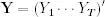![]()
Part I
Methodology
![]()
Chapter 1
Introduction
All scientific investigations are concerned with obtaining a deeper understanding of the world in which we live. Such investigations may be motivated primarily by curiosity, but more often by a recognition that such an understanding is beneficial to the wellbeing of humanity. Environmental science is an area where many would argue that the current level of knowledge pales into insignificance beside the capacity to enact rapid changes on an unprecedented scale, and therefore that it is not only beneficial but essential to understand more clearly the processes at work. Examples of current concerns include the response of climate to greenhouse gas emissions and the knock-on effects in areas such as water resources, agriculture and human health; the effects of industrial activity upon the quality of air and drinking water; the implications of intensive agricultural practices for biodiversity; and the sustainability of industrial-scale fishing operations. In all of these examples, the most compelling grounds for concern are observational: increases in global mean temperatures and various indices of extreme weather (Solomon et al., 2007), increases in the incidence of respiratory diseases associated with particulate matter in the atmosphere (Anderson et al., 1996; Zmirou et al., 1998), declines in the numbers of farmland birds in Europe (Siriwardena et al., 1998) and shrinking fish catches (Pauly et al. 2002), to cite just a few examples.
Broadly speaking, to develop an understanding of such phenomena there are two possible approaches. The first is to consider the fundamental processes that are believed to be operating and to build a more or less detailed model of these processes that can be used to make predictions and explore alternative scenarios. Examples of this ‘process based’ approach include the physical and chemical models of the atmosphere and oceans that are routinely used to provide projections of the earth's climate throughout the twenty-first century (Saunders, 1999; Solomon et al., 2007).
The second approach is to analyse the available data, either to look for relationships that could explain how the system works or to test hypotheses suggested by process based considerations. ‘Trend analysis’ can be defined as the use of such an empirical approach to quantify and explain changes in a system over a period of time.1 The statistical tools required to carry out a trend analysis range from the simple to the very advanced. However, the complexity of most environmental systems, often coupled with difficulties in making accurate observations, ensures that simple methods are rarely adequate for more than a preliminary inspection of the data. At best, such methods may fail to extract all of the available information (which, given the cost of obtaining much environmental data, is a waste of resources) and, at worst, they may yield misleading conclusions. To avoid these pitfalls it is therefore usually necessary to use more advanced methods, such as those described in the following chapters. Many of these have been developed relatively recently, and therefore are unlikely to be encountered in a traditional introductory statistics course for environmental scientists. However, all of them are well established in the statistical literature and have been found to be useful in a wide variety of applications. Furthermore, many of them can be implemented easily using freely available software.
Before proceeding any further, it is worth clarifying the subject matter of the book by defining what is meant by a ‘trend’, examining some of the questions that might lead one to carry out a trend analysis and summarising some of the difficulties and features that are commonly encountered in the analysis of environmental data. The stage will then be set for the statistics.
1.1 What is a Trend?
We have already defined trend analysis as the investigation of changes in a system over a period of time. However, this is rather a loose definition. The use of quantitative methods requires a precise statement of the scientific question(s) of interest, framed in numerical terms. We therefore consider the behaviour of a system to be encapsulated by the values of some collection of numeric variables (for example the mean global temperature or the numbers of reported incidents of respiratory illness in a particular location) through time. In the simplest case, the data available for the analysis of such a system might consist of a sequence of regularly spaced observations of a single variable taken at equal time intervals: y1,…, yT, say. Such data are often analysed using time series analysis techniques. In the time series literature, definitions of trend often refer to changes in the mean level of such a series. Chatfield (2003) defines trend in almost exactly these terms: ‘[Trend] may be loosely defined as “long-term change in the mean level”. ’ Kendall and Ord (1990) describe trend as ‘long-term movement’—again implying a change in the mean level.
Most modern statistical methods require that an observed sequence
y1,…,
yT is regarded as the realised value of a corresponding sequence
Y1,…,
YT of random variables. Equivalently, if all of the observations are assembled into a single column vector
(here and elsewhere, a prime ′ is used to denote the transpose of a vector or matrix), then
y is considered to be the realised value of a random vector
. This viewpoint, although perhaps surprising when seen for the first time, enables scientific questions to be framed, in completely unambiguous terms, as questions about the probability distribution from which the observations were drawn. Consider, for example, the expected values of the random variables
Y1,…,
YT:
where μt can be thought of as an ‘underlying’ mean of the process at time t. In some sense then, the sequence μ1,…, μT provides a formal mathematical representation of the notion of ‘change in the mean level’, and this sequence itself could be defined as the trend as in Diggle (1990, Section 1.4). If this definition of trend is accepted then, for example, the rather vague question ‘Is there a trend in my data?’ is equivale...