
Reinforcement Learning Algorithms with Python
Learn, understand, and develop smart algorithms for addressing AI challenges
- 366 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Reinforcement Learning Algorithms with Python
Learn, understand, and develop smart algorithms for addressing AI challenges
About this book
Develop self-learning algorithms and agents using TensorFlow and other Python tools, frameworks, and libraries
Key Features
- Learn, develop, and deploy advanced reinforcement learning algorithms to solve a variety of tasks
- Understand and develop model-free and model-based algorithms for building self-learning agents
- Work with advanced Reinforcement Learning concepts and algorithms such as imitation learning and evolution strategies
Book Description
Reinforcement Learning (RL) is a popular and promising branch of AI that involves making smarter models and agents that can automatically determine ideal behavior based on changing requirements. This book will help you master RL algorithms and understand their implementation as you build self-learning agents.
Starting with an introduction to the tools, libraries, and setup needed to work in the RL environment, this book covers the building blocks of RL and delves into value-based methods, such as the application of Q-learning and SARSA algorithms. You'll learn how to use a combination of Q-learning and neural networks to solve complex problems. Furthermore, you'll study the policy gradient methods, TRPO, and PPO, to improve performance and stability, before moving on to the DDPG and TD3 deterministic algorithms. This book also covers how imitation learning techniques work and how Dagger can teach an agent to drive. You'll discover evolutionary strategies and black-box optimization techniques, and see how they can improve RL algorithms. Finally, you'll get to grips with exploration approaches, such as UCB and UCB1, and develop a meta-algorithm called ESBAS.
By the end of the book, you'll have worked with key RL algorithms to overcome challenges in real-world applications, and be part of the RL research community.
What you will learn
- Develop an agent to play CartPole using the OpenAI Gym interface
- Discover the model-based reinforcement learning paradigm
- Solve the Frozen Lake problem with dynamic programming
- Explore Q-learning and SARSA with a view to playing a taxi game
- Apply Deep Q-Networks (DQNs) to Atari games using Gym
- Study policy gradient algorithms, including Actor-Critic and REINFORCE
- Understand and apply PPO and TRPO in continuous locomotion environments
- Get to grips with evolution strategies for solving the lunar lander problem
Who this book is for
If you are an AI researcher, deep learning user, or anyone who wants to learn reinforcement learning from scratch, this book is for you. You'll also find this reinforcement learning book useful if you want to learn about the advancements in the field. Working knowledge of Python is necessary.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Section 1: Algorithms and Environments
- Chapter 1, The Landscape of Reinforcement Learning
- Chapter 2, Implementing RL Cycle and OpenAI Gym
- Chapter 3, Solving Problems with Dynamic Programming
The Landscape of Reinforcement Learning
- An introduction to RL
- Elements of RL
- Applications of RL
An introduction to RL
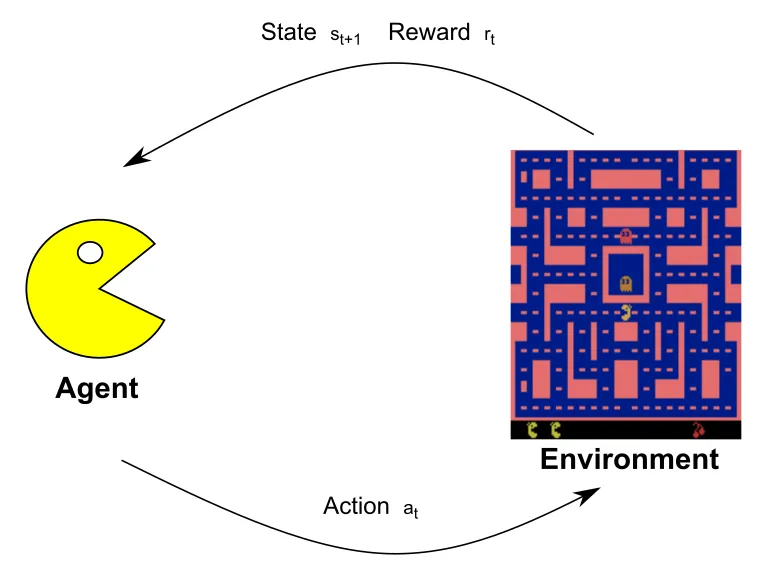
its lifetime. Let's simplify the notation: if


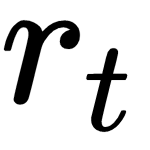


- Self-driving cars are a popular, yet difficult, concept to approach with RL. This is because of the many aspects to be taken into consideration while driving on the road (such as pedestrians, other cars, bikes, and traffic lights) and the highly uncertain environment. In this case, the self-driving car is the agent that can act on the steering wheel, accelerator, and brakes. The environment is the world around it. Obviously, the agent cannot be aware of the whole world around it, as it can only capture limited information via its sensors (for example, the camera, radar, and GPS). The goal of the self-driving car is to reach the destination in the minimum amount of time while following the rules of the road and without damaging anything. Consequently, the agent can receive a negative reward if a negative event occurs and a positive reward can be received in proportion to the driving time when the agent reaches its destination.
- In the game of chess, the goal is to checkmate the opponent's piece. In an RL framework, the player is the agent and the environment is the current state of the board. The agent is allowed to move the game pieces according to their own way of moving. As a result of an action, the environment returns a positive or negative reward corresponding to a win or a loss for the agent. In all other situations, the reward is 0 and the next state is the state of the board after the opponent has moved. Unlike the self-driving car example, here, the environment state equals the agent state. In other words, the agent has a perfect view of the environment.
Comparing RL and supervised learning
- The reward could be dense,...
Table of contents
- Title Page
- Copyright and Credits
- Dedication
- About Packt
- Contributors
- Preface
- Section 1: Algorithms and Environments
- The Landscape of Reinforcement Learning
- Implementing RL Cycle and OpenAI Gym
- Solving Problems with Dynamic Programming
- Section 2: Model-Free RL Algorithms
- Q-Learning and SARSA Applications
- Deep Q-Network
- Learning Stochastic and PG Optimization
- TRPO and PPO Implementation
- DDPG and TD3 Applications
- Section 3: Beyond Model-Free Algorithms and Improvements
- Model-Based RL
- Imitation Learning with the DAgger Algorithm
- Understanding Black-Box Optimization Algorithms
- Developing the ESBAS Algorithm
- Practical Implementation for Resolving RL Challenges
- Assessments
- Other Books You May Enjoy
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app