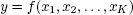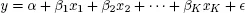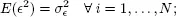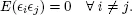![]()
1
Econometrics and Spatial Dimensions
1.1. Introduction
Does a region specializing in the extraction of natural resources register slower economic growth than other regions in the long term? Does industrial diversification affect the rhythm of growth in a region? Does the presence of a large company in an isolated region have a positive influence on the pay levels, compared to the presence of small-and medium-sized companies? Does the distance from highway access affect the value of a commercial/industrial/residential terrain? Does the presence of a public transport system affect the price of property? All these are interesting and relevant questions in regional science, but the answers to these are difficult to obtain without using appropriate tools. In any case, statistical modeling (econometric model) is inevitable in obtaining elements of these answers.
What is econometrics anyway? It is a domain of study that concerns the application of methods of statistical mathematics and statistical tools with the goal of inferring and testing theories using empirical measurements (data). Economic theory postulates hypotheses that allow the creation of propositions regarding the relations between various economic variables or indicators. However, these propositions are qualitative in nature and provide no information on the intensity of the links that they concern. The role of econometrics is to test these theories and provide numbered estimations of these relations. To summarize, econometrics, it is the statistical branch of economics: it seeks to quantify the relations between variables using statistical models.
For some, the creation of models is not satisfactory in that they do not take into account the entirety of the complex relations of reality. However, this is precisely one of the goals of models: to formulate in a simple manner the relations that we wish to formalize and analyze. Social phenomena are often complex and the human mind cannot process them in their totality. Thus, the model can then be used to create a summary of reality, allowing us to study it in part. This particular form obviously does not consider all the characteristics of reality, but only those that appear to be linked to the object of the study and that are particularly important for the researcher. A model that is adapted to a certain study often becomes inadequate when the object of the study changes, even if this study concerns the same phenomenon.
We refer to a model in the sense of the mathematical formulation, designed to approximately reproduce the reality of a phenomenon, with the goal of reproducing its function. This simplification aims to facilitate the understanding of complex phenomena, as well as to predict certain behaviors using statistical inference. Mathematical models are, generally, used as part of a hypothetico-deductive process. One class of model is particularly useful in econometrics: these are statistical models. In these models, the question mainly revolves around the variability of a given phenomenon, the origin of which we are trying to understand (dependent variable) by relating it to other variables that we assume to be explicative (or causal) of the phenomenon in question.
Therefore, an econometric model involves the development of a statistical model to evaluate and test theories and relations and guide the evaluation of public policies1. Simply put, an econometric model formalizes the link between a variable of interest, written as y, as being dependent on a set of independent or explicative variables, written as x1, x2,…, xK, where K represents the total number of explicative variables (equation [1.1]). These explicative variables are then suspected as being at the origin of the variability of the dependent or endogenous variable:
We still need to be able to propose a form for the relation that links the variables, which means defining the form of the function f (•). We then talk of the choice of functional form. This choice must be made in accordance with the theoretical foundation of the phenomena that we are looking to explain. The researcher thus explicitly hypothesizes on the manner in which the variables are linked together. The researcher is said to be proposing a data generating process (DGP). He/she postulates a relation that links the selected variables without necessarily being sure that the postulated form is right. In fact, the validity of the statistical model relies largely on the DGP postulated. Thus, the estimated effects of the independent variables on the determination of the dependent variables arise largely from the postulated relation, which reinfirce the importance of the choice of the functional form. It is important to note that the functional form (or the type of relation) is not necessarily known with certitude during empirical analysis and that, as a result, the DGP is postulated: it is the researcher who defines the form of the relations as a function of the a priori theoretical forms and the subject of interest.
Obviously, since all of the variables, which influence the behavior during the study, and the form of the relation are not always known, it is a common practice to include, in the statistical model, a term that captures this omission. The error of specification is usually designated by the term
. Some basic assumptions are made on the behavior of the “residual” term (or error term). Violating these basic assumptions can lead to a variety of consequences, starting from imprecision in the measurement of variance, to bias (bad measurement) of the searched for effect.
The simplest econometric statistical model is the one which linearly links a dependent variable to a set of interdependent variables equation [1.2]. This relation is usually referred to as multiple linear regression. In the case of a single explicative variable, we talk of simple linear regression. The simple linear regression can be likened to the study of correlation2. The linear regression model assumes that the dependent variable (y) is linked, linearly in the parameter, βk, to the K (k = 1, 2, …, K) number of independent variables (xk):
The linear regression model allows us not only to know whether an explicative variable xk is statistically linked to the dependent variable (βk ≠ 0), but also to check if the two variables vary in the same direction (βk > 0) or in opposite directions (βk < 0). It also allows us to answer the question: “by how much does the variable of interest (explained variable) change when the independent variable (dependent variable) is modified?”. Herein also lies a large part of the goal of regression analysis: to study or simulate the effect of changes or movements of the independent variable on the behavior of the dependent variable (partial analysis). Therefore, the statistical model is a tool that allows us to empirically test certain hypotheses certain hypotheses as well as making inference from the results obtained.
The validity of the estimated parameters, and as a result, the validity of the statistical relation, as well as of the hypotheses tests from the model, rely on certain assumptions regarding the behavior of the error term. Thus, before going further into the analysis of the results of the econometric model it is strongly recommended to check if the following assumptions are respected:
– the expectation of error terms is zero: the assumed model is “true” on average:
– the variance of the disturbances is constant for each individual: disturbance homoskedasticity assumption:
– the disturbances of the model are independent (non-correlated) among themselves: the variable of interest is not influenced, or structured, by any other variables than the ones retained:
The first assumption is, by definition, globally respected when the model is estimated by the method of ordinary least squares (OLS). However, nothing indicates that, locally, this property is applicable: the errors can be positive (negative) on average for high (low) values of the dependent variable. This behavior usually marks a form of nonlinearity in the relation3. Certain simple approaches allow us to take into account the nonlinearity of the relation: the transformation of variables (logarithm, square root, etc.), the introduction of quadratic forms (x, x2, x3, etc.), the introduction of dummy variables and so on and so forth.
The second assumption concerns the calculation of the variance of the disturbances and the influence of the variance of the estimator of parameter β. Indeed, the application of common statistical tests largely relies on the estimated variance and when this value is not minimal, the measurement of the variance of parameter β is not correct and the application of classical hypothesis tests is not appropriate. It is then necessary to correct the problem of heteroskedasticity of the variance of the disturbances. The procedures to correct for the presence of heteroskedasticity are relatively simple and well documented.
The third assumption is more important: if it is violated, it can invalidate the results obtained. Depending on the form of the structure between the observations, it can have an influence on the estimation of the variance of parameters or even on the value of the estimated parameters. This latter consequence is heavier since it potentially invalidates all of the conclusions taken from the results obtained. Once again, to ensure an accurate interpretation of the results, the researcher must correct the problem of the correlation between the error terms. Here the procedures to correct for correlation among the error terms are more complex and largely depend on the type of data considered.
1.2. The types of data
The models used are largely linked to the structure and the characteristics of the data available for the analysis. However, the violation of one or several assumptions on the error terms is equally a function of the type of data used. Without a loss in generality, it is possible to identify three types of data: cross-sectional data, time series data and spatio-temporal data. The importance of the spatial dimension comes out particularly in the cross-sectional and spatio-temporal data.
The first essential step when working with a quantitative approach is to identify the type of data available to make the analyses. Not only do these data have particular characteristics in terms of violating the assumptions about the structure of the error terms, but they also influence the type of model that must be used. The type of model depends largely on the characterization of the dependent variables. Specific models are drawn for dummy variables (logit or probit models), for positive discrete (count) data (Poisson or negative binomial models), for truncated data (Heckman or Tobit models), etc. For the most part, the current demonstration will be focused on the models adapted to the case where the dependent variable is continuous (linear regression model).
1.2.1. Cross-sectional data
Cross-sectional data rely on a large number of observations (individuals, firms, countries, etc.) at a given time period. Database are usually defined as a file containing characteristic information from a set of observations: in a sense it is a picture giving the portrait of individuals at a fixed date. It is common practice to introduce some subindices to mark the individual observations. This subindex is written as i and the total number of observations is usually designated by N: i = 1, 2, …, N.
For this type of data, the sources of the variation are interobservations, i.e. between the observations. It is then possible that the variation of the dependent variable is linked to some characteristics that are unique to the individuals. In the case where we cannot identify the majority of the factors that influence the variation of the dependent variable, we are faced with a problem of non-homogeneous variance, or heteroskedasticity problem. This behavior violates the second assumption of the behavior of the error terms. The linear regression model must then be corrected so that the estimated variance respects the base assumption so that the usual tests have the correct interpretation.
The tests for the detection of heteroskedasticity that are the best known are certainly those by Breusch and Pagan [BRE 79] and White [WHI 80]. The former suggests verifying if there is a significant statistical relation between the error terms squared (an estimation of the variance) and the independent variables of the model. In the case where this relation proves to be significant, we say that the variance is not homogeneous and depends on certain values of the independent variables. The second test is based on a similar approach. The White test suggests regressing the error terms squared for the whole set of the independent variables of the model as well as the crossed terms and quadratic terms of the variables. This addition of the quadratic and crossed terms allows us to consider a certain form of nonlinearity in the explanation of the variance. As for the previous case, the tests aim to verify the existence of a significant relation between the variance of the model and some independent variables or more complex terms, in which we must reject the homogeneity hypothesis of the variance.
This type of data is largely used in microeconomics and in all the related domains. The spatial data are cross-sectional data but incorporating another particularity: the error terms can be correlated among themselves in space since they share common localization characteristics. This behavior is then in violation of the third assumption, linked to the independence between the error terms. This is the heart and foundation of spatial econometrics (we will come back to it a bit later).
1.2.2. Time series
Time series rely on the accumulation of information, over time, of a given individual (a firm, an employee, a country, etc.). It is a continuous acquisition of information on the characteristics of an individual over time. Thus, it is quite common for the values of the observations to be dependent over time. As before, these series call upon the use of a subindex, marked t. The size of the database is given by the number of periods available to conduct the analysis, T : t = 1, 2,…, T.
With this type of data the variation studied is intra-observation, i.e. over time, but for a unique observation. This type of data is likely to reveal a correlation between the error terms over time and thus be in violation of the third base assumption on the behavior of error terms. We then talk of temporal autocorrelation. In this case, the parameters obtained can be biased and the conclusions that we draw from the model can be wrong. The problems of temporal correlation between the error terms have been known for several centuries.
The most commonly used test to detect such a phenomenon is the Durbin and Watson statistic [DUR 50]. This test is inspired by a measurement of the correlation between the value of the residuals taken at a period, t, and one taken at the previous period, t – 1. It aims to verify that the correlation is statistically significant, in which case we are in the presence of temporal (or serial) autocorrelation. Another simple test consists of regressing the values of the residuals of the model at the period t for the value of the previous period, t – 1, and look to determine if the parameter associated with the time-lagged variable of the residuals is significant4. The correction methods are also largely documented and usually availa...