
- 812 páginas
- Spanish
- ePUB (apto para móviles)
- Disponible en iOS y Android
eBook - ePub
Aprender PHP, MySQL y JavaScript
Descripción del libro
Si quiere crear sitios web interactivos apoyados en bases de datos con la potente combinación de tecnologías de código abierto y estándares web, incluso sin tener conocimientos básicos de HTML, ha llegado al libro indicado.
Gracias a esta guía práctica, abordará la programación web dinámica con la última versión de las principales herramientas del momento: PHP, MySQL, CSS, HTML5 y las bibliotecas clave de jQuery. Asimismo, aprenderá a utilizar estas tecnologías en su conjunto y accederá a valiosas prácticas de programación web.
-Explorar MySQL desde la estructura de la base de datos hasta consultas complejas
-Utilizar la extensión MySQLi, la interfaz MySQL mejorada de PHP
-Crear páginas web dinámicas que se adaptan al usuario
-Gestionar las cookies y las sesiones, y conservar un alto grado de seguridad
-Mejorar el lenguaje JavaScript con las bibliotecas jQuery y jQuery Mobile
-Utilizar las llamadas con AJAX para la comunicación en segundo plano entre el navegador y el servidor
-Diseñar páginas web con las habilidades que adquirirá en CSS2 y CSS3
-Implementar las características de HTML5, incluidas la geolocalización, el audio, el vídeo y el elemento lienzo
-Reformatear sus sitios web con aplicaciones web para móviles
Al final del libro, descubrirá cómo unir todos los temas tratados para crear un sitio de redes sociales completamente funcional, adecuado para navegadores tanto de equipos de escritorio como de dispositivos móviles. Además, en la parte inferior de la primera página del libro encontrará el código de acceso que le permitirá acceder de forma gratuita a los contenidos adicionales en www.marcombo.info.
Robin Nixon es periodista de las TI y especialista en las tecnologías presentadas en este libro. Ha trabajado y ha escrito sobre ordenadores desde 1980, es autor de cientos de artículos y libros sobre informática y ha desarrollado numerosos sitios web con herramientas de código abierto.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Información
Capítulo 1
Introducción al contenido dinámico de la web
La World Wide Web es una red en constante evolución que ha ido mucho más lejos de lo que fue su concepción a principios de la década de 1990, cuando se creó con el propósito de resolver un problema específico. Los experimentos más avanzados del CERN (Laboratorio Europeo de Física de Partículas, ahora más conocido como el operador del Gran Colisionador de Hadrones) generaban ingentes cantidades de datos, hasta tal punto que resultaba difícil hacerlos llegar a los científicos de todo el mundo que participaban en las investigaciones.
En aquel momento, Internet ya estaba en funcionamiento, y a la red estaban conectados varios cientos de miles de ordenadores, por lo que Tim Berners-Lee (miembro del CERN) ideó un método para navegar entre ellos mediante una estructura de hiperenlaces, la cual llegó a conocerse como Protocolo de Transferencia de Hipertexto, o HTTP. También creó un lenguaje de marcado llamado Hypertext Markup Language, o HTML. Para integrarlos, desarrolló el primer navegador y el primer servidor web.
Hoy en día estamos acostumbrados a disponer de estas herramientas, pero en aquellas fechas el concepto era revolucionario. Hasta aquel momento, la conectividad más avanzada que tenían a su alcance los usuarios que disponían de un módem en casa era la de realizar una llamada y conectarse a un tablón de anuncios, alojado en un ordenador, a través del que el usuario podía comunicarse e intercambiar datos solo con otros usuarios de ese servicio. Por consiguiente, era necesario que el usuario fuera miembro de muchos sistemas de tablones de anuncios para poder comunicarse electrónicamente de manera efectiva con sus colegas y amigos.
Pero la contribución de Berners-Lee cambió todo aquello de golpe y, a mediados de la década de 1990, había tres grandes navegadores gráficos que competían por la captación de 5 millones de usuarios. Pronto se hizo evidente, sin embargo, que algo faltaba. Es cierto que las páginas de texto con hipervínculos que nos llevan a otras páginas fue un concepto brillante, pero los resultados no reflejaban el potencial de los ordenadores y de Internet para satisfacer de forma inmediata las necesidades particulares de cada usuario con contenidos que cambian dinámicamente. Utilizar la web era una experiencia árida y poco atractiva, incluso aunque hubiéramos tenido ¡texto en movimiento y GIF animados! Los carritos de la compra, los motores de búsqueda y las redes sociales han alterado sin duda la forma en la que utilizamos la web. En este capítulo, echaremos un breve vistazo a los diversos componentes que forman la web y al software que ayuda a hacer de su uso una experiencia rica y dinámica.
 | Es necesario empezar a utilizar algunos acrónimos de forma más o menos inmediata. He tratado de explicarlos claramente antes de hacer uso de ellos, pero no hay que preocuparse demasiado por lo que representan o lo que significan sus nombres, porque los detalles los trataremos a medida que vayamos avanzando en el contenido del libro. |
HTTP y HTML: los conceptos básicos de Berners-Lee
HTTP es un estándar de comunicación que gobierna las peticiones y respuestas que se envían entre el navegador, que se ejecuta en el ordenador del usuario final, y el servidor web.
El servidor tiene como función aceptar una petición del cliente e intentar responderle en un archivo de manera efectiva, por lo general mediante la entrega de la página web que ha solicitado. Este es el motivo por el que se utiliza el término servidor. El equivalente por naturaleza del servidor es el cliente, término que se aplica tanto al navegador web como al ordenador en el que se ejecuta.
Entre el cliente y el servidor puede haber otros equipos, como enrutadores, proxies, pasarelas, etc. Cumplen diferentes funciones para garantizar que las solicitudes y las respuestas se transfieran correctamente entre el cliente y el servidor. Habitualmente se utiliza Internet como medio para enviar esta información. Algunos de estos dispositivos intermedios también pueden ayudar a acelerar la respuesta de Internet, almacenan páginas o información de forma local en lo que se denomina una caché y, a continuación, sirven este contenido a los clientes directamente desde la caché, en lugar de tener que transferirlo desde el servidor de origen.
Un servidor web normalmente puede manejar múltiples conexiones de forma simultánea, y cuando no está comunicándose con un cliente, se dedica a escuchar para detectar una conexión entrante. Cuando llega una conexión, el servidor envía una respuesta para confirmar su recepción.
Procedimiento de solicitud/respuesta
En su nivel más básico, el proceso de solicitud/respuesta consiste en una pregunta que formula el navegador web al servidor web para que este le envíe una página web, y el servidor le envía la página. El navegador se encarga de mostrar la página (ver Figura 1-1).
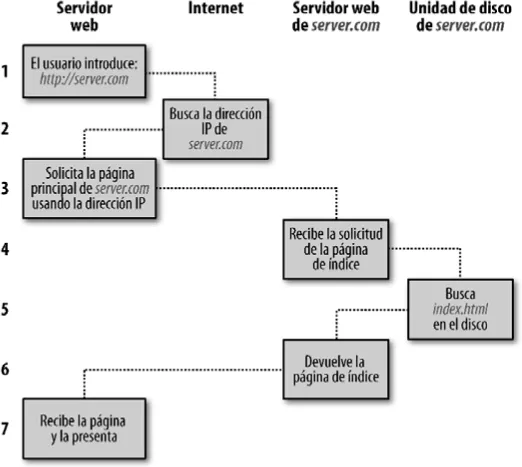
Figura 1-1. Secuencia básica de solicitud/respuesta entre cliente/servidor
Los pasos en la secuencia de solicitud y respuesta son los siguientes:
1. Introduces http://server.com en la barra de direcciones del navegador.
2. El navegador busca la dirección del protocolo Internet (IP) de server.com.
3. El navegador emite la solicitud de la página de inicio de server.com.
4. La solicitud viaja por Internet y llega al servidor web de server.com.
5. El servidor web, una vez recibida la petición, busca la página web en su disco.
6. El servidor web recupera la página de su disco y la envía al navegador.
7. El navegador muestra la página web.
Para una página web normal, este proceso también se lleva a cabo para cada objeto dentro de la página, ya sea un gráfico, un vídeo integrado o un archivo flash, o incluso una plantilla CSS.
En el paso 2, observamos que el navegador busca la dirección IP de server.com. Cada máquina conectada a Internet tiene una dirección IP (incluido nuestro ordenador) pero generalmente accedemos a los servidores web utilizando un nombre, como por ejemplo google.com. Como probablemente ya sabes, el navegador consulta un servicio adicional de Internet llamado Servicio de Nombres de Dominio (DNS) para encontrar la dirección IP asociada al servidor y, posteriormente, la utiliza para comunicarse con el ordenador.
Para páginas web dinámicas, el procedimiento es un poco más complicado, porque puede ser una mezcla de PHP y MySQL. Por ejemplo, supongamos que hacemos clic sobre la imagen de un impermeable. A continuación, PHP creará una petición usando el lenguaje de base de datos estándar, SQL (muchos de cuyos comandos aprenderás en este libro) y la enviará al servidor MySQL. El servidor MySQL devolverá la información del impermeable que hemos seleccionado, el código PHP lo encerrará todo en HTML, y el servidor lo enviará al navegador (ver la Figura 1-2).
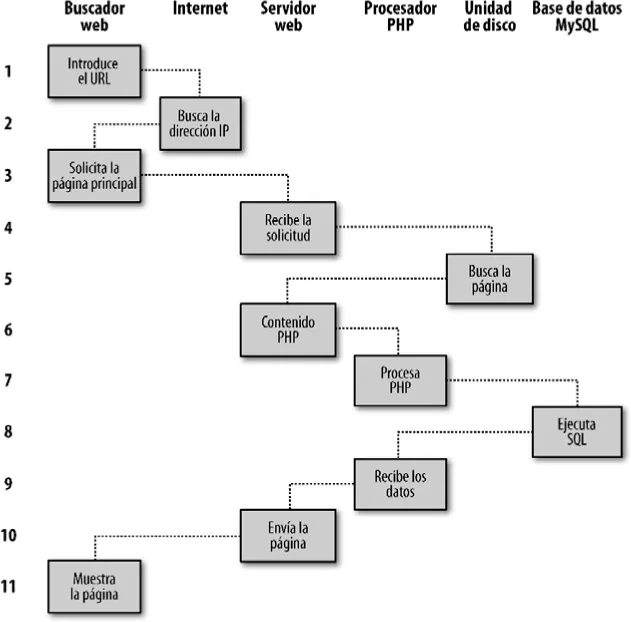
Figura 1-2. Secuencia dinámica de solicitud/respuesta entre cliente/servidor
Los pasos son los siguientes:
1. Tecleas http://server.com en la barra de direcciones del navegador.
2. El navegador busca la dirección IP de server.com.
3. El navegador envía una solicitud de la página de inicio del servidor web, a esa dirección.
4. La solicitud viaja por Internet y llega al servidor web server.com.
5. El servidor web, una vez recibida la petición, recupera la página de inicio de su disco duro.
6. Con la página de inicio ahora en memoria, el servidor web se da cuenta de que es un archivo que incorpora PHP y pasa la página al intérprete de PHP.
7. El intérprete de PHP ejecuta el código PHP.
8. Algunos de los códigos PHP contienen sentencias SQL, que el intérprete PHP ahora pasa al motor de base de datos MySQL.
9. La base de datos MySQL devuelve los resultados de las sentencias al intérprete PHP.
10. El intérprete PHP devuelve los resultados del código PHP ejecutado, junto con el archivo de la base de datos MySQL, al servidor web.
11. El servidor web devuelve la página al programa cliente que la ha solicitado, y este la muestra al usuario.
Aunque es útil conocer este proceso para saber cómo funcionan los tres elementos juntos, en la práctica no es necesario que nos preocupemos por ellos, porque todos se ejecutan automáticamente.
Las páginas HTML, devueltas al navegador en cada uno de los ejemplos, pueden contener código en JavaScript, que interpretará localmente el cliente, el cual podría iniciar otra petición, de la misma manera que lo podrían hacer los objetos integrados o las imágenes.
Ventajas de PHP, MySQL, JavaScript, CSS y HTML5
Al principio de este capítulo, introduje el mundo de la Web 1.0, pero no había transcurrido mucho tiempo cuando se dieron prisa en crear la Web 1.1, que incorporaba el desarrollo de mejoras en el navegador como Java, JavaScript, JScript (una variante con pocos cambios de JavaScript de Microsoft) y ActiveX. Por lo que respecta al servidor, se estaban realizando progresos en la interfaz de pasarela común (CGI) con lenguajes de scripting (secuencia de comandos) como Perl (una alternativa al lenguaje PHP) y scripts, insertando el contenido de un archivo (o la salida de la ejecución de un programa local) en otro, de forma dinámica.
Una vez calmados los ánimos, tres tecnologías principales se diferenciaban de las demás. Aunque Perl seguía siendo un lenguaje de programación con un gran n...
Índice
- Cubierta
- Título
- Créditos
- Contenido
- Prefacio
- 1. Introducción al contenido dinámico de la web
- 2. Configuración de un servidor de desarrollo
- 3. Introducción a PHP
- 4. Expresiones y control de flujo en PHP
- 5. Funciones y objetos en PHP
- 6. Matrices en PHP
- 7. PHP práctico
- 8. Introducción a MySQL
- 9. Dominio de MySQL
- 10. Acceso a MySQL mediante PHP
- 11. Gestión de formularios
- 12. Cookies, sesiones y autenticación
- 13. Exploración de JavaScript
- 14. Expresiones y control de flujo en JavaScript
- 15. Funciones, objetos y matrices de JavaScript
- 16. Validación de JavaScript y PHP y tratamiento de errores
- 17. Uso de comunicaciones asíncronas
- 18. Introducción a CSS
- 19. CSS avanzado con CSS3
- 20. Acceso a CSS desde JavaScript
- 21. Introducción a jQuery
- 22. Introducción a jQuery Mobile
- 23. Introducción a HTML5
- 24. El lienzo HTML5
- 25. Audio y vídeo en HTML5
- 26. Otras características de HTML5
- 27. Todo junto
- A. Soluciones a las preguntas de los capítulos
- B. Recursos en línea
- C. Palabras vacías en FULLTEXT de MySQL
- D. Funciones MySQL
- E. Selectores, objetos y métodos en jQuery
Preguntas frecuentes
Sí, puedes cancelar tu suscripción en cualquier momento desde la pestaña Suscripción en los ajustes de tu cuenta en el sitio web de Perlego. La suscripción seguirá activa hasta que finalice el periodo de facturación actual. Descubre cómo cancelar tu suscripción
No, los libros no se pueden descargar como archivos externos, como los PDF, para usarlos fuera de Perlego. Sin embargo, puedes descargarlos en la aplicación de Perlego para leerlos sin conexión en el móvil o en una tableta. Descubre cómo descargar libros para leer sin conexión
Perlego ofrece dos planes: Essential y Complete
- El plan Essential es ideal para los estudiantes y los profesionales a los que les gusta explorar una amplia gama de temas. Accede a la biblioteca Essential, con más de 800 000 títulos de confianza y superventas sobre negocios, crecimiento personal y humanidades. Incluye un tiempo de lectura ilimitado y la voz estándar de «Lectura en voz alta».
- Complete: perfecto para los estudiantes avanzados y los investigadores que necesitan un acceso completo sin ningún tipo de restricciones. Accede a más de 1,4 millones de libros sobre cientos de temas, incluidos títulos académicos y especializados. El plan Complete también incluye funciones avanzadas como la lectura en voz alta prémium y el asistente de investigación.
Somos un servicio de suscripción de libros de texto en línea que te permite acceder a toda una biblioteca en línea por menos de lo que cuesta un libro al mes. Con más de un millón de libros sobre más de 990 categorías, ¡tenemos todo lo que necesitas! Descubre nuestra misión
Busca el símbolo de lectura en voz alta en tu próximo libro para ver si puedes escucharlo. La herramienta de lectura en voz alta lee el texto en voz alta por ti, resaltando el texto a medida que se lee. Puedes pausarla, acelerarla y ralentizarla. Obtén más información sobre la lectura en voz alta
¡Sí! Puedes usar la aplicación de Perlego en dispositivos iOS y Android para leer cuando y donde quieras, incluso sin conexión. Es ideal para cuando vas de un lado a otro o quieres acceder al contenido sobre la marcha.
Ten en cuenta que no será compatible con los dispositivos que se ejecuten en iOS 13 y Android 7 o en versiones anteriores. Obtén más información sobre cómo usar la aplicación
Ten en cuenta que no será compatible con los dispositivos que se ejecuten en iOS 13 y Android 7 o en versiones anteriores. Obtén más información sobre cómo usar la aplicación
Sí, puedes acceder a Aprender PHP, MySQL y JavaScript de Robin Nixon en formato PDF o ePUB, así como a otros libros populares de Ciencia de la computación y Lenguajes de programación. Tenemos más de un millón de libros disponibles en nuestro catálogo para que explores.