
Data Science : fondamentaux et études de cas
Machine Learning avec Python et R
- 296 pages
- French
- ePUB (adaptée aux mobiles)
- Disponible sur iOS et Android
Data Science : fondamentaux et études de cas
Machine Learning avec Python et R
À propos de ce livre
Nous vivons une époque très excitante, qui ramène l'analyse de données et les méthodes quantitatives au coeur de la société. L'aboutissement de nombreux projets de recherche, la puissance de calcul informatique disponible et des données à profusion permettent aujourd'hui d'incroyables réalisations, grâce au travail des data scientists.
Un livre de référence pour les data scientists
La data science est l'art de traduire des problèmes industriels, sociaux, scientifiques, ou de toute autre nature, en problèmes de modélisation quantitative, pouvant être résolus par des algorithmes de traitement de données. Cela passe par une réflexion structurée, devant faire en sorte que se rencontrent problèmes humains, outils techniques/informatiques et méthodes statistiques/algorithmiques. Chaque projet de data science est une petite aventure, qui nécessite de partir d'un problème opérationnel souvent flou, à une réponse formelle et précise, qui aura des conséquences réelles sur le quotidien d'un nombre plus ou moins important de personnes.
Éric Biernat et Michel Lutz proposent de vous guider dans cette aventure. Ils vous feront visiter les vastes espaces de la data science moderne, de plus en plus présente dans notre société et qui fait tant parler d'elle, parfois par l'intermédiaire d'un sujet qui lui est corollaire, les big data.
Des études de cas pour devenir kaggle master
Loin des grands discours abstraits, les auteurs vous feront découvrir, claviers à la main, les pratiques de leur métier de data scientist chez OCTO Technology, l'un des leaders français du domaine. Et vous mettrez également la main à la pâte : avec juste ce qu'il faut de théorie pour comprendre ce qu'impliquent les méthodes mathématiques utilisées, mais surtout avec votre ordinateur personnel, quelques logiciels gratuits et puissants, ainsi qu'un peu de réflexion, vous allez participer activement à cette passionnante exploration !
À qui s'adresse cet ouvrage ?
Aux développeurs, statisticiens, étudiants et chefs de projets ayant à résoudre des problèmes de data science.
Aux data scientists, mais aussi à toute personne curieuse d'avoir une vue d'ensemble de l'état de l'art du machine learning.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Informations
TROISIÈME PARTIE
La data science en pratique : au-delà des algorithmes
Sous-partie 1
Quelques concepts généraux
14
Évaluer un modèle
Introduction
La validation croisée
De la nécessité de diviser vos données
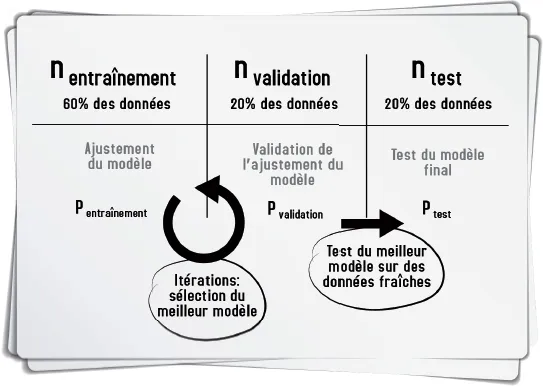
La validation croisée
Table des matières
- Couverture
- Le résumé et la biographie auteur
- Page de titre
- Copyright
- Préface
- Table des matières
- Avant-propos
- Première partie : Le B.A.-ba du data scientist
- Deuxième partie : Les algorithmes et leurs usages : visite guidée
- Troisième partie : La data science en pratique : au-delà des algorithmes
- Conclusion générale
- Index
Foire aux questions
- Essentiel est idéal pour les étudiants et les professionnels qui aiment explorer un large éventail de sujets. Accédez à la bibliothèque Essentiel comprenant plus de 800 000 titres de référence et best-sellers dans les domaines du commerce, du développement personnel et des sciences humaines. Il comprend un temps de lecture illimité et la voix standard de la fonction Écouter.
- Complet est parfait pour les étudiants avancés et les chercheurs qui ont besoin d'un accès complet et illimité. Accédez à plus de 1,4 million de livres sur des centaines de sujets, y compris des titres académiques et spécialisés. L'abonnement Complet comprend également des fonctionnalités avancées telles que la fonction Écouter Premium et l'Assistant de recherche.
Veuillez noter que nous ne pouvons pas prendre en charge les appareils fonctionnant sur iOS 13 et Android 7 ou versions antérieures. En savoir plus sur l'utilisation de l'application