
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Knowledge Discovery with Support Vector Machines
About this book
An easy-to-follow introduction to support vector machines
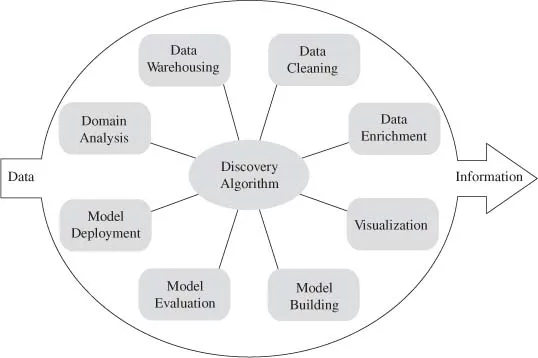
This book provides an in-depth, easy-to-follow introduction to support vector machines drawing only from minimal, carefully motivated technical and mathematical background material. It begins with a cohesive discussion of machine learning and goes on to cover:
-
Knowledge discovery environments
-
Describing data mathematically
-
Linear decision surfaces and functions
-
Perceptron learning
-
Maximum margin classifiers
-
Support vector machines
-
Elements of statistical learning theory
-
Multi-class classification
-
Regression with support vector machines
-
Novelty detection
Complemented with hands-on exercises, algorithm descriptions, and data sets, Knowledge Discovery with Support Vector Machines is an invaluable textbook for advanced undergraduate and graduate courses. It is also an excellent tutorial on support vector machines for professionals who are pursuing research in machine learning and related areas.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
- A data universe X
- A sample set S, where S X
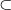
- Some target function (labeling process) f : X → {true, false}
- A labeled training set D, where D = {(x, y) | x S and y = f (x)}

Table of contents
- Cover
- Title
- Copyright
- Dedication
- Preface
- Wiley Series on Methods and Applications in Data Mining
- PART I
- PART II
- PART III
- APPENDIX A NOTATION
- APPENDIX B TUTORIAL INTRODUCTION TO R
- REFERENCES
- INDEX
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app