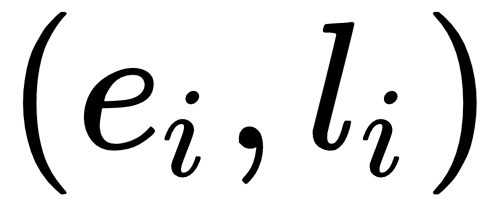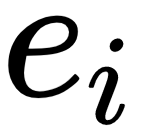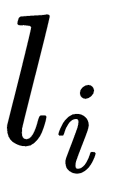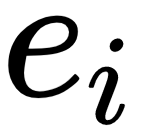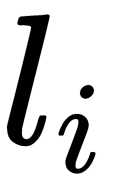Machine learning (ML) is an artificial intelligence branch where we define algorithms, with the aim of learning about a model that describes and extracts meaningful information from data.
Exciting applications of ML can be found in fields such as predictive maintenance in industrial environments, image analysis for medical applications, time series forecasting for finance and many other sectors, face detection and identification for security purposes, autonomous driving, text comprehension, speech recognition, recommendation systems, and many other applications of ML are countless, and we probably use them daily without even knowing it!
Just think about the camera application on your smartphone— when you open the app and you point the camera toward a person, you see a square around the person's face. How is this possible? For a computer, an image is just a set of three stacked matrices. How can an algorithm detect that a specific subset of those pixels represents a face?
There's a high chance that the algorithm (also called a model) used by the camera application has been trained to detect that pattern. This task is known as face detection. This face detection task can be solved using a ML algorithm that can be classified into the broad category of supervised learning.
ML tasks are usually classified into three broad categories, all of which we are going to analyze in the following sections:
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
Every group has its peculiarities and set of algorithms, but all of them share the same goal: learning from data. Learning from data is the goal of every ML algorithm and, in particular, learning about an unknown function that maps data to the (expected) response.
The dataset is probably the most critical part of the entire ML pipeline; its quality, structure, and size are key to the success of deep learning algorithms, as we will see in upcoming chapters.
For instance, the aforementioned face detection task can be solved by training a model, making it look at thousands and thousands of labeled examples so that the algorithm learns that a specific input corresponds with what we call a face.
The same algorithm can achieve a different performance if it's trained on a different dataset of faces, and the more high-quality data we have, the better the algorithm's performance will be.
In this chapter, we will cover the following topics:
- The importance of the dataset
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
![]()
Since the concept of the dataset is essential in ML, let's look at it in detail, with a focus on how to create the required splits for building a complete and correct ML pipeline.
A dataset is nothing more than a collection of data. Formally, we can describe a dataset as a set of
pairs,
, where
is
the
i-th
example
and
is
its label, with a finite
cardinality,
:
A dataset has a finite number of elements, and our ML algorithm will loop over this dataset several times, trying to understand the data structure, until it solves the task it is asked to address. As shown in Chapter 2, Neural Networks and Deep Learning, some algorithms will consider all the data at once, while other algorithms will iteratively look at a small subset of the data at each training iteration.
A typical supervised learning task is the classification of the dataset. We train a model on the data, making it learn that a specific set of features extracted from the
example
(or the example,
, itself) corresponds to a
label,
.
It is worth familiarizing yourself with the concept of datasets, dataset splits, and epochs from the beginning of your journey into the ML world so that you are already familiar with these concepts when we talk about them in the chapters that follow.
Right now, you already know, at a very high level, what a dataset is. But let's dig into the basic concepts of a dataset split. A dataset contains all the data that's at your disposal. As we mentioned previously, the ML algorithm needs to loop over the dataset several times and look at the data in order to learn how to solve a task (for example, the classification task).
If we use the same dataset to train and test the performance of our algorithm, how can we guarantee that our algorithm performs well, even on unseen data? Well, we can't.
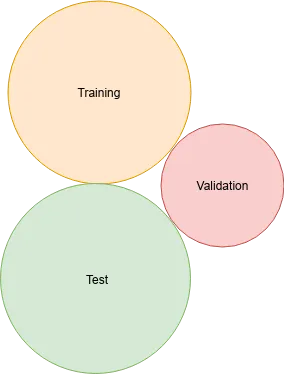
The most common practice is to split the dataset into three parts:
- Training set: The subset to use to train the model.
- Validation set: The subset to measure the model's performance during the training and also to perform hyperparameter tuning/searches.
- Test set: The subset to never touch during the training or validation phases. This is used only to run the final performance evaluation.
All three parts are disjoint subsets of the dataset, as shown in the following Venn diagram:
Venn diagram representing how a dataset should be divided no overlapping among the training, validation, and test sets is required
The training set is usually the bigger subset since it must be a meaningful representation of the whole dataset. The validation and test sets are smaller and generally the same size—of course, this is just something general; there are no constraints about the dataset's cardinality. In fact, the only thing that matters is that they're big enough for the algorithm to be trained on and represented.
We will make our model learn from the training set, evaluate its performance during the training process using the validation set, and run the final performance evaluation on the test set: this allows us to correctly define and train supervised learning algorithms that could generalize well, and therefore work well even on unseen data.
An epoch is the processing of the entire training set that's done by the learning algorithm. Hence, if our training set has 60,000 examples, once the ML algorithm uses...