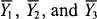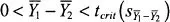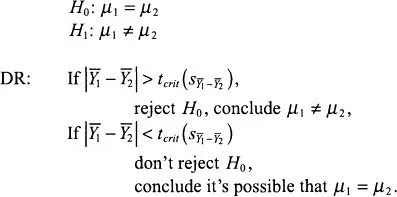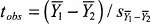![]() Suggested Alternatives to Significance Testing
Suggested Alternatives to Significance Testing![]()
Chapter 6
Reforming Significance Testing via Three-Valued Logic
Richard J. Harris
University of New Mexico
The many and frequent misinterpretations of null hypothesis significance testing (NHST) are fostered by continuing to present NHST logic as a choice between only two hypotheses. Moreover, the proposed alternatives to NHST are just as susceptible to misinterpretation as is (two-valued) NHST. Misinterpretations could, however, be greatly reduced by adopting Kaiser’s (1960) proposal of three-alternative hypothesis testing in place of the traditional two-alternative presentation. The real purpose of significance testing (NHST) is to establish whether we have enough evidence to be confident of the sign (direction) of the effect we’re testing in the population. This is an important contribution to the cumulation of scientific knowledge and should be retained in any replacement system. Confidence intervals (CIs—the proposed alternative to significance tests in single studies) can provide this control, but when so used they are subject to exactly the same Type I, Type II, and Type III (statistical significance in the wrong direction) error rates as significance testing. There are still areas of research where NHST alone would be a considerable improvement over the current lack of awareness of error variance. Further, there are two pieces of information (namely, maximum probability of a Type III error and probability of a successful exact replication) provided by p values that are not easily gleaned from confidence intervals. Suggestions are offered for greatly increasing attention to power considerations and for eliminating the positive bias in estimates of effect-size magnitudes induced when we make statistical significance a necessary condition of publication.
Null hypothesis significance testing (NHST1) as applied by most researchers and journal editors can provide a very useful form of social control over researchers’ understandable tendency to “read too much” into their data, that is, to waste their readers’ and their own time providing elaborate explanations of effects whose sign (direction)2 in this sample may not match the sign of the corresponding population effect. So used, NHST becomes an essential tool in determining whether the available evidence (whether from a single study or from a metaanalysis) provides us with sufficient confidence in the sign of an effect to warrant foisting upon readers elaborate explanations of why the effect points in that particular direction. This is a valuable contribution which must be retained in any replacement system.
However, NHST can be employed for this purpose only by ignoring the way in which its logical structure is presented in almost all of our textbooks—namely, as a choice between two mutually exclusive hypotheses. For instance, the fourth edition of the Publication Manual of the American Psychological Association (APA, 1994) specifies that “When reporting inferential statistics (one should) include information about… the direction of the effect” (p. 15)—a recommendation with which very few researchers would disagree. Yet, as Kaiser (1960) (first?) pointed out, a researcher who adheres to the two-valued logic of the traditional two-tailed test can never come to any conclusion about the direction of the effect being tested, and a researcher who instead employs a one-tailed test can never come to the conclusion that the predicted sign of the effect (without which prediction a one-tailed test would of course be unjustifiable) is wrong, that is, that, under the conditions of this particular study or meta-analysis the effect goes in the direction opposite to prediction. The researcher who takes traditional NHST logic seriously is thus faced with the unpalatable choice between being unable to come to any conclusion about the sign of the effect (if a two- or split-tailed test is used) and violating the most basic tenet of scientific method (empirical data as the arbiter of our conclusions) by declaring his or her research hypothesis impervious to disconfirmation (if a one-tailed test is used).
In the remainder of this chapter I argue that:
1. The many and frequent misinterpretations of null hypothesis significance testing are fostered by continuing to present NHST logic as a choice between only two hypotheses.
2. These misinterpretations could, however, be greatly reduced by adopting Kaiser’s (1960) proposal of three-alternative hypothesis testing in place of the traditional two-alternative presentation.
3. What appear to be the proposed alternatives to NHST are just as susceptible to misinterpretation as is (two-valued) NHST.
4. The real purpose of significance testing (NHST) is to establish whether we have enough evidence to be confident of the (direction) of the effect we’re testing in the population. H0 is tested (in a reductio-ad-absurdum spirit) only because if we can’t rule out zero as the magnitude of our population effect size, we also can’t rule out small negative and small positive values, and thus don’t have enough evidence to be confident of the sign of the population effect and shouldn’t waste readers’ time expounding on the processes that produce a particular direction of effect.
5. The aforementioned is an important contribution to the cumulation of scientific knowledge—essentially, providing social control over researchers’ tendency to “read too much” into their sample results, and should be retained in any replacement system. Confidence intervals (CIs—the proposed alternative to significance tests in single studies) can indeed provide this control, provided that we put the same restrictions and caveats on interpretation of effects whose CIs include zero (or some other null-hypothesized value) as we currently do on statistically nonsignificant results.
6. When the sign-determination function of significance testing is replaced by the is-zero-included? use of CIs, the Cl-based procedure becomes subject to exactly the same Type I, Type II, and Type III (statistical significance in the wrong direction) error rates as significance testing.
7. Any system of social control must be evaluated against the available alternative(s). Although NHST supplemented by reporting of CIs is clearly superior to NHST by itself, there are still areas of research (e.g., Monte Carlo simulations, some meta-analysis claims) where NHST alone would be a considerable improvement over the current lack of awareness of error variance.
8. There are two pieces of information (namely, maximum probability of a Type III error and probability of a successful exact replication) provided by p values that are not easily gleaned from confidence intervals.
9. Attention to power considerations could be greatly increased by adoption of the very simple MIDS (Minimally Important Difference Significant) and FEDS (Fraction of Expected Difference Significant) criteria (Harris & Quade, 1992) for sample size, together with reporting of CIs as a supplement to significance tests.
10. The positive bias in estimates of effect-size magnitudes induced by making statistical significance a necessary condition of publication is an inevitable consequence of any system of social control over our pursuit of random variation. Rather than abandoning such control, we should provide mechanisms whereby the methods and results sections of studies yielding no statistically significant results can be archived (sans interpretations) for use in subsequent meta-analyses.
INCONSISTENCY BETWEEN TWO-ALTERNATIVE NHST AND SOUND RESEARCH PRACTICE
For simplicity’s sake, we examine the case of a two sample independent means t test (testing the statistical significance of the difference between the means of two separate groups), and assume that we have predicted that μ1 > μ2. The points made here are, however, perfectly generalizable to the case where we predict that μ1 < μ2 and to any other single-degree-of-freedom hypothesis test, such as testing a contrast within an analysis of variance (ANOVA) or testing a 2×2 contingency table.
First, let’s review two-valued (traditional) logic. In what follows I will use
H0 and
H1 to stand for the null and alternative hypotheses (to be expanded to include a second alternative hypothesis
H2 when we come to three-valued logic);
μ1,
μ2, and
μ3 to stand for the means of the populations from which the samples used to compute
(the sample means) were drawn; and “DR” as the label for the
decision rule that maps the various possible values of our test statistic into conclusions about the sign of
μ1 –
μ2 on the basis of the observed value of our
t ratio (
tobs), relative to its critical value,
tcrit.
Two-Valued (Traditional) Logic
One-Tailed Test
Note that we can not conclude that
μ1 is ≤
μ2 because, for example,
is more supportive of
μ1 >
μ2 than it is of
μ1 <
μ2.
Two-Tailed Test
Note that we never conclude that μ1 does equal μ2 exactly, because our sample mean difference is almost never exactly zero and thus lends greater support to nonzero values than to a population mean difference of zero. In empirical research the null hypothesis that two population means are precisely equal is almost certainly false. (If you doubt this, consider a thought experiment involving an n of 10,000,000. Do you seriously doubt that every sample mean difference or correlation, no matter how small, will yield two-tailed statistical significance at the .01 level or beyond?)
Note, too, that the two-tailed test can be applied whether or not we have made a prediction about the direction of the population difference, whereas the one-tailed test can be carried out only if a specific prediction has been made as to whether μ1 > μ2 or vice versa.
Split-Tailed Test (cf. Braver, 1975)
Here
tcrit,pred is set to yield some value >
α/2 (so as to give us a better chance of declaring statistically significant a sample difference in the predicted direction), whereas
tcrit,opp.pred is set to a value that yields an
α equal to our desired overall
α minus the
α associated with
tcrit,pred. For example, we might set
αpred to .049 and
αopp.pred to .001. (This latter choice leads, for very large
N, to rejecting (
is either larger than 1.6546 or smaller than −3.0903.)
Reviewing the preceding outline of two-valued NHST leads to the following conclusions:
Conclusions with Respect to Two-Valued Logic:
1. Nowhere in two-valued hypothesis-testing logic is there any provision for concluding that the data provide statistically significant evidence against our research hypothesis. Scanning the decis...