
- 358 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Revival: Processing of RNA (1983)
About this book
In a fast-moving field it is unlikely that articles written more than a year ago would be completely up to date. The purpose of this book is to bring to the nonspecialist an overall view as well as an update on the state of the art as it existed in the beginning of 1982, and to the specialist the opportunity to have a single source of information for how the other organisms do it, and also to enable him to find out the status of the various aspects of RNA processing with which he might not be to familiar. even if only some of these goals are achieved, all those who labored so diligently to bring about the publication of this book would be more than gratified.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Chapter 1
PROTEIN-POLYNUCLEOTIDE RECOGNITION AND THE RNA PROCESSING NUCLEASES IN PROKARYOTES
Norman R. Pace
Table of Contents
- I. Introduction
- II. Protein-Polynucleotide Contacts
- A. Electrostatic Contacts
- B. Hydrogen Bond Contacts
- C. Hydrophobic and Stacking Interactions
- III. The Known Prokaryotic Processing Nucleases
- A. A Summary of Known and Suspected Processing Events and Enzymes
- B. The Substrate Problem
- C. RNase III
- D. RNases “M16” and “M23”
- E. RNases M5 and E
- F. RNase P
- G. RNase D
- H. The Selective Decay of RNA
- I. A Comment on RNA Processing Pathways
- References
I. Introduction
Several recent review articles,1,2 including some in this volume, consider the properties of the few RNA processing enzymes on which we have information. This paper, as well, will survey the known prokaryotic RNA processing enzymes, but not in exhaustive detail. Rather, the author feels it useful to devote much of the available space to a consideration of the features of polynucleotides with which proteins may specifically interact. The fact is that we know little about the molecular details of any specific protein-polynucleotide complex, and the RNA processing enzymes offer excellent models for exploring these. The collection of references used is not intended to be all-inclusive, but rather, generally, to provide access to this literature.
II. Protein-Polynucleotide Contacts
None of the RNA processing enzymes is sufficiently well characterized to encourage even speculation on the detailed character of substrate recognition. We are, however, accumulating a reasonably detailed picture of the sorts of interactions which probably occur. It seems of use, therefore, to draw the discussion of substrate recognition a bit further than simple consideration of nucleotide sequences, even in some folded form. The paradigm offered by the sequence-specific DNA restriction endonucleases may have lulled us into overconfidence regarding our abilities to recognize in RNA the same complex information that proteins do, so the chemical details of possible protein-nucleic acid interactions must be borne in mind as we attempt to ferret out the targets of the processing nucleases.
Protein surfaces contact polynucleotide surfaces. We therefore must consider a recognition/manipulation process in terms of matrices of complementary contacts between the interacting molecules; the unique geometry possible among multiple contacts provides the overall specificity of the interaction. The important questions to pose, then, are (1) what chemical groups in the nucleic acids are potential binding contacts for proteins; and (2) what is their relationship to the surface, i.e., to an interacting protein? We consider, in passing, DNA as well as RNA because they often are considered to be informationally equivalent molecules. Although the similarities are considerable, these two nucleic acids also offer some strikingly different structural and chemical aspects which are instructive to consider. Moreover, sometimes our knowledge regarding certain aspects of protein-nucleic acid interactions is limited to DNA, so that is presented as exemplary.
Except for tRNA, the most detailed structural information that we have on polynucleotides involves the regular double helices.3,5 These are of concern, here, because RNA processing sites often are found in regions of high secondary structure.
In general, duplex DNA adopts the familiar “B-form” helix under physiological conditions. Certain deoxynucleotide sequences can assume other helical forms (A, D, Z, etc.), but the bulk of the cellular DNA probably is in the B-form. Somewhat in contrast, largely because of conformational constraints imposed by the ribose 2′-OH groups, duplex RNA assumes the A-form of helix. Space-filling projections of the canonical A- and B-form helices and the positioning of the base pairs about the axes are shown in Figures 1 and 2. For the purposes of this discussion, important points to note regarding these structures are the following: bear in mind that the local structures of the polynucleotides probably are very mushy and readily molded by interacting proteins.
- The periodicity and orientation of the negatively charged phosphate groups differ in the two forms. DNA-B offers a somewhat narrower profile and about 10 nucleotide pair phosphates per 34-Å turn. Phosphate groups project outward from the helix cylinder in DNA-B, but are more tucked into the RNA-A helix, partly blocking the wide groove (Figure 1).
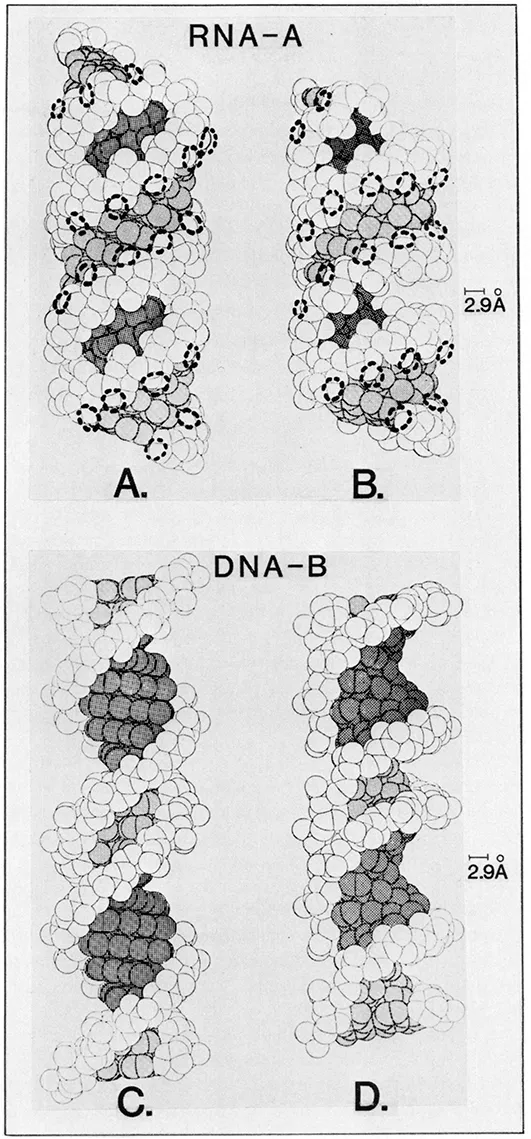 FIGURE 1. Space-filling views of A-RNA (A and B) and B-DNA (C and D) helices. In panels B and D the helices are tilted about 30° to reveal the depths of the helix grooves. Dark shading indicates the wide groove and light shading the narrow groove. In panels A and B, the approximate hydrogen bonding radii of the ribose 2′-OH groups are indicated by dashed circles. The 2.9-Å bar indicates the optimal negative-to-negative center distance for a hydrogen bond contact. (Modified from Alden C. J. and Kim, S.-H., J. Mol. Biol., 132, 411, 1979.)
FIGURE 1. Space-filling views of A-RNA (A and B) and B-DNA (C and D) helices. In panels B and D the helices are tilted about 30° to reveal the depths of the helix grooves. Dark shading indicates the wide groove and light shading the narrow groove. In panels A and B, the approximate hydrogen bonding radii of the ribose 2′-OH groups are indicated by dashed circles. The 2.9-Å bar indicates the optimal negative-to-negative center distance for a hydrogen bond contact. (Modified from Alden C. J. and Kim, S.-H., J. Mol. Biol., 132, 411, 1979.) - The displacement of the base pairs from the RNA-A helix axis (Figure 2A) defines a very deep, wide groove, which is most evident upon tilting the projection, as seen in Figure 1B. The depth of the wide groove and the barrier offered by the overhanging phosphate groups mean that the base-pair functional groups in the RNA-A wide groove are virtually inaccessible from the surface of the helix. The narrow groove of the RNA-A helix, on the other hand, is superficial (Figures 1 and 2). In DNA-B, because the base pairs are stacked along the helix axis (Figure 2B), both the wide and narrow grooves, in principle, are available to probing groups from an interacting protein.
- 3. The RNA-A narrow groove is populated by the ribose 2′-OH groups, which are important H-bond donors (Figures 1 and 2). In terms of information content, the 2′-OH groups are a major contrast between RNA and DNA.
Alden and Kim6 (see also Pullman and Pullman8) have provided a more detailed theoretical picture of the information available in the base pairs of the A- and B-form helices by calculating the accessibilities of their various functional groups to “hard-shell” probes of various sizes. Their findings are that, for probe radii greater than 3 Å (amino acids), the helix wide groove contains the most accessible base contacts available in B-form DNA, and only the narrow groove of RNA-A has significant base exposure. The phosphate and 2′-OH groups are freely available.
Considerably less attention has been given to crystallographic analysis of “single-strand” polynucleotides than to the duplexes. It is clear from these and other studies, however, that unpaired sequences are far from disordered. Even without the constraints of a complementary pairing, single-strand sequences adopt ordered, helical arrays, stabilized mostly by intramolecular base stacking. Poly A, for example, crystallizes as a right-hand helical structure with about 9 residues per 25-Å repeat;9 poly C collapses into a 6 base per 18.5-Å repeat helix.10 Only poly U seems to be substantially unstacked, but is still highly ordered by the conformational constraints of the phosphodiester backbone.11 In contrast to the regular duplex helices, all of the potential interaction sites for proteins would seem to be freely available in these “single-strand” structures.
Paired sequences containing RNA processing sites often are imperfect complements, containing unpaired or non-Watson-Crick base pairs (G.U, G.A, etc.), or out-of-register complements. At least these latter presumably would yield structures containing bulge loops or extrahelical bases, but little is known regarding their details and how they reflect into adjacent regions. Since protein contacts on the bases seem to be sterically very limited in the regular RNA-A helix, any irregularities within the helices may be important to focus upon in comparative analyses of processing enzyme substrate sites.
Four somewhat overlapping classes of contacts between proteins and polynucleotides can be envisaged.12–14 These are (1) electrostatic interactions, (2) hydrogen bonding, (3) hydrophobic interactions, and (4) stacking interactions. The most important contributions to protein-polynucleotide binding energies probably are the electrostatic and hydrogen bonds. Stacking and hydrophobic interactions probably are not substantial as proteins confront duplex polynucleotides, but they offer interesting possibilities in considering irregular (non-duplex) nucleic acid conformations or in cases where the nucleic acid conformation is significantly perturbed. Let us consider, now, how these potential contacts are arranged in space in the nucleic acids, and the protein groups which may interact with them.
A. Electrostatic Contacts
Electrostatic interactions are diverse in energy and type; they include the strong ionic contacts afforded by basic amino acids countering the negatively charged phosphate groups in the nucleic acids as well as a hierarchy of weaker and less-defined dipole interactions. Nucleotide sequences should be viewed not simply as a string of letters, but as some array of partial charges. Figure 3 illustrates the partial charge distribution in the base rings. The intensity of any particular local charge of course is very dependent upon the environment of the base, i.e., its stacking neighbors as well as its association with the solvent, ions, etc.
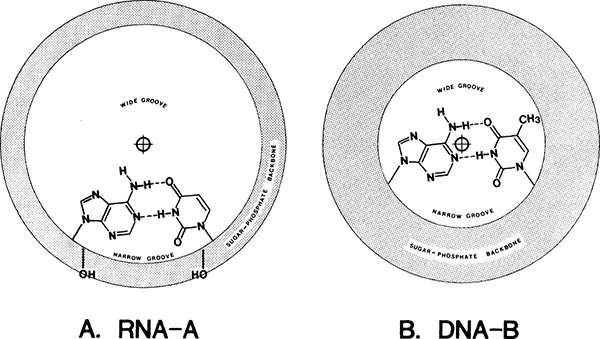
FIGURE 2. The relationships of the base pairs to the RNA-A and DNA-B helix axes. (Modified from Bloomfield, V. A., Crothers, D. M., and Tinoco, I., Jr., Physical Chemistry of the Nucleic Acids, Harper & Row, New York, 1974, 125.)
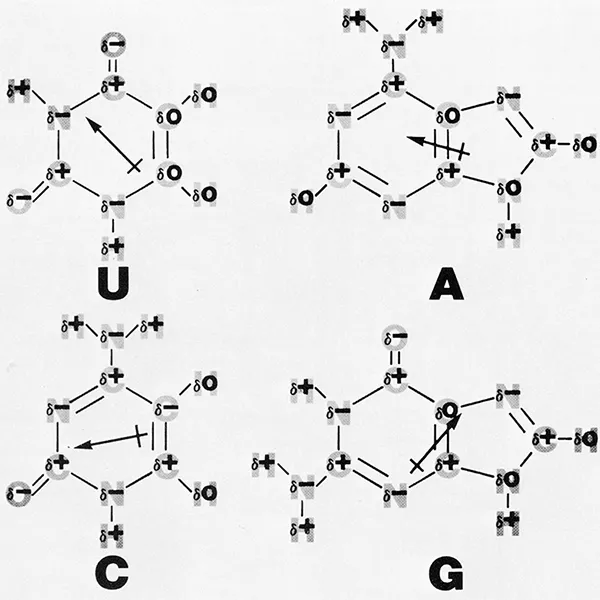
FIGURE 3. The partial cha...
Table of contents
- Cover Page
- Title Page
- Copyright Page
- Contents
- Chapter 1 Protein-Polynucleotide Recognition and the RNA Processing Nucleases in Prokaryotes
- Chapter 2 Molecular Biology of RNA Processing in Prokaryotic Cells
- Chapter 3 Processing of Bacteriophage-Coded RNA Species
- Chapter 4 Genetic and Biochemical Studies of RNA Processing in Yeast
- Chapter 5 5′ Terminal Cap Structures of Eukaryotic and Viral mRNAs
- Chapter 6 Poly(A) in Eukaryotic mRNA
- Chapter 7 Processing of mRNA Precursors in Eukaryotic Cells
- Chapter 8 Animal Virus RNA Processing
- Chapter 9 Ribosomal RNA Processing in Eukaryotes
- Chapter 10 RNA Synthesis and Processing in Mitochondria
- Chapter 11 Modified Nucleosides in RNA — Their Formation and Function
- Epilogue
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Revival: Processing of RNA (1983) by David Apirion in PDF and/or ePUB format, as well as other popular books in Biological Sciences & Biology. We have over one million books available in our catalogue for you to explore.