
Caffe2 Quick Start Guide
Modular and scalable deep learning made easy
Ashwin Nanjappa
- 136 pagine
- English
- ePUB (disponibile sull'app)
- Disponibile su iOS e Android
Caffe2 Quick Start Guide
Modular and scalable deep learning made easy
Ashwin Nanjappa
Informazioni sul libro
Build and train scalable neural network models on various platforms by leveraging the power of Caffe2
Key Features
- Migrate models trained with other deep learning frameworks on Caffe2
- Integrate Caffe2 with Android or iOS and implement deep learning models for mobile devices
- Leverage the distributed capabilities of Caffe2 to build models that scale easily
Book Description
Caffe2 is a popular deep learning library used for fast and scalable training and inference of deep learning models on various platforms. This book introduces you to the Caffe2 framework and shows how you can leverage its power to build, train, and deploy efficient neural network models at scale.
It will cover the topics of installing Caffe2, composing networks using its operators, training models, and deploying models to different architectures. It will also show how to import models from Caffe and from other frameworks using the ONNX interchange format. It covers the topic of deep learning accelerators such as CPU and GPU and shows how to deploy Caffe2 models for inference on accelerators using inference engines. Caffe2 is built for deployment to a diverse set of hardware, using containers on the cloud and resource constrained hardware such as Raspberry Pi, which will be demonstrated.
By the end of this book, you will be able to not only compose and train popular neural network models with Caffe2, but also be able to deploy them on accelerators, to the cloud and on resource constrained platforms such as mobile and embedded hardware.
What you will learn
- Build and install Caffe2
- Compose neural networks
- Train neural network on CPU or GPU
- Import a neural network from Caffe
- Import deep learning models from other frameworks
- Deploy models on CPU or GPU accelerators using inference engines
- Deploy models at the edge and in the cloud
Who this book is for
Data scientists and machine learning engineers who wish to create fast and scalable deep learning models in Caffe2 will find this book to be very useful. Some understanding of the basic machine learning concepts and prior exposure to programming languages like C++ and Python will be useful.
Domande frequenti
Informazioni
Training Networks
- Introduction to training a neural network
- Building the training network for LeNet
- Training and monitoring the LeNet network
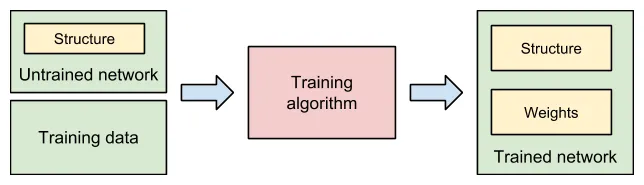
Introduction to training
Components of a neural network
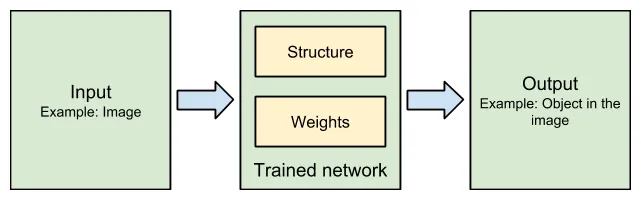
Structure of a neural network
Weights of a neural network
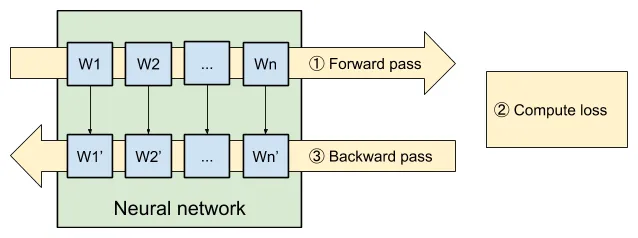
Training process
Indice dei contenuti
- Title Page
- Copyright and Credits
- About Packt
- Contributors
- Preface
- Introduction and Installation
- Composing Networks
- Training Networks
- Working with Caffe
- Working with Other Frameworks
- Deploying Models to Accelerators for Inference
- Caffe2 at the Edge and in the cloud
- Other Books You May Enjoy