
Python Data Science Essentials
A practitioner's guide covering essential data science principles, tools, and techniques, 3rd Edition
Alberto Boschetti, Luca Massaron
- 472 páginas
- English
- ePUB (apto para móviles)
- Disponible en iOS y Android
Python Data Science Essentials
A practitioner's guide covering essential data science principles, tools, and techniques, 3rd Edition
Alberto Boschetti, Luca Massaron
Información del libro
Gain useful insights from your data using popular data science tools
Key Features
- A one-stop guide to Python libraries such as pandas and NumPy
- Comprehensive coverage of data science operations such as data cleaning and data manipulation
- Choose scalable learning algorithms for your data science tasks
Book Description
Fully expanded and upgraded, the latest edition of Python Data Science Essentials will help you succeed in data science operations using the most common Python libraries. This book offers up-to-date insight into the core of Python, including the latest versions of the Jupyter Notebook, NumPy, pandas, and scikit-learn.
The book covers detailed examples and large hybrid datasets to help you grasp essential statistical techniques for data collection, data munging and analysis, visualization, and reporting activities. You will also gain an understanding of advanced data science topics such as machine learning algorithms, distributed computing, tuning predictive models, and natural language processing. Furthermore, You'll also be introduced to deep learning and gradient boosting solutions such as XGBoost, LightGBM, and CatBoost.
By the end of the book, you will have gained a complete overview of the principal machine learning algorithms, graph analysis techniques, and all the visualization and deployment instruments that make it easier to present your results to an audience of both data science experts and business users
What you will learn
- Set up your data science toolbox on Windows, Mac, and Linux
- Use the core machine learning methods offered by the scikit-learn library
- Manipulate, fix, and explore data to solve data science problems
- Learn advanced explorative and manipulative techniques to solve data operations
- Optimize your machine learning models for optimized performance
- Explore and cluster graphs, taking advantage of interconnections and links in your data
Who this book is for
If you're a data science entrant, data analyst, or data engineer, this book will help you get ready to tackle real-world data science problems without wasting any time. Basic knowledge of probability/statistics and Python coding experience will assist you in understanding the concepts covered in this book.
Preguntas frecuentes
Información
Data Munging
- The data science process (so that you'll know what is going on and what's next)
- Uploading data from a file
- Selecting the data you need
- Cleaning up any missing or wrong data
- Adding, inserting, and deleting data
- Grouping and transforming data to obtain new and meaningful information
- Managing to obtain a dataset matrix or an array to feed into the data science pipeline
The data science process
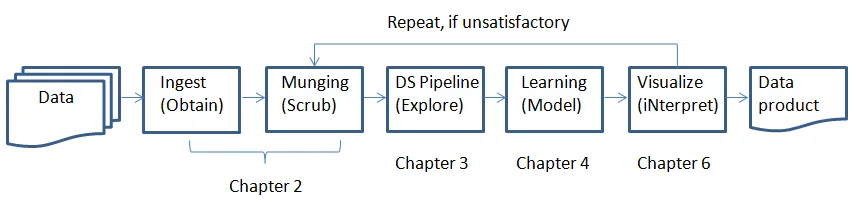
Data loading and preprocessing with pandas
Fast and easy data loading
Índice
- Title Page
- Copyright and Credits
- Packt Upsell
- Contributors
- Preface
- First Steps
- Data Munging
- The Data Pipeline
- Machine Learning
- Visualization, Insights, and Results
- Social Network Analysis
- Deep Learning Beyond the Basics
- Spark for Big Data
- Strengthen Your Python Foundations
- Other Books You May Enjoy