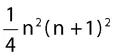Du neurone, composant fondamental du cerveau, on sait à peu près tout. De l'information mentale qu'il traite, on ne sait presque rien. Sous quelle forme « matérielle » et selon quelle organisation interne notre cerveau range-t-il ses visages connus, ses poèmes préférés et ses numéros de téléphone ? De quelle manière les restitue-t-il à la demande ? Ces questions ayant trait à l'information mentale relèvent moins de la biologie et de la neuroanatomie que de la théorie de l'information, formulée à l'origine par des spécialistes des télécommunications et du codage. Cet ouvrage très abordable apporte une première réponse concrète, mathématiquement cohérente et biologiquement plausible, sur la manière dont le réseau neural fixe et remémore ses éléments de connaissance. S'y mêlent, en une théorie originale, neurones et graphes, codes correcteurs d'erreurs et colonnes corticales, « cliques » neurales et autres « tournois », en quête des algorithmes de notre cerveau. Les perspectives de développement offertes par cette théorie et par le modèle de mémoire cérébrale entièrement numérique auquel elle conduit sont nombreuses et prometteuses, en neurosciences comme dans le champ de l'intelligence artificielle. Claude Berrou, professeur à Télécom Bretagne et membre de l'Académie des sciences, est à l'origine des « turbocodes », codes correcteurs d'erreurs utilisés dans la téléphonie mobile. Ses travaux sur le traitement distribué de l'information et le codage l'ont amené à jeter un regard nouveau sur le fonctionnement cérébral. Vincent Gripon, docteur en sciences et technologies de l'information et de la communication, travaille sur la théorie des graphes, la théorie de l'information, les réseaux de neurones formels et les nouvelles voies de l'intelligence artificielle.
Approuvé par les 375,005 étudiants
Accès à plus d'un million de titres pour un prix mensuel raisonnable.
Étudiez plus efficacement en utilisant nos outils d'étude.
Durant l’été 1956, John McCarthy, jeune docteur en mathématiques américain, invite quelques collègues à le retrouver à l’Université de Dartmouth, dans le New Hampshire, pour plusieurs semaines d’échanges autour d’une nouvelle thématique de recherche qu’il baptise « Intelligence artificielle ». Il se fait aider dans l’organisation de cette rencontre, qu’on appellerait aujourd’hui une « école d’été », par un autre jeune scientifique, Marvin Minsky. Ces deux chercheurs6 ne se rendaient certainement pas compte de l’importance qu’allait prendre dans l’imaginaire des informaticiens et des geeks à venir cet événement fondateur aujourd’hui connu sous le nom un peu pompeux de « Conférence de Dartmouth ». L’intelligence artificielle (IA) et ses applications potentielles n’ont depuis lors cessé de susciter l’intérêt de la communauté scientifique et peut-être plus encore du grand public.
Cependant, après quelques succès très modestes de réalisation matérielle, dont les « perceptrons » utilisés en classification automatique et qui seront rapidement présentés dans le chapitre 7, l’ambition de l’IA s’est progressivement reportée sur la conception de systèmes dits « experts ». Ces logiciels sont capables de reproduire des décisions qu’un expert humain pourrait prendre sur un problème limité, avec un jeu de critères restreint et dans un contexte bien circonscrit. Un exemple assez décoiffant en est donné par le site de Wolfram Alpha7 : tapez en anglais « somme de j**3 de 1 à n », c’est-à-dire 13+23+33+...+n3 et il vous sera répondu tout naturellement
, formule accompagnée de la courbe représentative. Demandez-lui ce qu’est la nicotine (what is nicotine ?) et il vous sera tout révélé de C5H4NC4H7NCH3. Tapez encore « ATTGACTTATGGAAC » et vous apprendrez que cela représente une séquence du génome humain que l’on trouve généralement dans les chromosomes 2 et 5, aux positions 146051871 et 116898353 respectivement ! Toutefois, l’outil principal de ce système comme de tous les systèmes experts reste le classique ordinateur, dont l’architecture et le fonctionnement sont, comme chacun le suppose, très éloignés de ceux du cerveau. Le XXe siècle ne fut donc pas le siècle de l’IA, sauf dans la littérature de science-fiction et au cinéma.
L’un des participants de la conférence de Dartmouth, aux côtés de McCarthy et Minsky, était Claude Elwood Shannon8, père de la théorie de l’information et ouvert à toutes les applications de cette science embryonnaire. De manière étonnante, rares sont aujourd’hui les théoriciens ou praticiens de l’information, au sens de Shannon – lequel sera précisé dans le prochain chapitre –, qui s’intéressent à l’IA ou à ses ramifications. Cette faible implication de la théorie de l’information dans le développement des sciences cognitives est d’autant plus surprenante que celles-ci sont encore largement incapables d’expliquer comment l’information est représentée, mémorisée, remémorée et exploitée dans le cerveau. Malgré tous les efforts accomplis ces dernières décennies dans l’exploration du réseau neural biologique, grâce à des procédés de plus en plus sophistiqués (électro-encéphalographie, microscopie électronique, imagerie par résonance magnétique, etc.), le cerveau demeure, du point de vue du traitement de l’information, terra incognita. Et il le restera, par l’approche strictement expérimentale, tant qu’on ne sera pas capable de mener des investigations au niveau des « individus neurones » et surtout des connexions – dont le plan varie d’un cerveau à l’autre –, ce qui ne sera pas matériellement possible avant longtemps.
Du côté de la théorie de l’information, elle-même portée par les progrès fulgurants de la microélectronique, des avancées considérables ont été obtenues dans l’écriture de l’information, sa compression, sa protection, son transport et son interprétation. Les systèmes de télécommunications modernes en sont aujourd’hui la manifestation quotidienne. Ces dernières années ont par exemple vu l’émergence de nouveaux procédés de traitement de l’information qui s’appuient sur des échanges de messages à l’intérieur de machines pluricellulaires. Chaque cellule est conçue pour traiter un problème élémentaire de manière localement optimale, et c’est l’échange d’informations entre les cellules qui conduit à un résultat globalement optimal, ou presque. On dit d’un tel traitement de l’information qu’il est distribué. Les turbocodes et le turbodécodage, inventions françaises des années 1990, ont ouvert la voie à ce type d’approches. Ils ont été assez rapidement rattrapés par la redécouverte de codes américains plus anciens dits « à vérification de parité de faible densité » (Low-Density -Parity-Check, LDPC pour faire court). Grâce à ces nouvelles méthodes, le traitement de l’information dans un récepteur de télécommunications s’est fortement rapproché de la façon dont le néocortex effectue ses opérations, par un échange multidirectionnel d’informations locales. Puisque la théorie de l’information mentale que nous proposons trouve ses origines dans le codage pluricellulaire, turbocode et code LDPC essentiellement, nous devrons en expliquer les principes généraux. Ce sera l’objet des chapitres 3 et 4.
Ainsi donc, la rencontre en 1956 de l’IA et de la théorie de l’information, toutes deux dans leurs balbutiements, ne fut que très provisoire. Les deux communautés se sont cependant retrouvées il y a une dizaine d’années, mais indirectement, chacune d’elles cherchant à établir un lien fort avec la « mécanique du cerveau ». Les résultats présentés dans les chapitres suivants sont le fruit d’un rapprochement direct et concret de ces deux grands domaines des sciences de l’information.
Les enjeux
Pauvreté, faim, rareté de l’eau, épidémies, nouvelles maladies, chamboulements climatiques, catastrophes naturelles, tyrannie, guerres, exploitation et obscurantisme sont les fléaux permanents qui frappent l’humanité, depuis ses débuts d’habilis jusqu’au plus ou moins sapiens d’aujourd’hui. La première mission de la recherche scientifique, à l’échelle mondiale, devrait être un combat incessant contre ces calamités. Mais même en réunissant toutes les forces disponibles, en supposant que la plupart des chercheurs acceptent d’être mobilisés sur ces enjeux majeurs quitte à en négliger d’autres, tels que le développement économique à marche forcée, les mathématiques financières ou la cosmologie quantique, l’intelligence humaine ne suffirait pas. Il lui faut impérativement trouver de l’assistance, non pas seulement de l’intelligence « augmentée » (anglais : amplified intelligence9) par un effort collectif ou même noosphérique10, mais de véritables auxiliaires intellectuels. En d’autres termes, il lui faut des machines pensantes, pour reprendre le vocabulaire d’Alan Turing11 ainsi qu’en partie le titre du livre d’Alain Cardon12.
Homo sapiens a 100 000 ans. Sa connaissance du monde et son savoir-faire technologique se sont accrus selon une progression à peu près exponentielle. Les connaissances techniques ont doublé tous les quinze ans depuis 170013 – le début de la « révolution scientifique » –, et le rythme s’accélère aujourd’hui par une sorte d’effet d’avalanche : l’expansion du savoir engendre de nouvelles technologies qui elles-mêmes ouvrent sur de nouvelles connaissances et ainsi de suite. Non pas pour en sourire, mais au contraire avec beaucoup de tendresse et d’intérêt, citons l’état de l’art de la biologie il y a environ 2 400 ans : « Tous les animaux et l’homme lui-même sont composés de deux substances divergentes pour leurs propriétés, mais convergentes pour l’usage, le feu, dis-je, et l’eau. Ces deux réunies se suffisent à elles-mêmes et à tout le reste ; mais l’une sans l’autre ni ne suffit à soi ni ne suffit à rien d’autre. Voici la propriété de chacune : le feu peut toujours tout mouvoir, l’eau toujours tout nourrir. Chacune, tour à tour, surmonte et est surmontée à chaque extrémité, en deçà et au-delà, qu’il lui est donné d’atteindre. Aucune ne peut triompher complètement14. » Cet état de l’art devient, au milieu du XXe siècle : « Tous les êtres vivants, sans exception, sont constitués des deux mêmes classes principales de macromolécules : protéines et acides nucléiques. De plus, ces macromolécules sont formées, chez tous les êtres vivants, par l’assemblage des mêmes radicaux, en nombre fini : vingt amino-acides pour les protéines, quatre types de nucléotides pour les acides nucléiques15. » Il n’est pas contestable que le dernier pour cent de l’existence d’Homo sapiens a bien plus contribué à la science biologique que les quatre-vingt-dix-neuf autres, même si tout n’est pas à effacer dans ce que nous ont transmis nos ancêtres. D’autres pourront en dire tout autant dans quarante ans, non pas du dernier pour cent mais du dernier pour cinq mille, de toutes les sciences. De cette accélération des savoirs et des nombreuses perspectives qu’elle va ouvrir rapidement pour l’humanité, il est peu question dans les médias et, plus regrettablement encore, dans les milieux autorisés des sciences humaines et sociales. On peut aisément trouver, dans un pays comme la France, plusieurs dizaines d’historiens experts des exploits de Jeanne d’Arc ou des amours de Louis XIV mais bien peu s’attellent aux répercussions possibles, dès demain ou après-demain, d’un progrès scientifique que l’on sait pourtant fulgurant. Certains le font cependant pour jouer les Cassandre : la prospective scientifique dépassionnée a moins bonne presse que le principe de précaution.
Pour tenir le rythme exponentiel du progrès scientifique, il nous faut aujourd’hui, comme disent les technocrates, une technologie de rupture, un nouveau paradigme. On connaît à peu près les perspectives de progression de la microélectronique classique : des circuits intégrés de quelques dizaines de milliards de transistors avant 202016. Un assemblage de quelques dizaines de ces composants sur un circuit imprimé, puis un raccordement de quelques dizaines de ces cartes dans un boîtier, suivant un principe d’architecture hiérarchique qui reste à définir, cela donnera un total de l’ordre de cent mille milliards de transistors17. On peut déjà observer qu’un tel édifice sera bien moins volumineux que le premier calculateur électronique de l’histoire, l’ENIAC18 de 1946 avec ses 1 800 tubes à vide et 7 200 diodes (vingt-sept tonnes de matériel au total en incluant les châssis et ventilateurs), mais aussi qu’il posera quelques problèmes de dissipation thermique et de refroidissement à partir d’une certaine fréquence de travail. En supposant que cent transistors soient suffisants pour émuler le comportement informationnel d’un neurone, cet appareillage offrirait une puissance de calcul comparable à celle d’une dizaine de cortex humains19.
Lorsqu’il s’agit de mettre en action des circuits fortement récurrents, c’est-à-dire des circuits dont les schémas des connexions contiennent beaucoup d’allers et retours, et quand par ailleurs de très nombreuses entrées peuvent s’activer simultanément, l’ordinateur classique avec son mode opératoire séquentiel n’est pas approprié ; trop d’incertitudes sur les effets de la sérialisation des instructions sont à redouter. De toute façon, l’objectif annoncé étant de concevoir une machine capable d’apprendre et de croiser des informations pour en produire de nouvelles, ces mille milliards de neurones électroniques ne devront pas être assemblés pour ressembler aux ordinateurs, dont toutes les réalisations jusqu’à ce jour n’ont jamais rien offert d’une telle propriété. Il nous faut considérer un autre type de construction, un véritable cortex artificiel, de nature fondamentalement connexionniste, c’est-à-dire une machine dont les aptitudes calculatoires reposent tout autant, sinon plus, sur le plan des connexions que sur les composants eux-mêmes. Si l’on souhaite obtenir de ce cortex artificiel des propriétés cognitives proches de celles du cerveau des animaux supérieurs, il semble inéluctable d’avoir à l’organiser autour de neurones et de connexions synaptiques. Mais jusqu’à quel degré de ressemblance fonctionnelle sera-t-il nécessaire d’aller ? C’est la question et, sur ce point, les avis des informaticiens divergent considérablement. Pour notre part, des modèles binaires suffiront.
Quoi qu’il en soit, cette machine, dans sa version définitive, ne contiendra aucune unité centrale de traitement, aucune mémoire de type RAM ou ROM, et bien sûr aucun logiciel. Cependant, pour lui permettre d’être en relation permanente avec le monde physique extérieur, une électronique d’appoint classique (ports d’entrée-sortie, transducteurs, convertisseurs, etc.) sera indispensable. Maintenant, cette machine, dont nous montrerons plus loin qu’elle sera capable d’apprendre des millions de milliards de « choses », nous la connectons, via Internet, à toutes les encyclopédies en ligne, à toutes les bases de données, aux centaines de millions de sites accessibles, sans oublier Wikipédia et Wolfram Alpha qui nous sont devenus si utiles, quand on les consomme avec modération. En la faisant travailler à une fréquence raisonnable, de l’ordre de 100 MHz et à raison d’une « chose » apprise toutes les centaines de cycles d’horloge (c’est Internet qui limite), une journée d’apprentissage lui donnera un « savoir » supérieur à celui qu’un être humain est capable d’engranger en une vie. Il nous faudra bien sûr préciser ce que sont ces « choses » et ce « savoir ».
En juin 2008, la revue IEEE Spectrum20 a consacré un dossier spécial à la singularité technologique. On peut croire ou non à ce tournant majeur à venir d...
Table des matières
Couverture
Titre
Copyright
Introduction
Chapitre 1 - Le siècle des machines pensantes
Chapitre 2 - L’information
Chapitre 3 - Le codage redondant
Chapitre 4 - Le codage redondant revisité
Chapitre 5 - Les graphes
Chapitre 6 - Les neurones
Chapitre 7 - Les réseaux de neurones
Chapitre 8 - Codes, cortex, cycles, cliques et corrélation
Chapitre 9 - La parcimonie
Chapitre 10 - Les cliques neurales
Chapitre 11 - Quelques chiffres
Chapitre 12 - Des cliques, mais encore…
Chapitre 13 - Des chaînes de tournois
Chapitre 14 - L’information mentale
Chapitre 15 - Le cogniteur
Notes
Remerciements
Index
Foire aux questions
Oui, vous pouvez résilier à tout moment à partir de l'onglet Abonnement dans les paramètres de votre compte sur le site Web de Perlego. Votre abonnement restera actif jusqu'à la fin de votre période de facturation actuelle. Découvrir comment résilier votre abonnement
Non, les livres ne peuvent pas être téléchargés sous forme de fichiers externes, tels que des PDF, pour être utilisés en dehors de Perlego. Cependant, vous pouvez télécharger des livres dans l'application Perlego pour les lire hors ligne sur votre téléphone portable ou votre tablette. Apprendre à télécharger des livres hors ligne
Perlego propose deux abonnements : Essentiel et Complet
Essentiel est idéal pour les étudiants et les professionnels qui aiment explorer un large éventail de sujets. Accédez à la bibliothèque Essentiel comprenant plus de 800 000 titres de référence et best-sellers dans les domaines du commerce, du développement personnel et des sciences humaines. Il comprend un temps de lecture illimité et la voix standard de la fonction Écouter.
Complet est parfait pour les étudiants avancés et les chercheurs qui ont besoin d'un accès complet et illimité. Accédez à plus de 1,4 million de livres sur des centaines de sujets, y compris des titres académiques et spécialisés. L'abonnement Complet comprend également des fonctionnalités avancées telles que la fonction Écouter Premium et l'Assistant de recherche.
Les deux abonnements sont disponibles avec des cycles de facturation mensuels, semestriels ou annuels.
Nous sommes un service d'abonnement à des ouvrages universitaires en ligne, où vous pouvez accéder à toute une bibliothèque pour un prix inférieur à celui d'un seul livre par mois. Avec plus d'un million de livres sur plus de 990 sujets, nous avons ce qu'il vous faut ! En savoir plus sur notre mission
Recherchez le symbole Écouter sur votre prochain livre pour voir si vous pouvez l'écouter. L'outil Écouter lit le texte à haute voix pour vous, en surlignant le passage qui est en cours de lecture. Vous pouvez le mettre sur pause, l'accélérer ou le ralentir. En savoir plus sur la fonctionnalité Écouter
Oui ! Vous pouvez utiliser l'application Perlego sur les appareils iOS et Android pour lire à tout moment, n'importe où, même hors ligne. Parfait pour les trajets quotidiens ou lorsque vous êtes en déplacement. Veuillez noter que nous ne pouvons pas prendre en charge les appareils fonctionnant sur iOS 13 et Android 7 ou versions antérieures. En savoir plus sur l'utilisation de l'application
Oui, vous pouvez accéder à Petite mathématique du cerveau par Claude Berrou,Vincent Gripon en format PDF et/ou ePUB ainsi qu'à d'autres livres populaires dans Sciences biologiques et Neurosciences. Nous disposons de plus d'un million d'ouvrages à découvrir dans notre catalogue.