
Hands-On Q-Learning with Python
Practical Q-learning with OpenAI Gym, Keras, and TensorFlow
Nazia Habib
- 212 pagine
- English
- ePUB (disponibile sull'app)
- Disponibile su iOS e Android
Hands-On Q-Learning with Python
Practical Q-learning with OpenAI Gym, Keras, and TensorFlow
Nazia Habib
Informazioni sul libro
Leverage the power of reward-based training for your deep learning models with Python
Key Features
- Understand Q-learning algorithms to train neural networks using Markov Decision Process (MDP)
- Study practical deep reinforcement learning using Q-Networks
- Explore state-based unsupervised learning for machine learning models
Book Description
Q-learning is a machine learning algorithm used to solve optimization problems in artificial intelligence (AI). It is one of the most popular fields of study among AI researchers.
This book starts off by introducing you to reinforcement learning and Q-learning, in addition to helping you get familiar with OpenAI Gym as well as libraries such as Keras and TensorFlow. A few chapters into the book, you will gain insights into modelfree Q-learning and use deep Q-networks and double deep Q-networks to solve complex problems. This book will guide you in exploring use cases such as self-driving vehicles and OpenAI Gym's CartPole problem. You will also learn how to tune and optimize Q-networks and their hyperparameters. As you progress, you will understand the reinforcement learning approach to solving real-world problems. You will also explore how to use Q-learning and related algorithms in real-world applications such as scientific research. Toward the end, you'll gain a sense of what's in store for reinforcement learning.
By the end of this book, you will be equipped with the skills you need to solve reinforcement learning problems using Q-learning algorithms with OpenAI Gym, Keras, and TensorFlow.
What you will learn
- Explore the fundamentals of reinforcement learning and the state-action-reward process
- Understand Markov decision processes
- Get well versed with libraries such as Keras, and TensorFlow
- Create and deploy model-free learning and deep Q-learning agents with TensorFlow, Keras, and OpenAI Gym
- Choose and optimize a Q-Network's learning parameters and fine-tune its performance
- Discover real-world applications and use cases of Q-learning
Who this book is for
If you are a machine learning developer, engineer, or professional who wants to delve into the deep learning approach for a complex environment, then this is the book for you. Proficiency in Python programming and basic understanding of decision-making in reinforcement learning is assumed.
Domande frequenti
Informazioni
Section 1: Q-Learning: A Roadmap
- Chapter 1, Brushing Up on Reinforcement Learning Concepts
- Chapter 2, Getting Started with the Q-Learning Algorithm
- Chapter 3, Setting Up Your First Environment with OpenAI Gym
- Chapter 4, Teaching a Smartcab to Drive Using Q-Learning
Brushing Up on Reinforcement Learning Concepts
- Reviewing RL and the differences between reward-based learning and other types of machine learning
- Learning what states are and what it means to take an action and receive a reward
- Understanding how RL agents make decisions based on policies and future rewards
- Discovering the two major types of model-free RL and diving deeper into Q-learning
What is RL?
- Agent: This is the decision-making entity.
- Environment: This is the world in which the agent operates, such as a game to win or task to accomplish.
- State: This is where the agent is in its environment. When you define the states that an agent can be in, think about what it needs to know about its environment. For example, a self-driving car will need to know whether the next traffic light is red or green and whether there are pedestrians in the crosswalk; these are defined as state variables.
- Action: This is the next move that the agent chooses to take.
- Reward: This is the feedback that the agent gets from the environment for taking that action.
- Policy: This is a function to map the agent's states to its actions. For your first RL agent, this will be as simple as a lookup table, called the Q-table. It will operate as your agent's brain.
- Value: This is the future reward that an agent would receive by taking an action based on the future actions it could take. This is separate from the immediate reward it will get from taking that action (the value is also commonly called the utility).
States and actions
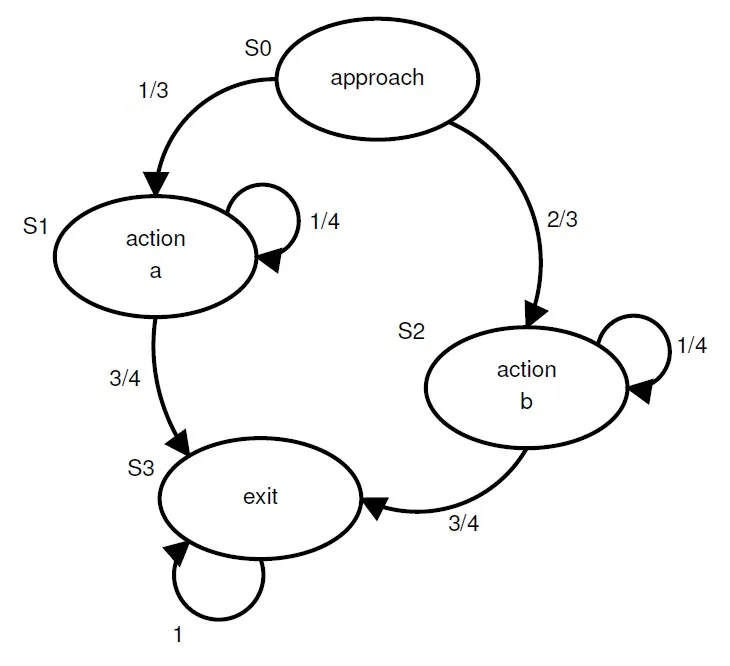
The decision-making process
- Take note of what state you're in.
- Take an action based on your policy and receive a reward.
- Take note of the reward you received by taking that action in that state.
Indice dei contenuti
- Title Page
- Copyright and Credits
- About Packt
- Contributors
- Preface
- Section 1: Q-Learning: A Roadmap
- Brushing Up on Reinforcement Learning Concepts
- Getting Started with the Q-Learning Algorithm
- Setting Up Your First Environment with OpenAI Gym
- Teaching a Smartcab to Drive Using Q-Learning
- Section 2: Building and Optimizing Q-Learning Agents
- Building Q-Networks with TensorFlow
- Digging Deeper into Deep Q-Networks with Keras and TensorFlow
- Section 3: Advanced Q-Learning Challenges with Keras, TensorFlow, and OpenAI Gym
- Decoupling Exploration and Exploitation in Multi-Armed Bandits
- Further Q-Learning Research and Future Projects
- Assessments
- Other Books You May Enjoy