
Machine Learning with Go Quick Start Guide
Hands-on techniques for building supervised and unsupervised machine learning workflows
Michael Bironneau, Toby Coleman
- 168 pagine
- English
- ePUB (disponibile sull'app)
- Disponibile su iOS e Android
Machine Learning with Go Quick Start Guide
Hands-on techniques for building supervised and unsupervised machine learning workflows
Michael Bironneau, Toby Coleman
Informazioni sul libro
This quick start guide will bring the readers to a basic level of understanding when it comes to the Machine Learning (ML) development lifecycle, will introduce Go ML libraries and then will exemplify common ML methods such as Classification, Regression, and Clustering
Key Features
- Your handy guide to building machine learning workflows in Go for real-world scenarios
- Build predictive models using the popular supervised and unsupervised machine learning techniques
- Learn all about deployment strategies and take your ML application from prototype to production ready
Book Description
Machine learning is an essential part of today's data-driven world and is extensively used across industries, including financial forecasting, robotics, and web technology. This book will teach you how to efficiently develop machine learning applications in Go.
The book starts with an introduction to machine learning and its development process, explaining the types of problems that it aims to solve and the solutions it offers. It then covers setting up a frictionless Go development environment, including running Go interactively with Jupyter notebooks. Finally, common data processing techniques are introduced.
The book then teaches the reader about supervised and unsupervised learning techniques through worked examples that include the implementation of evaluation metrics. These worked examples make use of the prominent open-source libraries GoML and Gonum.
The book also teaches readers how to load a pre-trained model and use it to make predictions. It then moves on to the operational side of running machine learning applications: deployment, Continuous Integration, and helpful advice for effective logging and monitoring.
At the end of the book, readers will learn how to set up a machine learning project for success, formulating realistic success criteria and accurately translating business requirements into technical ones.
What you will learn
- Understand the types of problem that machine learning solves, and the various approaches
- Import, pre-process, and explore data with Go to make it ready for machine learning algorithms
- Visualize data with gonum/plot and Gophernotes
- Diagnose common machine learning problems, such as overfitting and underfitting
- Implement supervised and unsupervised learning algorithms using Go libraries
- Build a simple web service around a model and use it to make predictions
Who this book is for
This book is for developers and data scientists with at least beginner-level knowledge of Go, and a vague idea of what types of problem Machine Learning aims to tackle. No advanced knowledge of Go (and no theoretical understanding of the math that underpins Machine Learning) is required.
Domande frequenti
Informazioni
Deploying Machine Learning Applications
- The continuous delivery feedback loop, including how to test, deploy, and monitor ML applications
- Deployment models for ML applications
The continuous delivery feedback loop
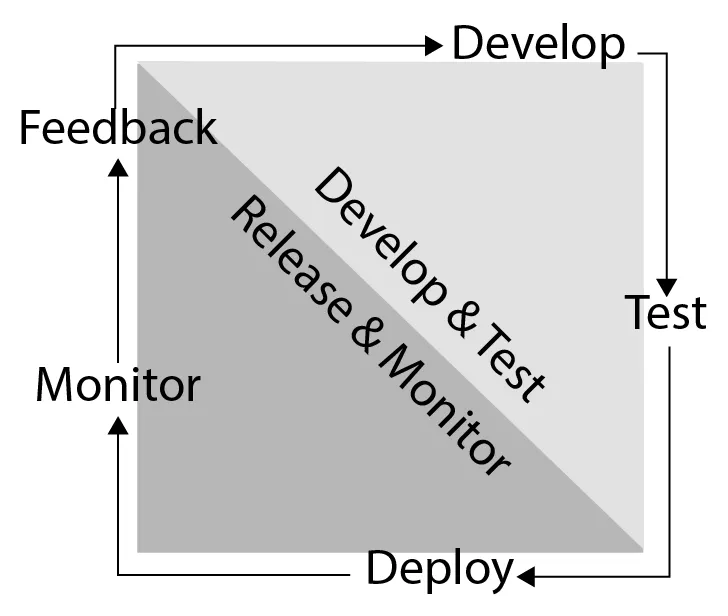
Developing
Testing
- Define accuracy/precision goals for the model: This may not be as simple as coming up with a single accuracy score, as reducing false positives or false negatives may take precedence. For example, a classifier that aims to determine whether a mortgage applicant should get a loan may be required to err on the side of caution, with more false negatives tolerated than false positives, depending on the risk profile of the lender.
- Define edge case behavior and codify this into unit tests: This may require traditional logic to restrict the output of the ML model to ensure that these constraints are met and traditional unit tests to assert on the constrained output of the ML model.
Deployment
- Dependency on scientific libraries that require LAPACK or BLAS entails complex installation processes with many steps, and chances for mistakes.
- Dependency on deep-learning libraries, such as TensorFlow, entails dynamic linking to C libraries, again leading to a complex installation process, with many OS and architecture-specific steps, and chances for mistakes.
- Deep learning models may need to run on specialized hardware (for example, servers with GPUs), even for testing
- Where should ML models be persisted? Should they be committed as though they were source code? If so, how can we be sure we are deploying the correct version?
Dependencies
Indice dei contenuti
- Title Page
- Copyright and Credits
- About Packt
- Contributors
- Preface
- Introducing Machine Learning with Go
- Setting Up the Development Environment
- Supervised Learning
- Unsupervised Learning
- Using Pretrained Models
- Deploying Machine Learning Applications
- Conclusion - Successful ML Projects
- Other Books You May Enjoy