
Hands-On Reinforcement Learning for Games
Implementing self-learning agents in games using artificial intelligence techniques
Micheal Lanham
- 432 pages
- English
- ePUB (adapté aux mobiles)
- Disponible sur iOS et Android
Hands-On Reinforcement Learning for Games
Implementing self-learning agents in games using artificial intelligence techniques
Micheal Lanham
À propos de ce livre
Explore reinforcement learning (RL) techniques to build cutting-edge games using Python libraries such as PyTorch, OpenAI Gym, and TensorFlow
Key Features
- Get to grips with the different reinforcement and DRL algorithms for game development
- Learn how to implement components such as artificial agents, map and level generation, and audio generation
- Gain insights into cutting-edge RL research and understand how it is similar to artificial general research
Book Description
With the increased presence of AI in the gaming industry, developers are challenged to create highly responsive and adaptive games by integrating artificial intelligence into their projects. This book is your guide to learning how various reinforcement learning techniques and algorithms play an important role in game development with Python.
Starting with the basics, this book will help you build a strong foundation in reinforcement learning for game development. Each chapter will assist you in implementing different reinforcement learning techniques, such as Markov decision processes (MDPs), Q-learning, actor-critic methods, SARSA, and deterministic policy gradient algorithms, to build logical self-learning agents. Learning these techniques will enhance your game development skills and add a variety of features to improve your game agent's productivity. As you advance, you'll understand how deep reinforcement learning (DRL) techniques can be used to devise strategies to help agents learn from their actions and build engaging games.
By the end of this book, you'll be ready to apply reinforcement learning techniques to build a variety of projects and contribute to open source applications.
What you will learn
- Understand how deep learning can be integrated into an RL agent
- Explore basic to advanced algorithms commonly used in game development
- Build agents that can learn and solve problems in all types of environments
- Train a Deep Q-Network (DQN) agent to solve the CartPole balancing problem
- Develop game AI agents by understanding the mechanism behind complex AI
- Integrate all the concepts learned into new projects or gaming agents
Who this book is for
If you're a game developer looking to implement AI techniques to build next-generation games from scratch, this book is for you. Machine learning and deep learning practitioners, and RL researchers who want to understand how to use self-learning agents in the game domain will also find this book useful. Knowledge of game development and Python programming experience are required.
Foire aux questions
Informations
Section 1: Exploring the Environment
- Chapter 1, Understanding Rewards-Based Learning
- Chapter 2, Monte Carlo Methods
- Chapter 3, Dynamic Programming and the Bellman Equation
- Chapter 4, Temporal Difference Learning
- Chapter 5, Exploring SARSA
Understanding Rewards-Based Learning
– OpenAI Co-founder and Chief Scientist, Ilya Sutskever
- Understanding rewards-based learning
- Introducing the Markov decision process
- Using value learning with multi-armed bandits
- Exploring Q-learning with contextual bandits
Technical requirements
Understanding rewards-based learning

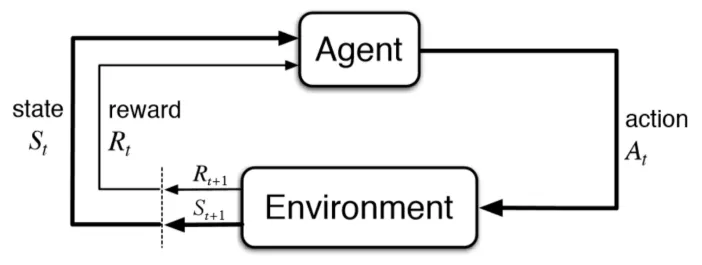
An RL system
The elements of RL
- The policy: A policy represents the decision and planning process of the agent. The policy is what decides the actions the agent will take during a step.
- The reward function: The reward function determines what amount of reward an agent receives after completing a series of actions or an action. Generally, a reward is given to an agent externally but, as we will see, there are internal reward systems as well.
- The value function: A value function determines the value of a state over the long term. Determining the value of a state is fundamental to RL and our first exercise will be determining state values.
- The model: A model represents the environment in full. In the case of a game...
Table des matières
- Title Page
- Copyright and Credits
- Dedication
- About Packt
- Contributors
- Preface
- Section 1: Exploring the Environment
- Understanding Rewards-Based Learning
- Dynamic Programming and the Bellman Equation
- Monte Carlo Methods
- Temporal Difference Learning
- Exploring SARSA
- Section 2: Exploiting the Knowledge
- Going Deep with DQN
- Going Deeper with DDQN
- Policy Gradient Methods
- Optimizing for Continuous Control
- All about Rainbow DQN
- Exploiting ML-Agents
- DRL Frameworks
- Section 3: Reward Yourself
- 3D Worlds
- From DRL to AGI
- Other Books You May Enjoy