
Deep Learning with R for Beginners
Design neural network models in R 3.5 using TensorFlow, Keras, and MXNet
Mark Hodnett, Joshua F. Wiley, Yuxi (Hayden) Liu, Pablo Maldonado
- 612 Seiten
- English
- ePUB (handyfreundlich)
- Über iOS und Android verfügbar
Deep Learning with R for Beginners
Design neural network models in R 3.5 using TensorFlow, Keras, and MXNet
Mark Hodnett, Joshua F. Wiley, Yuxi (Hayden) Liu, Pablo Maldonado
Über dieses Buch
Explore the world of neural networks by building powerful deep learning models using the R ecosystem
Key Features
- Get to grips with the fundamentals of deep learning and neural networks
- Use R 3.5 and its libraries and APIs to build deep learning models for computer vision and text processing
- Implement effective deep learning systems in R with the help of end-to-end projects
Book Description
Deep learning finds practical applications in several domains, while R is the preferred language for designing and deploying deep learning models.
This Learning Path introduces you to the basics of deep learning and even teaches you to build a neural network model from scratch. As you make your way through the chapters, you'll explore deep learning libraries and understand how to create deep learning models for a variety of challenges, right from anomaly detection to recommendation systems. The book will then help you cover advanced topics, such as generative adversarial networks (GANs), transfer learning, and large-scale deep learning in the cloud, in addition to model optimization, overfitting, and data augmentation. Through real-world projects, you'll also get up to speed with training convolutional neural networks (CNNs), recurrent neural networks (RNNs), and long short-term memory networks (LSTMs) in R.
By the end of this Learning Path, you'll be well versed with deep learning and have the skills you need to implement a number of deep learning concepts in your research work or projects.
This Learning Path includes content from the following Packt products:
- R Deep Learning Essentials - Second Edition by Joshua F. Wiley and Mark Hodnett
- R Deep Learning Projects by Yuxi (Hayden) Liu and Pablo Maldonado
What you will learn
- Implement credit card fraud detection with autoencoders
- Train neural networks to perform handwritten digit recognition using MXNet
- Reconstruct images using variational autoencoders
- Explore the applications of autoencoder neural networks in clustering and dimensionality reduction
- Create natural language processing (NLP) models using Keras and TensorFlow in R
- Prevent models from overfitting the data to improve generalizability
- Build shallow neural network prediction models
Who this book is for
This Learning Path is for aspiring data scientists, data analysts, machine learning developers, and deep learning enthusiasts who are well versed in machine learning concepts and are looking to explore the deep learning paradigm using R. A fundamental understanding of R programming and familiarity with the basic concepts of deep learning are necessary to get the most out of this Learning Path.
Häufig gestellte Fragen
Information
Text Generation using Recurrent Neural Networks
- Sequence prediction: Given , predict the next element of the sequence,

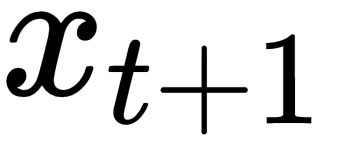
- Sequence classification: Given , predict a category or label for it

- Sequence generation: Given , generate a new element of the sequence,

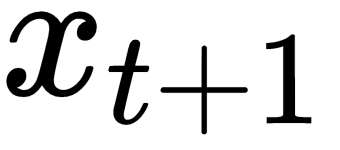
- Sequence to sequence prediction: Given , generate an equivalent sequence,


What is so exciting about recurrent neural networks?
- Produce consistent markup text (opening and closing tags, recognizing timestamp-like data)
- Write Wikipedia articles with references, and create URLs from non-existing addresses, by learning what a URL should look like
- Create credible-looking scientific papers from LaTeX
- One-to-one: Supervised learning, for instance, text classification
- One-to-many: Given an input text, generate a summary (a sequence of words with important information)
- Many-to-one: Sentiment analysis in text
- Many-to-many: Machine translation
But what is a recurrent neural network, really?

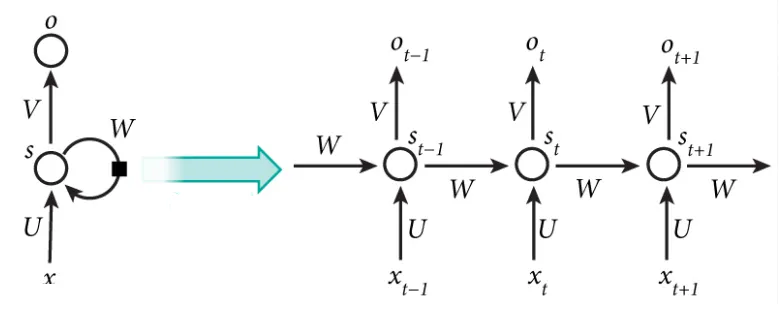
Inhaltsverzeichnis
- Title Page
- Copyright and Credits
- About Packt
- Contributors
- Preface
- Getting Started with Deep Learning
- Training a Prediction Model
- Deep Learning Fundamentals
- Training Deep Prediction Models
- Image Classification Using Convolutional Neural Networks
- Tuning and Optimizing Models
- Natural Language Processing Using Deep Learning
- Deep Learning Models Using TensorFlow in R
- Anomaly Detection and Recommendation Systems
- Running Deep Learning Models in the Cloud
- The Next Level in Deep Learning
- Handwritten Digit Recognition using Convolutional Neural Networks
- Traffic Signs Recognition for Intelligent Vehicles
- Fraud Detection with Autoencoders
- Text Generation using Recurrent Neural Networks
- Sentiment Analysis with Word Embedding
- Other Books You May Enjoy