Quando ho fatto richiesta per entrare al college, ho dovuto scrivere un breve saggio di presentazione. Non ricordo neppure la domanda precisa sul modulo, perché comunque non c’entrava niente. Il testo serviva semplicemente a farmi parlare di Christian Rudder, in modo che la Commissione decidesse se quello che c’era scritto le piaceva o meno. O, come recita il modulo standard: «Il testo personale ci aiuta a conoscerti come persona».
Melodrammatico com’ero già allora, ho parlato di quanto avrei sofferto nel separarmi dal mio cane per andare all’università. Avevamo adottato Frosty quando avevo sei anni, perciò eravamo cresciuti insieme. Ma, data la velocità con cui passano gli anni dei cani, lui era invecchiato troppo in fretta. La mia famiglia aveva cambiato città un mucchio di volte, e Frosty era l’ultimo legame che mi restava con l’infanzia: mi ero lasciato alle spalle circoli sportivi, piscine comunali e amici a Houston, Cleveland e Louisville, ma il cane era venuto sempre con me. Eppure sapevo bene che il prossimo trasferimento avrei dovuto farlo da solo.
In ogni caso, sprofondato nel pathos e nella mia maglietta extralarge di Escher, ho completato il modulo di iscrizione al college. Da quel giorno in poi, non mi è capitato spesso di scrivere un saggio su di me, ma, visto che adesso il mio lavoro è capire la gente, non posso fare a meno di ripensare al ragazzino di diciassette anni che ero e al testo di presentazione che avevo scelto di scrivere. Perché parlare di Frosty e degli anni che passavano? Perché non parlare del baseball? O del basket? O del tennis? O del fantabaseball? O di qualsiasi altro hobby? Che cosa mi aveva spinto a rispondere in quel modo alla domanda: «Chi sei?». E, aspetto ancora più importante, come avevano risposto i miei coetanei a quella stessa domanda?
Oggi, a vent’anni di distanza, mi ritrovo davanti a milioni di testi – miliardi di parole – scritti all’incirca per rispondere alla medesima domanda: «Chi sei?». E questo insieme di testi mi permette di fare l’esatto opposto della Commissione del college: anziché confrontare i saggi con un ideale preconcetto, posso mettere insieme tutte queste parole e vedere quali ideali mi rivelano. A volte una raccolta di dati è così completa che, se si esegue correttamente l’analisi, non c’è bisogno di porre domande: saranno i dati stessi a fornire le risposte. Come si descrive la gente? Cos’è importante, cos’è tipico, cos’è atipico? Quando le persone si trovano costrette a descriversi a parole, quali identità decidono di rappresentare?
Adesso analizzeremo ampie categorie di persone: i neri, i bianchi, gli asiatici, le donne, gli uomini e così via. Uno dei problemi maggiori che si incontrano quando si vuole studiare i vari gruppi umani è che non ci si libera mai totalmente dai propri pregiudizi. Quello che decidete di notare, ricordare e trascrivere dipende molto dal proprio punto di vista. Nelle scienze sociali, la conoscenza, come l’acqua, assume spesso la forma del suo recipiente. Perciò, se vogliamo prendere in considerazione tutte le descrizioni personali che ho raccolto e cercare di capire chi sono gli autori – cosa rende unici i sessi, le etnie e gli orientamenti sessuali –, dovremo sviluppare un algoritmo che elimina il «noi» e lascia solo il «loro».
I profili richiesti agli utenti di OkCupid sono una specie di sintesi personale. Le domande sono aperte:
- «La mia sintesi personale…»
- «Sono davvero bravo a…»
- «Le prime cose che gli altri notano di me…»
- «Penso spesso a…»
E, per quanto la gente si sforzi di dare il meglio di sé, questi testi non sono poi così diversi dalle presentazioni universitarie. Immagino che molti li affronteranno con gli stessi timori. Non ci sono limiti di lunghezza né linee guida, a parte le domande iniziali. Nel complesso, gli utenti hanno fornito al sito 3,2 miliardi di parole per autodescriversi. In più, a differenza degli altri testi di grandi dimensioni – per esempio, quelli raccolti da Google Books –, qui ogni singola parola nasconde un dato demografico: l’età dell’autore, dove vive, a quale etnia appartiene e così via. Ma dedurre dal testo un’identità di gruppo per, che so, le donne asiatiche, non è facile come calcolare chi digita cosa con più frequenza, che in sostanza è quello che abbiamo fatto finora. Conteggiare le parole ci porta solo a questa classifica:
- the («il»)
- of («di»)
- and («e»)
- …
e così via (fondamentalmente, sono le prime cento parole dell’Oxford English Corpus che abbiamo visto in precedenza). Le donne asiatiche, gli uomini bianchi e tutti gli anglofoni usano gli stessi pronomi, articoli e preposizioni per parlare di se stessi. Per scoprire cosa rende davvero speciale un certo gruppo, e solo quello, dobbiamo analizzare il testo in maniera leggermente diversa.1
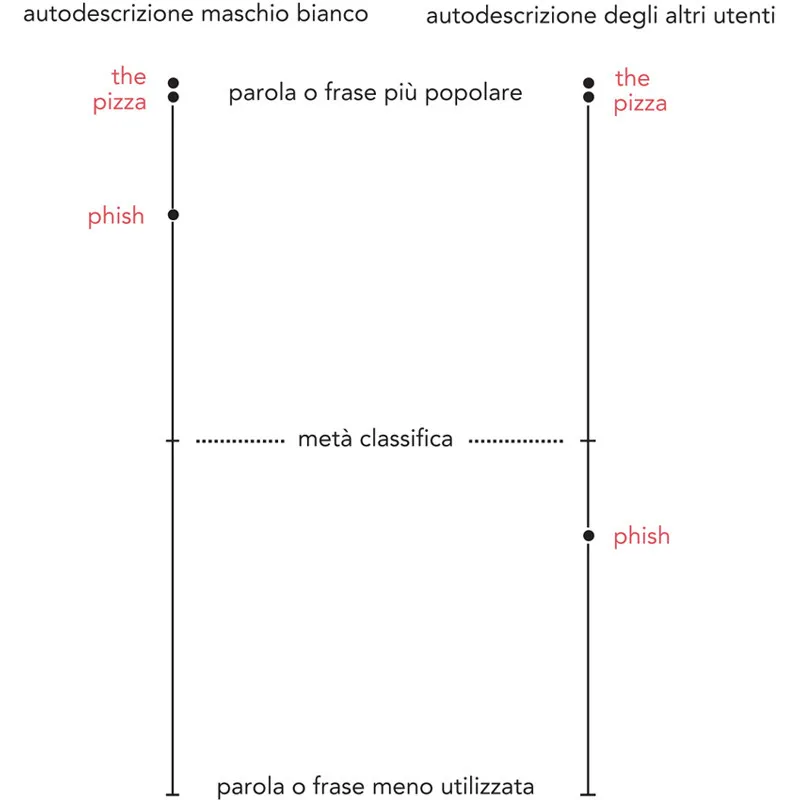
Userò i maschi bianchi come esempio, perché sono il campione che capisco meglio. Il primo passo è separare i testi di presentazione dei maschi bianchi da quelli di tutti gli altri. Poi, all’interno dei due gruppi (maschi bianchi e non) di autodescrizioni, elenchiamo tutte le parole e le frasi a seconda della frequenza di apparizione. Le dividiamo in due liste in ordine decrescente (dalle più popolari alle meno utilizzate), ottenendo un grafico simile a quello seguente. Ho scelto tre esempi e li ho collocati sulla linea. Ciascuna lista completa è composta da circa 360 mila frasi.
Stiamo già cominciando a capirci qualcosa ma, prima che la situazione si complichi, voglio chiarire un punto fuorviante. No, non c’entra niente con i Phish, il gruppo rock degli anni Ottanta, anche se avrà mandato fuori strada un sacco di gente. Il fatto è che pizza e the compaiono all’incirca lo stesso numero di volte. D’accordo, la pizza è il re dei cibi, ma l’articolo the è in assoluto la parola più comune nella lingua inglese. E nei nostri dati, mentre l’articolo è giustamente in cima alla classifica, a quanto pare anche pizza è allo stesso livello, al 98° percentile. Detto così, sembra che ci sia qualcosa di sbagliato, o nei miei dati o nel mio metodo, eppure la classifica delle parole è corretta. Perché gli uomini usano il linguaggio in modo strano: ci ripetiamo in continuazione e, perciò, un ristretto numero di parole in cima alla classifica compare con enorme frequenza nei nostri scritti. E, per contro, la frequenza di un termine crolla molto rapidamente appena ci si allontana anche di poco dalla «più popolare».
La relazione controintuitiva tra la popolarità di una parola (il suo rango in un dato vocabolario) e il numero di volte in cui appare viene descritta dalla cosiddetta «legge di Zipf»,2 una proprietà statisticamente osservata del linguaggio che, come il meglio della matematica, risiede in qualche punto tra il miracolo e la coincidenza.a La legge afferma che in ogni corpus testuale ampio, la popolarità di una parola (la sua posizione nel vocabolario considerato, dove 1 è il posto in classifica più alto...