
- 524 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
Basic Orthopaedic Sciences
About this book
Following on from the highly successful first edition, published in 2006, the second edition of Basic Orthopaedic Sciences has been fully updated and revised, with every chapter rewritten to reflect the latest research and practice. The book encompasses all aspects of musculoskeletal basic sciences that are relevant to the practice of orthopaedics and that are featured and assessed in higher specialty exams. While its emphasis is on revision, the book contains enough information to serve as a concise textbook, making it an invaluable guide for all trainees in orthopaedics and trauma preparing for the FRCS (Tr & Orth) as well as for surgeons at MRCS level, and other clinicians seeking an authoritative guide.
The book helps the reader understand the science that underpins the clinical practice of orthopaedics, an often neglected area in orthopaedic training, achieving a balance between readability and comprehensive detail. Topics covered include biomechanics, biomaterials, cell & microbiology, histology, structure & function, immunology, pharmacology, statistics, physics of imaging techniques, and kinesiology.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
1 | Statistics |
 | ||
Nominal | Categories without order, e.g. eye colour | Non-parametric |
Binomial | 2 possible outcomes, e.g.dead/alive, success/failure, heads/tails | Non-parametric |
Ordinal | Categories with order, e.g. small/medium/large | Non-parametric |
Integer | Ordered scale of whole numbers (no fractions or divisions), e.g. screw lengths (22 mm, 24 mm, 26 mm…) | Non-parametric or parametric |
Interval | Ordered numerical measurement with subdivisions, e.g. height, weight, volume | Parametric |
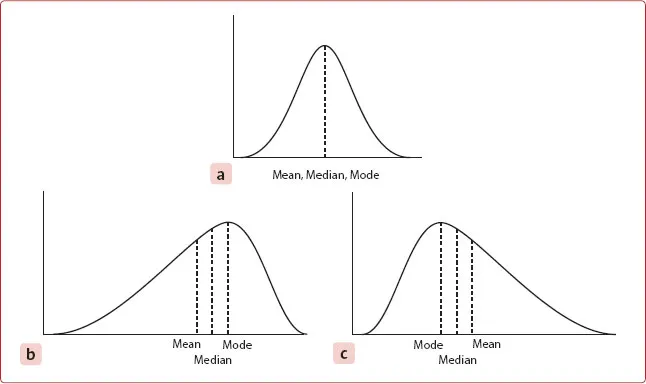
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Dedication
- Table of Contents
- Contributors
- Preface to Second Edition
- Preface to First Edition
- Foreword to First Edition
- Acknowledgements in the First Edition
- Abbreviations
- 1 Statistics
- 2 Genetics
- 3 Skeletal Embryology and limb growth
- 4 Orthopaedic Pharmacology
- 5 Inflammation and Infection
- 6 Imaging Techniques
- 7 Orthopaedic Oncology
- 8 Ligament and Tendon
- 9 Meniscus
- 10 Articular Cartilage
- 11 Nerve
- 12 Skeletal Muscle
- 13 Basics of Bone
- 14 Bone Injury, Healing and Grafting
- 15 Intervertebral Disc
- 16 Basic Concepts in Biomechanics
- 17 Biomaterial Behaviour
- 18 Biomaterials
- 19 Biomechanics and Joint Replacement of the Hip
- 20 Biomechanics and Joint Replacement of the Knee
- 21 Biomechanics of the Spine
- 22 Biomechanics and Joint Replacement of the Shoulder and Elbow
- 23 Biomechanics of the Hand and Wrist
- 24 Biomechanics and Joint Replacement of the Foot and Ankle
- 25 Friction, Lubrication, Wear and Corrosion
- 26 Gait
- 27 Prosthetics
- 28 Orthotics
- 29 Inside the Operating Theatre
- 30 Basic Science of Osteoarthritis
- 31 Biomechanics of Fracture Fixation
- Appendix
- Index
Frequently asked questions
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app