
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Human Genetics and Genomics
About this book
This fourth edition of the best-selling textbook, Human Genetics and Genomics, clearly explains the key principles needed by medical and health sciences students, from the basis of molecular genetics, to clinical applications used in the treatment of both rare and common conditions.
A newly expanded Part 1, Basic Principles of Human Genetics, focuses on introducing the reader to key concepts such as Mendelian principles, DNA replication and gene expression. Part 2, Genetics and Genomics in Medical Practice, uses case scenarios to help you engage with current genetic practice.
Now featuring full-color diagrams, Human Genetics and Genomics has been rigorously updated to reflect today's genetics teaching, and includes updated discussion of genetic risk assessment, "single gene" disorders and therapeutics.
Key learning features include:
- Clinical snapshots to help relate science to practice
- 'Hot topics' boxes that focus on the latest developments in testing, assessment and treatment
- 'Ethical issues' boxes to prompt further thought and discussion on the implications of genetic developments
- 'Sources of information' boxes to assist with the practicalities of clinical research and information provision
- Self-assessment review questions in each chapter
Accompanied by the Wiley E-Text digital edition (included in the price of the book), Human Genetics and Genomics is also fully supported by a suite of online resources at www.korfgenetics.com, including:
- Factsheets on 100 genetic disorders, ideal for study and exam preparation
- Interactive Multiple Choice Questions (MCQs) with feedback on all answers
- Links to online resources for further study
- Figures from the book available as PowerPoint slides, ideal for teaching purposes
The perfect companion to the genetics component of both problem-based learning and integrated medical courses, Human Genetics and Genomics presents the ideal balance between the bio-molecular basis of genetics and clinical cases, and provides an invaluable overview for anyone wishing to engage with this fast-moving discipline.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Basic Principles of Human Genetics
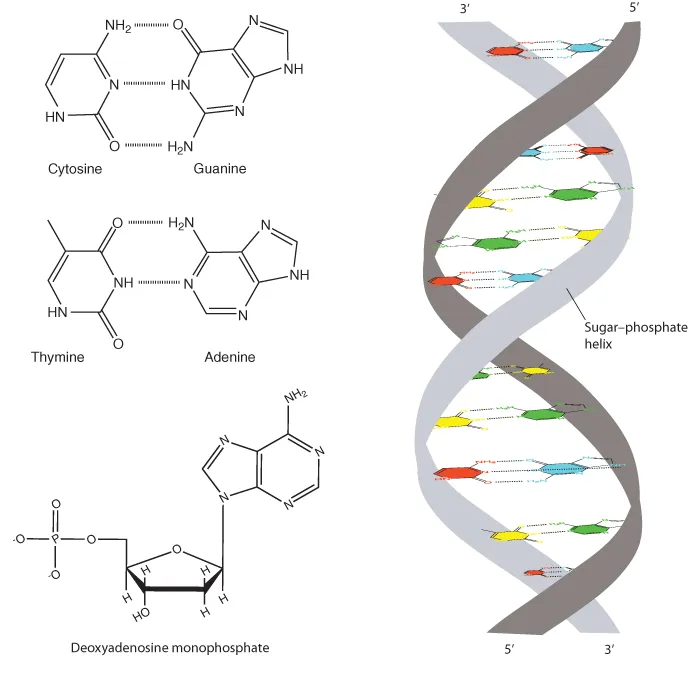
- DNA consists of a double-helical sugar–phosphate structure with the two strands held together by hydrogen bonding between adenine and thymine or cytosine and guanine bases.
- DNA replication involves local unwinding of the double helix and copying a new strand from the base sequence of each parental strand. Replication proceeds bidirectionally from multiple start sites in the genome.
- DNA is complexed with proteins to form a highly compacted chromatin fiber in the nucleus.
- Genetic information is copied from DNA into messenger RNA (mRNA) in a highly regulated process that involves activation or repression of individual genes.
- mRNA molecules are extensively processed in the nucleus, including removal of introns and splicing together of exons, prior to export to the cytoplasm for translation into protein.
- The base sequence of mRNA is read in triplet codons to direct the assembly of amino acids into protein on ribosomes.
- Some genes are permanently repressed by epigenetic marks such as methylation of cytosine bases. These include most genes on one of two X chromosomes in cells in females and one of the two copies of imprinted genes.
Deoxyribonucleic Acid

DNA Structure

DNA Replication
Table of contents
- Cover
- Dedication
- Title page
- Copyright page
- Preface
- How to get the best out of your textbook
- Part One: Basic Principles of Human Genetics
- Part Two: Genetics and Genomics in Medical Practice
- Answers to Review Questions
- Glossary
- Index
- Access to accompanying material
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app