000 verschiedenen Themen haben wir bestimmt alles, was du brauchst! Weitere Informationen hier.
Achte auf das Symbol zum Vorlesen in deinem nächsten Buch, um zu sehen, ob du es dir auch anhören kannst. Bei diesem Tool wird dir Text laut vorgelesen, wobei der Text beim Vorlesen auch grafisch hervorgehoben wird. Du kannst das Vorlesen jederzeit anhalten, beschleunigen und verlangsamen. Weitere Informationen hier.
Ja, du hast Zugang zu Data Science und Advanced Analytics für alle von Denis Krutikov im PDF- und/oder ePub-Format sowie zu anderen beliebten Büchern aus Matemáticas & Matemáticas general. Aus unserem Katalog stehen dir über 1 Million Bücher zur Verfügung.
Information
Kapitel 1 Muster in den Daten
Wir beginnen unsere Reise ins Reich von Advanced Analytics und Data Science mit drei sehr einfachen Beispielen aus der Marketing-Welt, genauer aus dem Bereich des Zielgruppenmarketings, der auch „Analytisches Customer Relationship Management“ genannt wird. Diese Beispiele sind stark vereinfacht und haben deshalb wenig praktische Relevanz. Sie dienen allein dem Zweck, die ersten von den in der Einführung angekündigten Grundideen zu lernen.
Historisch gesehen war Marketing einer der ersten Wirtschaftsbereiche, in die die Methoden der Advanced Analytics den Einzug fanden. Eine der wichtigsten Fragestellungen im Marketing ist: wie kann man bestimmte Produkte gezielt anwerben? Also, wie kann man geschickt die Zielgruppen eingrenzen, so dass man keine großen Streuverluste hat? Der Hintergrund für die Frage ist die Tatsache, dass die pauschalen Werbungsaktionen oft einfach zu teuer sind. Wenn z.B. eine große Bank einen Kredit bewirbt, ist es keine gute Idee, einfach alle Kunden diesbezüglich anzuschreiben, denn dafür müsste man Millionen von Briefen drucken und verschicken, mit entsprechenden Kosten. Es wäre viel besser, irgendwie die potenziellen Kreditnehmer1 relativ sicher zu identifizieren und nur diese Kunden zu kontaktieren. In der Praxis würde das die Auflage der Aktion von mehreren Millionen auf vielleicht Hunderttausend reduzieren. Und das ist in der Tat möglich, wenn man die Methoden der Advanced Analytics einsetzt.
Wir betrachten nun das erste von den oben angekündigten Beispielen. Stellen wir uns vor, dass wir in den letzten 2 Jahren eine bestimmte Anzahl an Kunden für einen Kredit angeworben haben. Und wir wissen, welche dieser Kunden tatsächlich einen Kredit abgeschlossen und welche ihn abgelehnt haben. Außerdem kennen wir von allen diesen Kunden das Einkommen und wie weit entfernt vom Stadtzentrum sie wohnen. Mit diesen Informationen können wir die folgende Abbildung erzeugen.
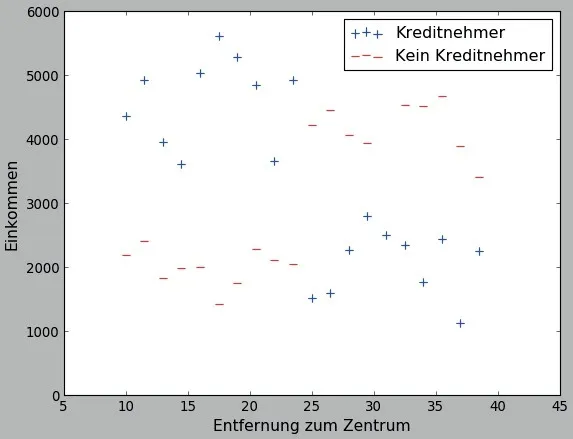
• Jedes blaue Pluszeichen steht hier für einen Kreditnehmer und jedes rote Minuszeichen steht für einen „Kreditablehner“. Die Positionen der Pluszeichen und Minuszeichen werden durch das Einkommen des Kunden und seine Entfernung zum Stadtzentrum bestimmt. Der „blaue“ Kunde in der Mitte hat z.B. das Einkommen von ca. 3500 Euro und seine Entfernung zum Stadtzentrum beträgt ca. 23 km.
Zur Erinnerung: unser Endziel besteht darin, für alle Kunden eine Vorhersage zu machen, ob sie potenziell zu den Kreditnehmern gehören oder nicht. Das heißt, wir wollen wissen, ob ein Kunde ein „Plus“ oder ein „Minus“ ist. Um das entscheiden zu können, wäre es sicherlich hilfreich zu sehen, was Pluszeichen von Minuszeichen unterscheidet. Dafür reicht es, einfach auf die Abbildung zu schauen, denn die gesamte Information, über die wir verfügen, ist dort zu sehen. Die Frage ist also, wo liegen die Unterschiede zwischen „Pluszeichen“ und „Minuszeichen“ auf dem Bild? Nun, man sieht mit dem bloßen Auge, dass alle Pluszeichen entweder links oben oder rechts unten liegen und alle Minuszeichen entweder rechts oben oder links unten. Um diesen Unterschied noch deutlicher zu machen, können wir die Pluszeichen von den Minuszeichen durch folgende zwei gerade Linien trennen (s. die Abbildung unten).
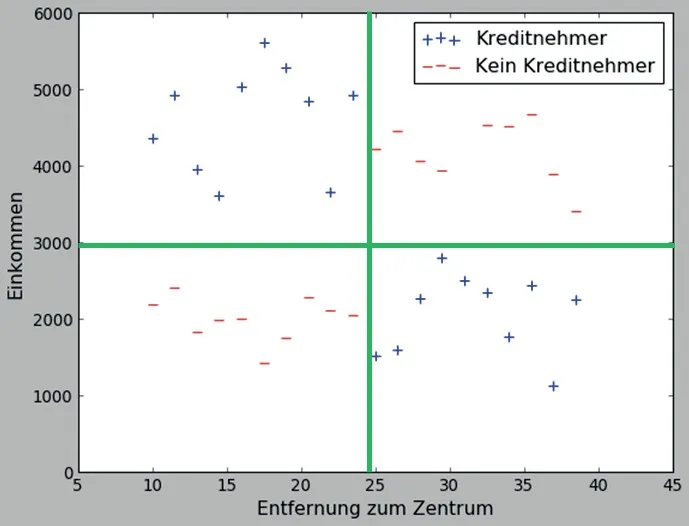
Und schon sind wir uns dem ersten Grundkonzept begegnet: der Trennung der Daten. Im Großen und Ganzen ist es das, worum es bei allen Klassifikationsaufgaben wie dieser geht – um die Trennung der Daten nach Klassen bzw. Gruppen. (Bei Klassifikationen versucht man eine von mehreren Klassen vorherzusagen. Im einfachsten Fall gibt es nur zwei Klassen, wie in unserem Beispiel „Kreditnehmer“ und „Kein Kreditnehmer“. Mehr zu Klassifikationen später.)
Die grünen Linien im Diagramm oben trennen also die Pluszeichen von den Minuszeichen. Diese Trennlinien haben auch einen anderen Namen: Entscheidungsgrenze (decision boundary). Der Grund dafür ist, dass man solche Trennlinien auf natürliche Weise als Basis für Entscheidungsregeln nutzen kann. Dafür machen wir zuerst Folgendes: wir schauen uns die Bereiche an, in die die Trennlinien unser Bild aufgeteilt haben. Und wir markieren die Bereiche, in denen man hauptsächlich „Pluszeichen“ findet, um sie von den „Minusbereichen“ zu unterscheiden.
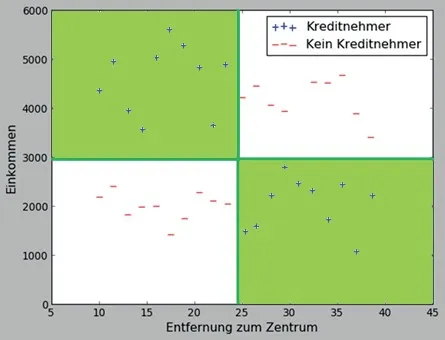
Wir können z.B. diese Bereiche färben, wie auf dem Diagramm oben zu sehen ist. Solche Bereiche werden Entscheidungsbereiche genannt (decision regions).
Hier haben wir die zwei „Plusbereiche“ mit der hellgrünen Farbe markiert. Jetzt kann man für neue Punkte mit der unbekannten Klassifikation (also für Kunden, von denen wir zuerst mal nicht wissen, ob sie potentielle Kreditnehmer sind) eine einfache Regel aufstellen: die Punkte, die im hellgrünen Bereich landen, werden zu „Pluszeichen“ (und gelten dann als potentielle Kreditnehmer), wohingegen die neuen Punkte im weißen Bereich zu „Minuszeichen“ werden.
Auf der folgenden Abbildung haben wir zwei neue Punkte (als schwarze kleine Kreise zu sehen): der linke steht für einen Kunden mit einem Einkommen von ca. 1500 Euro und mit einer Entfernung zum Zentrum von ca. 15 km. Dieser Kreis befindet sich in einem weißen Bereich. Also wird dieser Kunde nicht als ein potenzieller Kreditnehmer angesehen. Dagegen wird der rechte Punkt (der rechte schwarze Kreis), der für einen Kunden mit dem Einkommen von ca. 2300 Euro und mit einer Entfernung zum Zentrum von ca. 40 km steht und sich in einem hellgrünen Bereich befindet, als ein potentieller Kreditnehmer betrachtet.
Es ist nicht schwer, in diesem Fall die Entscheidungsregeln auch explizit aufzuschreiben. Sie sehen dann wie folgt aus:
• Wenn Entfernung zum Zentrum>25 km und Einkommen <3000 Euro, dann ist es ein potenzieller Kreditnehmer
• Wenn Entfernung zum Zentrum <25 km und Einkommen>3000 Euro, dann ist es ebenfalls ein potenzieller Kreditnehmer
• In anderen Fällen ist es kein potenzieller Kreditnehmer

Also, was ist hier passiert? Wir haben die Daten analysiert (in diesem einfachen Fall mit dem bloßen Auge), ein Muster bzw. eine Gesetzmäßigkeit in den Daten entdeckt und darauf basierend ein einfaches Regelwerk erstellt, das uns erlaubt, Vorhersagen für die zuvor unbekannten Fälle zu machen. Hier sehen wir schon das Grundparadigma von Advanced Analytics bzw. Data Science, das man knapp in der folgenden Form darstellen kann:

Bevor wir ein weiteres Beispiel betrachten, noch eine kleine Bemerkung bezüglich der gerade erstellten Regel für Kreditnehmer: natürlich ergibt diese Regel nicht sehr viel Sinn, aber das hat schlicht damit zu tun, dass die Verteilung der Punkte künstlich und nur für illustrative Zwecke erzeugt wurde. In der Praxis würden die „Pluszeichen“ und „Minuszeichen“ einer ganz anderen, viel komplexeren Verteilung folgen, womit eine realistische Regel auch ganz anders aussehen würde.
Jetzt schauen wir uns ein zweites Beispiel an. Bleiben wir im Marketingbereich und betrachten eine andere klassische Aufgabe: Kündigungsprävention. Fast jede große Firma (z.B. eine Bank, ein Autohersteller oder ein Telekommunikationsunternehmen) hat mit dem Problem zu kämpfen, dass manche ihrer Kunden zu der Konkurrenz abwandern. Entsprechend versucht man, diese Abwanderung zumindest teilweise abzuschwächen, indem man die Kunden dazu motiviert, in der Firma zu bleiben. Und genau wie in unserem ersten Beispiel ist es zu teuer, Antikündigungsmaßnahmen auf alle Kunden anzuwenden. Man braucht wiederum ein gezielteres Vorgehen, sprich es ist notwendig, zuerst einmal potenzielle Kündiger zu identifizieren.
Stellen wir uns vor, dass wir genau wie im ersten Beispiel über gewisse Daten aus der Vergangenheit verfügen. Konkret wissen wir, welche Kunden in den letzten 2 Jahren die Firma verlassen haben, und wir kennen Einkommen und Kundenbeziehungsdauer für alle Kunden (also für gegangene und für gebliebene). Die Verteilung der entsprechenden Punkte ist auf dem nächsten Diagramm zu sehen, wobei wir mit Pluszeichen die Kündiger markieren und mit Minuszeichen die gebliebenen Kunden.

Jetzt geht es wieder darum, eine Entscheidungsregel für die Vorhersage aufzubauen. Wie im ersten Beispiel brauchen wir dafür eine oder mehrere Trennlinien, um die Daten zu separieren. Hier wären die vertikalen bzw. horizontalen Linien offensichtlich keine so gute Wahl, aber es ist recht einfach, die Daten durch eine einzige „schiefe“ gerade Linie zu trennen wie auf dem folgenden Diagramm (es gibt offensichtlich mehrere mögliche Trennlinien in diesem Fall, die aber alle sehr ähnlich verlaufen).
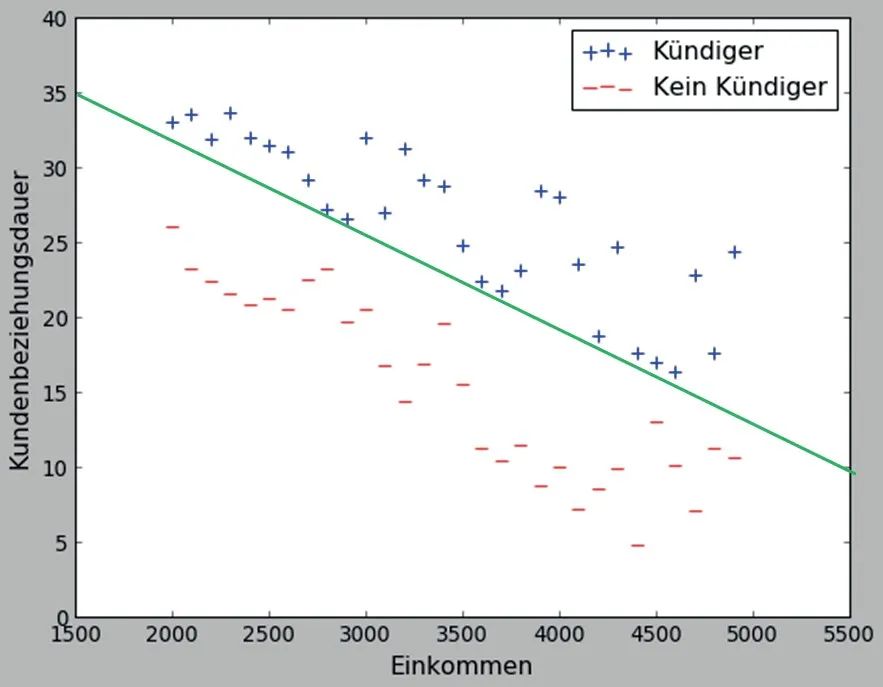
Wir sehen außerdem, dass alle Pluszeichen oberhalb der Trennlinie liegen. Wir markieren diesen „Plusbereich“ wieder mit der hellgrünen Farbe, wie auf der folgenden Abbildung zu sehen ist. Jetzt kann man die Entscheidungsregel so formulieren: alle Punkte in dem hellgrünen Bereich werden als potenzielle Kün...
Inhaltsverzeichnis
- Cover
- Titelblatt
- Urheberrechte
- Inhalt
- Einführung
- Konventionen und Abkürzungen
- Kapitel 1 Muster in den Daten
- Kapitel 2 Was ist was in der Welt von Data Science
- Kapitel 3 Typen der Machine Learning - Aufgaben
- Kapitel 4 Wie lernen Maschinen
- Kapitel 5 Wie gut ist ein Modell?
- Kapitel 6 Datenmusik und Preprocessing
- Kapitel 7 Ein bisschen Geschichte
- Kapitel 8 Ensemble-Modelle
- Kapitel 9 Wie lernen Maschinen, Teil 2
- Kapitel 10 Kampf gegen Overfitting, Hyperparameter
- Kapitel 11 Klassifikationen in der Praxis. Scoring.
- Kapitel 12 Neuronale Netze und Deep Learning36
- Kapitel 13 Machine Learning auf Textdaten
- Kapitel 14 Dimensionality Reduction
- Zum Schluss
- Im Buch erklärte ML-Verfahren
- Stichwortverzeichnis
- Literaturverzeichnis