
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Statistics for Earth and Environmental Scientists
About this book
A host of complex problems face today's earth science community, such as evaluating the supply of remaining non-renewable energy resources, assessing the impact of people on the environment, understanding climate change, and managing the use of water. Proper collection and analysis of data using statistical techniques contributes significantly toward the solution of these problems. Statistics for Earth and Environmental Scientists presents important statistical concepts through data analytic tools and shows readers how to apply them to real-world problems.
The authors present several different statistical approaches to the environmental sciences, including Bayesian and nonparametric methodologies. The book begins with an introduction to types of data, evaluation of data, modeling and estimation, random variation, and sampling—all of which are explored through case studies that use real data from earth science applications. Subsequent chapters focus on principles of modeling and the key methods and techniques for analyzing scientific data, including:
-
Interval estimation and Methods for analyzinghypothesis testing of means time series data
-
Spatial statistics
-
Multivariate analysis
-
Discrete distributions
-
Experimental design
Most statistical models are introduced by concept and application, given as equations, and then accompanied by heuristic justification rather than a formal proof. Data analysis, model building, and statistical inference are stressed throughout, and readers are encouraged to collect their own data to incorporate into the exercises at the end of each chapter. Most data sets, graphs, and analyses are computed using R, but can be worked with using any statistical computing software. A related website features additional data sets, answers to selected exercises, and R code for the book's examples.
Statistics for Earth and Environmental Scientists is an excellent book for courses on quantitative methods in geology, geography, natural resources, and environmental sciences at the upper-undergraduate and graduate levels. It is also a valuable reference for earth scientists, geologists, hydrologists, and environmental statisticians who collect and analyze data in their everyday work.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
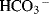
| Examples | |
| Continuous vs. Discrete Data | |
| Continuous: measurements can be made as fine as needed | Temperature, depth, sulfur content, well water yield |
| Discrete: data that can be categorized into a classification where only a finite number of values are possible, typically count data | Number of days above freezing, number of water wells producing among a sample of 50 holes |
| Ratio, Interval, Ordinal, and Nominal Data | |
| Ratio: continuous data where an interval and ratio are meaningful | Depth, sulfur content |
| Interval: continuous data with no natural zero | Temperature measured in degrees Celsius |
| Ordinal: data that are rank ordered | Survey responses such as good, fair, poor; water yields as high, medium, low |
| Nominal: Data that fit into categories; cannot be rank ordered | Location name, rock type |
Table of contents
- Cover
- Title Page
- Copyright
- Preface
- Chapter 1: Role of Statistics and Data Analysis
- Chapter 2: Modeling Concepts
- Chapter 3: Estimation and Hypothesis Testing on Means and Other Statistics
- Chapter 4: Regression
- Chapter 5: Time Series
- Chapter 6: Spatial Statistics
- Chapter 7: Multivariate Analysis
- Chapter 8: Discrete Data Analysis and Point Processes
- Chapter 9: Design of Experiments
- Chapter 10: Directional Data
- References
- Index
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app