
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Regression Methods for Medical Research
About this book
Regression Methods for Medical Research provides medical researchers with the skills they need to critically read and interpret research using more advanced statistical methods. The statistical requirements of interpreting and publishing in medical journals, together with rapid changes in science and technology, increasingly demands an understanding of more complex and sophisticated analytic procedures.
The text explains the application of statistical models to a wide variety of practical medical investigative studies and clinical trials. Regression methods are used to appropriately answer the key design questions posed and in so doing take due account of any effects of potentially influencing co-variables. It begins with a revision of basic statistical concepts, followed by a gentle introduction to the principles of statistical modelling. The various methods of modelling are covered in a non-technical manner so that the principles can be more easily applied in everyday practice. A chapter contrasting regression modelling with a regression tree approach is included. The emphasis is on the understanding and the application of concepts and methods. Data drawn from published studies are used to exemplify statistical concepts throughout.
Regression Methods for Medical Research is especially designed for clinicians, public health and environmental health professionals, para-medical research professionals, scientists, laboratory-based researchers and students.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
1 Introduction
INTRODUCTION
STATISTICAL MODELS
Comparing two means
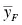
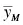
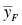
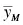
Table of contents
- Cover
- Title page
- Copyright page
- Dedication
- Preface
- 1 Introduction
- 2 Linear Regression: Practical Issues
- 3 Multiple Linear Regression
- 4 Logistic Regression
- 5 Poisson Regression
- 6 Time-to-Event Regression
- 7 Model Building
- 8 Repeated Measures
- 9 Regression Trees
- 10 Further Time-to-Event Models
- 11 Further Topics
- Statistical Tables
- References
- Index
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app