![]()
Chapter 1: Introduction to Data Science
Chapter Overview
This chapter introduces the main concepts of data science, a scientific field involving computer science, mathematics, statistics, domain knowledge, and communication. These are the main goals of this chapter:
- Explain the most important tasks and roles associated with the data science field.
- Explain how to apply data science to solve problems and improve business operations.
- Describe data science as a combination of different disciplines, such as computer science, mathematics and statistics, domain knowledge, and communications.
- Describe the skills related to mathematics and statistics and the role that they play in solving business problems through analytical modeling.
- Describe the skills related to computer science and the role that they play in solving business problems by supporting analytical models to be trained and deployed effectively.
- Describe the skills related to domain knowledge and the role that they play in solving business problems by adding value to data, models, and tactical and operational actions.
- Describe the skills related to communication and visualization and the role that they play in solving business problems by describing and explaining the solutions, model outcomes, and possible operational actions.
Data Science
Data science is not a single discipline. It comprises a series of different fields of expertise and skills, combining them to solve problems and to improve and optimize processes. Among several skills needed, the most important are mathematics and statistics, computer science, and domain knowledge.
Data scientists need mathematics and statistics to understand the data generated in the business scenario, to model this data to gain insights, or to classify or estimate future events. Mathematics and statistics are also needed to evaluate the models developed and assess how they fit to the problem and how they can be used to solve or improve a specific process.
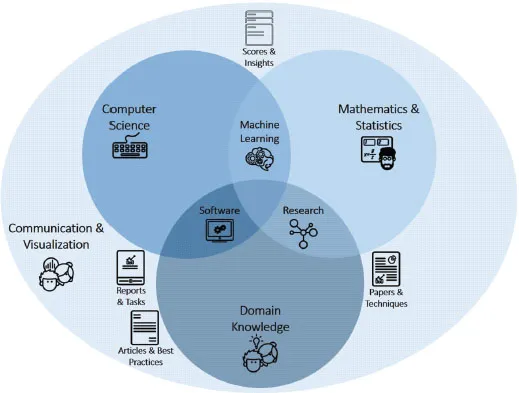
The infographic in Figure 1.1 refers to three main areas: mathematics and statistics, computer science, and domain knowledge. In the next sections, we will discuss these areas more in depth as well as other important areas such as communication, visualization, and hard and soft skills.
Figure 1.1: Expertise Areas in Data Science
The intersection of each of the three main areas is also very important. Machine learning is the field intersecting mathematics, statistics, and computer science. Machine learning is a branch of artificial intelligence based on the idea that systems can learn from data, identify patterns, recognize behaviors, and make decisions with minimal human intervention. It is a method of data analysis that automates data preparation, feature engineering, model training, and eventually model deployment. Machine learning allows data scientists to implement very complex models, such as neural networks or support vector machines, and an ensemble of simple models like decision trees, gradient boosting, and random forests. These complex models can capture very unusual relationships between the inputs (independent variables) and the target (dependent variable).
The intersection of mathematics, statistics, and domain knowledge is the research field. Research skills enable data scientists to apply new techniques in model building. This combination allows the development of very complex models that are more accurate and less dependent on the functional form. Research skills can speed up the development process especially when fewer assumptions are needed about the distribution of the target and the relationship of independent and dependent variables.
Software skills in data science usually refer to the intersection of computer science and domain knowledge. Software skills such as familiarity of open-source languages and other world-class software languages help data scientists create new models. The combination of computer science skills, software skills, and domain knowledge can help data scientists solve the business problem or improve a specific business process.
Mathematics and Statistics
Data scientists need to have strong mathematics and statistics skills to understand the data available, prepare the data needed to train a model, deploy multiple approaches in training and validating the analytical model, assess the model’s results, and finally explain and interpret the model’s outcomes. For example, data scientists need to understand the problem, explain the variability of the target, and conduct controlled tests to evaluate the effect of the values of parameters on the variation of the target values.
Data scientists need mathematics and statistical skills to summarize data to describe past events (known as descriptive statistics). These skills are needed to take the results of a sample and generalize them to a larger population (known as inferential statistics). Data scientists also need these skills to fit models where the response variable is known, and based on that, train a model to classify, predict, or estimate future outcomes (known as supervised modeling). These predictive modeling skills are some of the most widely used skills in data science.
Mathematics and statistics are needed when the business conditions don’t require a specific event, and there is no past behavior to drive the training of a supervised model. The learning process is based on discovering previously unknown patterns in the data set (known as unsupervised modeling). There is no target variable and the main goal is to raise some insights to help companies understand customers and business scenarios.
Data scientists need mathematics and statistics in the field of optimization. This refers to models aiming to find an optimal solution for a problem when constraints and resources exist. An objective function describes the possible solution, which involves the use of limited resources according to some constraints. Mathematics and statistics are also needed in the field of forecasting that is comprised of models to estimate future values in time series data. Based on past values over time, sales, or consumption, it is possible to estimate the future values according to the past behavior. Finally, mathematics and statistics are needed in the field of econometrics that applies statistical models to economic data, usually panel data or longitudinal data, to highlight empirical outcomes to economic relationships. These models are used to evaluate and develop econometric methods.
Mathematics and statistics are needed in the field of text mining. This is a very important field of analytics, particularly nowadays, because most of the data available is unstructured. Imagine all the social media applications, media content, books, articles, and news. There is a huge amount of information in unstructured, formatted data. Analyzing this type of data allows data scientists to infer correlations about topics, identify possible clusters of contents, search specific terms, and much more. Recognizing the sentiments of customers through text data on social media is a very hot topic called sentiment analysis.
Computer Science
The volume of available data today is unprecedented. And most important, the more information about a problem or scenario that is used, the more likely a good model is produced. Due to this data volume, data scientists do not develop models by hand. They need to have computer science skills to develop code, extract, prepare, transform, merge and store data, assess model results, and deploy models in production. All these steps are performed in digital environments. For example, with a tremendous increase in popularity, cloud-based computing is often used to capture data, create models, and deploy them into production environments.
At some point, data scientists need to know how to create and deploy models into the cloud and use containers or other technologies to allow them to port models to places where they are needed. Think about image recognition models using traffic cameras. It is not possible to capture the data and stream it from the camera to a central repository, train a model, and send it back to the camera to score an image. There are thousands of images being captured every second, and this data transfer would make the solution infeasible. The solution is to train the model based on a sample of data and export the model to the device itself, the camera. As the camera captures the images, the model scores and recognizes the image in real time. All these technologies are important to solve the problem. It is much more than just the analytical models, but it involves a series of processes to capture and process data, train models, generalize solutions, and deploy the results where they need to be. Image recognition models show the usefulness of containers, which packages up software code and all its dependencies so that the application runs quickly and reliably from one computing environment to another.
With today’s challenges, data scientists need to have strong computer science skills to deploy the model in different environments, by using distinct frameworks, languages, and storage. Sometimes it is necessary to create programs to capture data or even to expose outcomes. Programming and scripting languages are very important to accomplish these steps. There are several packages that enable data scientists to train supervised and unsupervised models, create forecasting and optimization models, or perform text analytics. New machine learning solutions to develop very complex models are created and released frequently, and to be up to date with new technologies, data scientists need to understand and use these all these new solutions.
Software to collect, prepare, and cleanse data are also very important. Any model is just a mapping of the input data and the event to be analyzed, classified, predicted, or estimated. If the data is poor quality or has a lot of inconsistences, the model will map this, and the outcomes will be inaccurate. Huge amounts of data should be stored in efficient repositories. Databases are needed to accomplish that, and data scientists are required to understand how the databases work. To process massive amounts of data, distributed environments are required. Often, data scientists need to understand how these massive parallel processing engines work. In addition to databases, there are lots of new structures of repositories to perform analytics.
In summary, there are too many skills to be learned and mastered. Much more than one human being can handle. Therefore, in most of the cases, data scientists will need to partner with someone else to perform all the activities needed to create...