In the first half of this chapter, we’ll explore ways to talk about numbers in spreadsheets.
If you find the idea of numbers – with or without spreadsheets – a little intimidating, or if it’s been a while since you took a maths class, now would be a good time to take a look at this book’s Prologue: Review of Essential Mathematics. In that prologue, I refresh you with basic mathematical operations, order of operations, powers and exponents. I also help you start to think with numbers. This is a vital skill as you learn statistics, because it develops your sense of ‘that doesn’t look right’. Developing a ‘that doesn’t look right’ sense helps you avoid making silly mistakes, and silly mistakes with statistics can eventually be very costly for you and your business. So start early by reviewing the Prologue now if you haven’t already!
1.1.1 Datum, Data and Datasets
The general term for a single value collected in the context of research is a datum. A datum might be a number, letter or word. For example, a ‘2’ is a datum, but so is ‘yellow’ or ‘tall’ or even a ‘p’. When you are referring to more than one datum, you are referring to data. You might say, ‘take a look at this datum’ or ‘these data are interesting’.
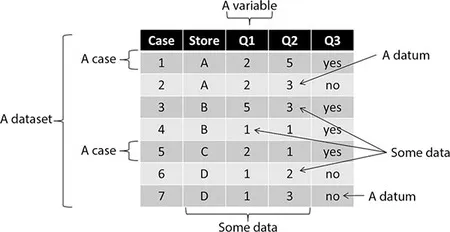
When multiple related data are collected in one place, a dataset is created. In our case study example, the spreadsheet that Ben received was a dataset, as it contained a great deal of data collected for a single purpose. A small piece of that dataset might have looked something like Figure 1.01.
Figure 1.01 Sample dataset with illustration of important chapter terms
This dataset contains many data. In the Q2 column in Figure 1.01, the first ‘3’ is a datum, but if we referred to both that 3 and the 3s below it, we are talking about data.
In fact, you can get a sense of whether or not someone is accustomed to working with real data themselves by whether or not they say ‘data is’ or ‘data are’. People that say ‘data is’, such as ‘the data is incoming’, think about data as a single thing, a resource to be utilized. These people rarely work with actual data, so you should interpret their perspective accordingly. People that actually work with data tend to say ‘data are’, such as ‘the data are complex’, because they think of each number, each letter, or each word of data as a unique piece of information that contributes to a larger complete picture. So that means as a business statistician-in-training, you should say ‘data are’.
Datasets can be further described with two other terms appearing in Figure 1.01: cases and variables. A variable is a collection of data with different values based upon its source, represented in a dataset as a column. For example, if you measured your height and the height of all of your friends, you have measured height as a variable. In Figure 1.01, Store, Q1, Q2 and Q3 are all variables.
If you remember anything from secondary/high school algebra and geometry, you probably remember the value called pi. This value is equal to 3.14159 …, with infinitely more numbers after the decimal. Pi is always this value. It never changes. Any time you see the word ‘pi’ or the symbol π, you know this is what it means. That is what makes pi a constant. If a value is not constant – or in other words, if it varies – it is a variable. When you see the word ‘height’, it could refer to your height, your friend’s height, the height of a building, or any height at all. That means height is a variable. In statistics, constants are generally used in formulas, and variables are usually parts of datasets.
So now that we have all these variables, how do we know which values were collected from the same source? A case is a group of data, collected across one or more variables from one source, represented in a dataset as a complete row. In Figure 1.01, Case 1 contains four data: an ‘A’ for the Store varia...