![]()
1 | Perspectives on Distributed Data Fusion David L. Hall |
CONTENTS
1.1 Introduction
1.2 Brief History of Data Fusion
1.3 JDL Data Fusion Process Model
1.4 Process Models for Data Fusion
1.5 Changing Landscape: Key Trends Affecting Data Fusion
1.6 Implications for Distributed Data Fusion
References
1.1 INTRODUCTION
Multisensor data fusion has an extensive history and has become a relatively mature discipline. Extensive investments in data fusion, primarily for military applications, have resulted in a number of developments: (1) the widely referenced Joint Directors of Laboratories (JDL) data fusion process model (Kessler et al. 1991, Steinberg et al. 1998, Hall and McMullen 2004); (2) numerous mathematical techniques for data fusion ranging from signal and image processing to state estimation, pattern recognition, and automated reasoning (Bar-Shalom 1990, 1992, Hall and McMullen 2004, Mahler 2007, Das 2008, Liggins et al. 2008); (3) systems engineering guidelines (Bowman and Steinberg 2008); (4) methods for performance assessment (Llinas 2008); and (5) numerous applications (see, for example, the Annual Proceedings of the International Conference on Information Fusion). Recent developments in communications networks, smart mobile devices (containing multiple sensors and advanced computing capability), and participatory sensing, however, lead to the need to address distributed data fusion. Changes in information technology (IT) introduces an environment in which traditional sensing/computing networks (e.g., for military command and control (C2) or intelligence, surveillance, and reconnaissance [ISR]) for well-defined situation awareness are augmented (and sometimes surpassed) by uncontrolled, ad hoc information collection. The emerging concept of participatory sensing is a case in point (Burke et al. 2006). For applications ranging from environmental monitoring to crisis management, to political events, information from ad hoc observers provide a huge source of information (albeit uncalibrated). Examples abound: (1) monitoring of the spread of disease by monitoring Google search terms, (2) estimation of earthquake events using Twitter feeds and specialized websites (U.S. Geological Survey (http://earthquake.usgs.gov) n.d.), (3) monitoring political events (http://ushahidi.com n.d.), (4) citizen crime watch (Lexington-Fayette Urban County Division of Police, see http://crimewatch.lfucg.com n.d.), (5) solicitation of citizens to report newsworthy events (Pitner 2012), and (6) use of citizens for collection of scientific data (Hand 2010). While ad hoc observers and open source information provide a huge potential resource of data and information, the use of such data are subject to many challenges such as establishing pedigree of the data, characterization of the observer(s), trustworthiness of the data, rumor effects, and many others (Hall and Jordan 2010).
Traditional information fusion systems involving user-owned and controlled sensor networks, an established system and information architecture for sensor tasking, data collection, fusion, dissemination, and decision making are being enhanced or replaced by dynamic, ad hoc information collection, dissemination, and fusion concepts. These changes provide both opportunities and challenges. Huge new sources of data are now available via global human observers and sensors feeds available via the web. These data can be accessed and distributed globally. Increasingly capable mobile computing and communications devices provide opportunities for advanced processing algorithms to be implemented at the observing source. The rapid creation of new mobile applications (APPs) may provide new algorithms, cognitive aids, and information access methods “for free.” Finally, advances in human–computer interaction (HCI) provide opportunities for new engagement of humans in the fusion process, as observers, participants in the cognition process, and collaborating decision makers. However, with such advances come challenges in design, implementation, and evaluation of distributed fusion systems.
This book addresses four key emerging concepts of distributed data fusion. Chapters 1, 2, 3 introduce concepts in network centric information fusion including the design of distributed processes. Chapters 4, 5, 6, 7, 8 address how to perform state estimation (viz., estimation of the position, velocity, and attributes of observed entities) in a distributed environment. Chapters 9, 10, 11, 12 focus on target/entity identification and on higher level inferences related to situation assessment/awareness and threat assessment. Finally, Chapters 13 through 18 discuss the implementation environment for distributed data fusion including emerging concepts of service-oriented architectures, test and evaluation of distributed fusion systems, and aspects of human engineering for human-centered fusion systems. The remainder of this chapter provides a brief history of data fusion, an introduction to the JDL data fusion process model, a review of related fusion models, a discussion of emerging trends that affect distributed data fusion, and finally a discussion of some perspectives on distributed fusion.
1.2 BRIEF HISTORY OF DATA FUSION
The discipline of information fusion has a long history, beginning in the 1700s with the posthumous publication of Bayes’ theorem (1763) on probability and Gauss’ development of the method of least squares in 1795 to estimate the orbit of the newly discovered asteroid Ceres using redundant observations (redundant in the mathematical sense meaning more observations than was strictly necessary for a minimum data, initial orbit determination). Subsequently, extensive research has been applied to develop methods for processing data from multiple observers or sensors to estimate the state (viz., position, velocity, attributes, and identity) of entities. Mathematical methods in data fusion (summarized in Kessler et al. [1991], Hall and McMullen [2004], and many other books) span the range from signal and image processing methods to estimation methods, pattern recognition techniques, automated reasoning methods, and many others. Such methods have been developed during the entire time period from 1795 to the present.
A brief list of events in the history of information fusion is provided in the following:
• Publication of Bayes’ theorem on probability (1763)
• Gauss’ original development of mathematics for state estimation using redundant data (1795)
• Development of statistical pattern recognition methods (e.g., cluster analysis, neural networks, etc.) (early 1900s–1940s)
• Development of radar as a major active sensor for target tracking and identification (1940s)
• Development of the Kalman filter (1960) for sequential estimation
• Implementation of U.S. Space Track system (1961)
• Development of military focused all-source analysis and fusion systems (1970s–present)
• First demonstration of the Advanced Research Project Agency computer network (ARPANET)—the precursor to the Internet (1968)
• First cellular telephone network (1978)
• National Science Foundation Computer Science Network (CSNET) (1981)
• Formation of JDL data fusion subpanel (mid-1980s)
• Creation of JDL process model (1990)
• Tri-Service Data Fusion Symposium (1987)
• Formation of the annual National Symposium on Sensor Fusion (NSSDF) (1988)
• Second generation mobile cell phone systems (early 1990s)
• Commercialization of the Internet (1995)
• Creation of the International Society of Information Fusion (ISIF) (1999)
• Annual ISIF Fusion Conferences (since 1998)
• Emergence of nonmilitary applications (1990s to present), including condition monitoring of complex systems, environmental monitoring, crisis management, medical applications, etc.
• Emergence of participatory sensing to augment physical sensors (1990s)
While basic fusion algorithms have been well known for decades, the routine application of data fusion methods for real-time problems awaited the emergence of advanced sensing systems and computing technologies that allowed semi-automated processing. Automated fusion of data fusion requires a combination of processing algorithms, computers capable of executing the fusion algorithms, deployed sensor systems, communication networks to link the sensors and computing capabilities, and systems engineering methods for effective system design, development, deployment, and test and evaluation. Similarly, the emergence of distributed data fusion systems involving hard (physical sensor) data and human (soft) observations requires a combination of new fusion algorithms, computing capabilities, communications systems, global use of smart phones and computing devices, and the emergence of a net-centric generation who routinely makes observations, tweets, reports, and shares such information via the web.
1.3 JDL DATA FUSION PROCESS MODEL*
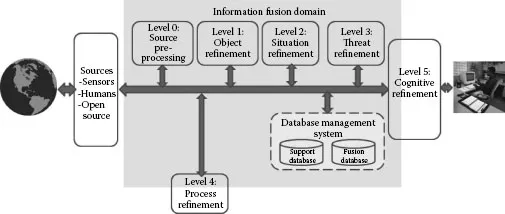
In the early 1990s, a number of U.S. DoD large-scale funded efforts were underway to implement data fusion systems. An example was the U.S. Army’s All Source Analysis System (ASAS) (Federation of American Scientists [www.fas.org/]). The field of data fusion was emerging as a separate discipline, with limited common understanding of terminology, algorithms, architectures or engineering processes. JDL was an administrative group created to assist in coordinating research across the U.S. Department of Defense laboratories. The JDL established a subgroup to focus on issues related to multisensor data fusion. The formal name was the Joint Directors of Laboratories, Technical Panel for Command, Control and Communications (C3) data fusion subpanel. This subgroup created the JDL data fusion process model (see Figure 1.1). The model was originally published in a briefing (Kessler et al. 1991) to the Office of Naval Intelligence and later presented in papers, used as an organizing concept for books (Hall and McMullen 2004, Liggins et al. 2008), national and international conferences, government requests for proposals, and in a few cases government and industrial research organizations. The original briefing (Kessler et al. 1991) presented a hierarchical, three-layer model. The top part of the model is shown in Figure 1.1. For each of the fusion “levels,” a second layer identified specific subprocesses and functions, while a third layer identified subfunctions and candidate algorithms to perform those functions. These sublayers are described in Hall and McMullen (2004).
FIGURE 1.1 Top le...