Data mining is the process of automatically searching large volumes of data for models and patterns using computational techniques from statistics, machine learning and information theory; it is the ideal tool for such an extraction of knowledge. Data mining is usually associated with a business or an organization's need to identify trends and profiles, allowing, for example, retailers to discover patterns on which to base marketing objectives.
This book looks at both classical and recent techniques of data mining, such as clustering, discriminant analysis, logistic regression, generalized linear models, regularized regression, PLS regression, decision trees, neural networks, support vector machines, Vapnik theory, naive Bayesian classifier, ensemble learning and detection of association rules. They are discussed along with illustrative examples throughout the book to explain the theory of these methods, as well as their strengths and limitations.
Key Features:
Presents a comprehensive introduction to all techniques used in data mining and statistical learning, from classical to latest techniques.
Starts from basic principles up to advanced concepts.
Includes many step-by-step examples with the main software (R, SAS, IBM SPSS) as well as a thorough discussion and comparison of those software.
Gives practical tips for data mining implementation to solve real world problems.
Looks at a range of tools and applications, such as association rules, web mining and text mining, with a special focus on credit scoring.
Supported by an accompanying website hosting datasets and user analysis.
Statisticians and business intelligence analysts, students as well as computer science, biology, marketing and financial risk professionals in both commercial and government organizations across all business and industry sectors will benefit from this book.
This first chapter defines data mining and sets out its main applications and contributions to database marketing, customer relationship management and other financial, industrial, medical and scientific fields. It also considers the position of data mining in relation to statistics, which provides it with many of its methods and theoretical concepts, and in relation to information technology, which provides the raw material (data), the computing resources and the communication channels (the output of the results) to other computer applications and to the users. We will also look at the legal constraints on personal data processing; these constraints have been established to protect the individual liberties of people whose data are being processed. The chapter concludes with an outline of the main factors in the success of a project.
1.1 What is Data Mining?
Data mining and statistics, formerly confined to the fields of laboratory research, clinical trials, actuarial studies and risk analysis, are now spreading to numerous areas of investigation, ranging from the infinitely small (genomics) to the infinitely large (astrophysics), from the most general (customer relationship management) to the most specialized (assistance to pilots in aviation), from the most open (e-commerce) to the most secret (prevention of terrorism, fraud detection in mobile telephony and bank card applications), from the most practical (quality control, production management) to the most theoretical (human sciences, biology, medicine and pharmacology), and from the most basic (agricultural and food science) to the most entertaining (audience prediction for television). From this list alone, it is clear that the applications of data mining and statistics cover a very wide spectrum. The most relevant fields are those where large volumes of data have to be analysed, sometimes with the aim of rapid decision making, as in the case of some of the examples given above. Decision assistance is becoming an objective of data mining and statistics; we now expect these techniques to do more than simply provide a model of reality to help us to understand it. This approach is not completely new, and is already established in medicine, where some treatments have been developed on the basis of statistical analysis, even though the biological mechanism of the disease is little understood because of its complexity, as in the case of some cancers. Data mining enables us to limit human subjectivity in decision-making processes, and to handle large numbers of files with increasing speed, thanks to the growing power of computers.
A survey on the www.kdnuggets.com portal in July 2005 revealed the main fields where data mining is used: banking (12%), customer relationship management (12%), direct marketing (8%), fraud detection (7%), insurance (6%), retail (6%), telecommunications (5%), scientific research (4%), and health (4%).
In view of the number of economic and commercial applications of data mining, let us look more closely at its contribution to ‘customer relationship management’.
In today's world, the wealth of a business is to be found in its customers (and its employees, of course). Customer share has replaced market share. Leading businesses have been valued in terms of their customer file, on the basis that each customer is worth a certain (large) amount of euros or dollars. In this context, understanding the expectations of customers and anticipating their needs becomes a major objective of many businesses that wish to increase profitability and customer loyalty while controlling risk and using the right channels to sell the right product at the right time. To achieve this, control of the information provided by customers, or information about them held by the company, is fundamental. This is the aim of what is known as customer relationship management (CRM). CRM is composed of two main elements: operational CRM and analytical CRM.
The aim of analytical CRM is to extract, store, analyse and output the relevant information to provide a comprehensive, integrated view of the customer in the business, in order to understand his profile and needs more fully. The raw material of analytical CRM is the data, and its components are the data warehouse, the data mart, multidimensional analysis (online analytical processing1), data mining and reporting tools.
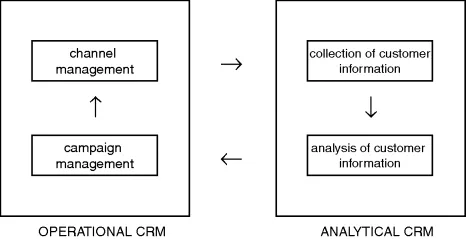
For its part, operational CRM is concerned with managing the various channels (sales force, call centres, voice servers, interactive terminals, mobile telephones, Internet, etc.) and marketing campaigns for the best implementation of the strategies identified by the analytical CRM. Operational CRM tools are increasingly being interfaced with back office applications, integrated management software, and tools for managing workflow, agendas and business alerts. Operational CRM is based on the results of analytical CRM, but it also supplies analytical CRM with data for analysis. Thus there is a data ‘loop’ between operational and analytical CRM (see Figure 1.1), reinforced by the fact that the multiplication of communication channels means that customer information of increasing richness and complexity has to be captured and analysed.
Figure 1.1 The customer relationship circuit.
The increase in surveys and technical advances make it necessary to store ever-greater amounts of data to meet the operational requirements of everyday management, and the global view of the customer can be lost as a result. There is an explosive growth of reports and charts, but ‘too much information means no information’, and we find that we have less and less knowledge of our customers. The aim of data mining is to help us to make the most of this complexity.
It makes use of databases, or, increasingly, data warehouses,2 which store the profile of each customer, in other words the totality of his characteristics, and the totality of his past and present agreements and exchanges with the business. This global and historical knowledge of each customer enables the business to consider an individual approach, or ‘one-to-one marketing’,3 as in the case of a corner shop owner ‘who knows his customers and always offers them what suits them best’. The aim of this approach is to improve the customer's satisfaction, and consequently his loyalty, which is important because it is more expensive (by a factor of 3–10) to acquire a new customer than to retain an old one, and the development of consumer comparison skills has led to a faster customer turnover. The importance of customer loyalty can be appreciated if we consider that an average supermarket customer spends about €200 000 in his lifetime, and is therefore ‘potentially’ worth €200 000 to a major retailer.
Knowledge of the customer is even more useful in the service industries, where products are similar from one establishment to the next (banking and insurance products cannot be patented), where the price is not always the decisive factor for a customer, and customer relations and service make all the difference.
However, if each customer were considered to be a unique case whose behaviour was irreducible to any model, he would be entirely unpredictable, and it would be impossible to establish any proactive relationship with him, in other words to offer him whatever may interest him at the time when he is likely to be interested, rather than anything else. We may therefore legitimately wish to compare the behaviour of a customer whom we know less well (for a first credit application, for example) with the behaviour of customers whom we know better (those who have already repaid a loan). To do this, we need two types of data. First of all, we need ‘customer’ data which tell us whether or not two customers resemble each other. Secondly, we need data relating to the phenomenon to be predicted, which may be, for example, the results of early commercial activities (for what are known as propensity scores) or records of incidents of payment and other events (for risk scores). A major part of data mining is concerned with modelling the past in order to predict the future: we wish to find rules concealed in the vast body of data held on former customers, in order to apply them to new customers and take the best possible decisions. Clearly, everything I have said about the customers of a business is equally applicable to bacterial strains in a laboratory, types of fertilizer in a plantation, chemical molecules in a test tube, patients in a hospital, bolts on an assembly line, etc. So the essence of data mining is as follows:
Data mining is the set of methods and techniques for exploring and analysing data sets (which are often large), in an automatic or semi-automatic way, in order to find among these data certain unknown or hidden rules, associations or tendencies; special systems output the essentials of the useful information while reducing the quantity of data.
Briefly, data mining is the art of extracting information – that is, knowledge – from data.
Data mining is therefore both descriptive and predictive: the descriptive (or exploratory) techniques are designed to bring out information that is present but buried in a mass of data (as in the case of automatic clustering of individuals and searches for associations between products or medicines), while the predictive (or explanatory) techniques are designed to extrapolate new information based on the pre...
Table of contents
Cover
Table of Contents
Title
Copyright
Dedication
Preface
Foreword
Foreword from the French language edition
List of trademarks
Chapter 1: Overview of data mining
Chapter 2: The development of a data mining study
Chapter 3: Data exploration and preparation
Chapter 4: Using commercial data
Chapter 5: Statistical and data mining software
Chapter 6: An outline of data mining methods
Chapter 7: Factor analysis
Chapter 8: Neural networks
Chapter 9: Cluster analysis
Chapter 10: Association analysis
Chapter 11: Classification and prediction methods
Chapter 12: An application of data mining: scoring
Chapter 13: Factors for success in a data mining project
Chapter 14: Text mining
Chapter 15: Web mining
Appendix A: Elements of statistics
Appendix B: Further reading
Index
End User License Agreement
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Data Mining and Statistics for Decision Making by Stéphane Tufféry in PDF and/or ePUB format, as well as other popular books in Mathematics & Probability & Statistics. We have over one million books available in our catalogue for you to explore.