
- 250 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
The EM Algorithm and Related Statistical Models
About this book
Exploring the application and formulation of the EM algorithm, The EM Algorithm and Related Statistical Models offers a valuable method for constructing statistical models when only incomplete information is available, and proposes specific estimation algorithms for solutions to incomplete data problems. The text covers current topics including statistical models with latent variables, as well as neural network models, and Markov Chain Monte Carlo methods. It describes software resources valuable for the processing of the EM algorithm with incomplete data and for general analysis of latent structure models of categorical data, and studies accelerated versions of the EM algorithm.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
1
Incomplete Data and the Generation Mechanisms
Michiko Watanabe
Toyo University, Tokyo, Japan
1 INCOMPLETE DATA PROBLEMS
In many cases of actual data analysis in various fields of applications, the data subject to the analysis are not acquired as initially planned. Data that have not been obtained in complete form as intended are called incomplete data. The incompleteness of data may take various forms. For example, part of the information may be observed, as in cases where the actual observation being sought may not be completely observed but is known to be greater than a certain value. On the contrary, no information may be obtained at all. A typical example of the former is censoring in survival time data, whereas the latter is treated as missing data.
The enhancements in software tools for statistical analysis for personal computers in recent years have led to an environment in which anyone can apply methods of statistical analysis to the process of data processing relatively easily. However, many statistical software still require that there are no missing values in the data subject to analysis, i.e., the completeness of data is a prerequisite for application. Even those that have missing value processing as an optional function are limited to processing at simple levels, such as excluding all incomplete observations, or substituting a missing value with the mean value. Additionally, the preparedness of statistical software for data incompleteness depends on the method of analysis applied, as exemplified for survival analysis; many statistical software packages are capable of analyzing censored data as well.
However, as stated before, the occurrence of missing data is an inevitable problem when collecting data in practice. In particular, as the number of items subject to survey or experiments increases, the number of so-called complete observations (cases in which the data is recorded with respect to all items) decreases. If you exclude all incomplete observations and then simply conduct statistical analysis only with respect to complete observations, the estimates obtained as a result will become less efficient and unexpected biases will arise, severely undermining the reliability of the analysis results. In other words, it is generally vital to exercise more caution with respect to incomplete data, in light of the reliability of analysis results. This chapter reviews the mechanism by which missing values generate, which should be considered first in regard to the ‘‘missing’’ problem, which is the most coMmon among all incomplete data.
How should missing values be processed, and how should the results be interpreted? When dealing with these questions, it is important to understand why the values are missing in the first place. Of course, there are cases in which there is no information as to why the values are missing. In such cases, it is necessary to employ a method of analysis that is suitable for cases that lack such information. If the mechanism by which missing values arise is known, the top priority is to determine whether the mechanism needs to be taken into account or whether it could be ignored when conducting an analysis.
Consider an ordinary random sample survey as a simple case in which the mechanism by which missing values generate can be ignored when conducting an analysis. In this case, the variables to be considered are those subject to the survey items and a variable defining the sampling frame. Assuming that the data on these variables in the population are complete data, the sample data can be regarded as incomplete data in which all survey variables relating to the subjects of the survey that have not been included in the sample are missing. The only variable that is observed completely is the variable that defines the sampling frame.
If sampling is done randomly, there is no need to incorporate those that have not been observed into the analysis, and it is permissible to conduct an analysis targeting the sample data only. In other words, the mechanism by which the missing values arise (= the sampling mechanism) can be referred to as an ‘‘ignorable’’ mechanism upon analysis, because the missing values arise without any relation to the value of the variables that might have been observed.
On the other hand, if you are observing the time taken for a certain phenomenon (e.g., death, failure, or job transfer) to occur, you might know that the phenomenon has not occurred up until a certain point of time, but not the precise time at which it occurred; such data are called censored data. As the censored data are left with some information, that the phenomenon occurred after a certain period, it is risky to completely ignore them in the analysis as it might lead to biased results. In short, the mechanism by which missing values arise that derives censored data is a ‘‘nonignorable’’ mechanism.
For another example of a nonignorable mechanism, in a clinical study on clinical effects conducted over a certain period targeting outpatients, the data on patients who stopped seeing a doctor before the end of the period cannot simply be excluded as missing data. This is because the fact that the patient stopped seeing a doctor might contain important information relating to the effect of the treatment, e.g., the patient might have stopped seeing the doctor voluntarily because the patient quickly recovered, or might have switched to another hospital due to worsening symptoms. It is also necessary to exercise caution when handling missing data if the measuring equipment in use cannot indicate values above (or below) a certain threshold due to its accuracy, and uncollected data if the data are either adopted or rejected depending on the size of the variables.
In this manner, it is important to determine whether the mechanism by which missing values arise can be ignored when processing the missing values. The next section shows a statistical model of such a mechanism, and then strictly defines ‘‘missing at random’’ and ‘‘observed at random’’ based on this model and explains when the mechanism can be ignored, i.e., sets forth the conditions for cases in which it is acceptable to exclude the incomplete observations including missing values and cases in which such crude exclusions lead to inappropriate analysis results.
2 GENERATION MECHANISMS BY WHICH MISSING DATA ARISE
Generally, the fact that a value is missing might in itself constitute information on the value of the variables that would otherwise have been observed or the value of other variables. Therefore, the mechanism by which missing values arise need to be considered when processing incomplete data including missing values. Thus, incomplete data including missing values require the modeling of a mechanism by which missing values arise, and the incorporation of the nature of missing values as part of the data in the analysis.
Now, suppose the multivariate data is the observed value of a random variable vector X = (X1, X1, . . . , Xp)V following a multivariate density function f(x; h). The objective of analysis for the time being is to estimate a parameter h that defines the function f. Now, introduce, a new random variable vector v = (M1, M2, . . . , Mp)V corresponding to observed variable vector X. v is an indexVector indicating whether the elements X are missing or observed: that is, Xi is observed whenMi=1, andXi is not observed (i.e., missinη) whenMi=0. In other words, the observed value v of missing indexVector Mshows the missingness pattern of observed data.
Modeling of a mechanism by which missing values arise concretely defines the conditional probability g(m; x, f) of a certain observed value v of M, given the observed value x of X. Here, f is a parameter that defines the mechanism.
If the output variable through the mechanism by which missing data arise is represented by random variable V=(V1, V2, . . . ,Vp)V, each element of which is defined as Vi = Xi when mi = 1 and Vi = * when mi = 0, the data acquired is v, which is the observed value of V. This also means that a missingness pattern v and xV = (xV(0), xV(1)) corresponding thereto are realized, where x(0) and x(1) indicate the vectors of the missing part and the observed part, respectively, in X corresponding to m. Estimation of q should be done based on such v in a strict sense.
If you ignore the mechanism by which missing values arise g(m; x, f), you assume that the observed part x(1) is an observation from the marginal density
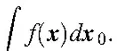
1
On the other hand, if you take into account the mechanism by which missing values arise, it is actually from the following density function
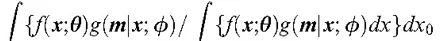
2
The mix-up of the two densities in formulae (1) and (2) will give rise to a nonignorable bias in the estimation of q depending on g(m; x, f).
For example, suppose there is a sample of size n for a variable, and only values that are larger than the population mean are observed. Assuming that q is the population mean and f = q, the mechanism by which only values that are larger than the population mean are actually observed is represented by
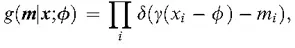
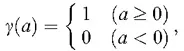
where
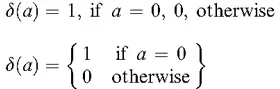
In this case, if q is estimated based on density function (1) ignoring g(m; x, /), it is obvious that the estimation will be positively skewed.
Generally, the mechanism by which missing values arise cannot be ignored. However, if certain conditions are met by the mechanism, Formulae (1) and (2) become equal such that the mechanism becomes ignorable. In this regard, Rubin (1976) suMmarized the characteristics of the mechanism as follows.
- Missing at random (MAR). MAR indicates that given the condition that the observed part x(1) is fixed at any specific value, for any unobserved part x(0), the mechanism by which missing values arise becomes the constant, that is,
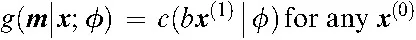 In other words, MAR means that the missingness pattern v and the unobserved part x(0) are conditionally independent given the observed part x(1).
In other words, MAR means that the missingness pattern v and the unobserved part x(0) are conditionally independent given the observed part x(1). - Observed at random (OAR). OAR indicates that given the condition that the unobserved part x(0) is fixed at any specific value, for any observed part x(1), the mechanism by which missing values arise becomes the constant, that is,
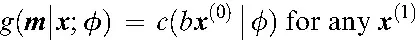
- f is distinct from q. This indicates that the joint parameter space of f and q factorizes into each parameter space, and the prior distribution of f is independent of that of q.
In regard to the above description, Rubin (1976) gives the following theorems concerning the condition that the mechanism that leads to the missingness can be ignorable.
Theorem 1. In case that we infer the objective parameter q based on the sampling distribution for the incomplete data that have missing values, we can ignore the missingness mechanism g(mjx; f) under the condition that both MAR and OAR are met, which is called missing completely at random (MCAR).
In other words, MCAR means that the missingness pattern v and the objective variable x are unconditionally independent such that the deletion of all incomplete observations that have missing values, which is one of the simplest means to process incomplete data, leads no inference bias.
Theorem 2. In case that we infer the objective parameter q based on the likelihood for the incomplete data, we can ignore the missingness mechanism g(mjx; f) under the condition that MAR and the distinctness of f from q are satisfied.
Theorem 3. In case that we infer the objective parameter q via a Bayesian method for the incomplete data, we can ignore the missingness mechanism g(mjx; f) under the condition MAR and the distinctness of f from q are satisfied.
In regard to the results given by Rubi...
Table of contents
- COVER PAGE
- TITLE PAGE
- COPYRIGHT PAGE
- STATISTICS: TEXTBOOKS AND MONOGRAPHS
- PREFACE
- CONTRIBUTORS
- 1: INCOMPLETE DATA AND THE GENERATION MECHANISMS
- 2: INCOMPLETE DATA AND THE EM ALGORITHM
- 3: STATISTICAL MODELS AND THE EM ALGORITHM
- 4: ROBUST MODEL AND THE EM ALGORITHM
- 5: LATENT STRUCTURE MODEL AND THE EM ALGORITHM
- 6: EXTENSIONS OF THE EM ALGORITHM
- 7: CONVERGENCE SPEED AND ACCELERATION OF THE EM ALGORITHM
- 8: EM ALGORITHM IN NEURAL NETWORK LEARNING
- 9: MARKOV CHAIN MONTE CARLO
- APPENDIX A: SOLASTM 3.0 FOR MISSING DATA ANALYSIS
- APPENDIX B: S
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access The EM Algorithm and Related Statistical Models by Michiko Watanabe,Kazunori Yamaguchi in PDF and/or ePUB format, as well as other popular books in Computer Science & Programming Algorithms. We have over one million books available in our catalogue for you to explore.