This volume is the result of a conference held at the University of California, Irvine, on the topics that provide its title -- choice, decision, and measurement. The conference was planned, and the volume prepared, in honor of Professor R. Duncan Luce on his 70th birthday. Following a short autobiographical statement by Luce, the volume is organized into four topics, to each of which Luce has made significant contributions.
The book provides an overview of current issues in each area and presents some of the best recent theoretical and empirical work. Personal reflections on Luce and his work begin each section. These reflections were written by outstanding senior researchers: Peter Fishburn (Preference and Decision Making), Patrick Suppes (Measurement Theory and Axiomatic Systems), William J. McGill (Psychophysics and Reaction Time), and W.K. Estes (Choice, Identification and Categorization).
The first section presents recent theoretical and empirical work on descriptive models of decision making, and theoretical results on general probabilistic models of choice and ranking. Luce's recent theoretical and empirical work on rank- and sign-dependent utility theory is important in many of these contributions. The second section presents results from psychophysics, probabilistic measurement, aggregation of expert opinion, and test theory. The third section presents various process oriented models, with supportive data, for tasks such as redundant signal detection, forced choice, and absolute identification. The final section contains theory and data on categorization and attention, and general theoretical results for developing and testing models in these domains.

- 488 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
PART 1
INTRODUCTION
THE PAST SEVEN YEARS: 1988-95
University of California, Irvine
Key words and phrases. Scale type, joint receipt, rank-dependent utility, sign-dependent utility, relation of riskless and risky utility, weighting functions.
Acknowledgments. I thank A. A. J. Marley and Peter Fishburn for useful comments on an earlier draft of these remarks. Also, I appreciate Dr. Marley’s efforts in bringing about this volume.
Address for correspondence. R. Duncan Luce, Institute for Mathematical Behavioral Sciences, Social Science Plaza, University of California, Irvine, CA 92697-5100. Email: [email protected]
ABSTRACT. In 1989 my then scientific autobiography (Luce, 1989) concluded: “At that point [early 1988] I did take early retirement from Harvard, but the next five to ten years promise not to be idle.” These few pages take up the ensuing seven years, which indeed have not been idle. (Perhaps the problem is that I’ve never taken up golf.) For example, 32 papers have appeared in journals and book chapters, half a dozen are in various pre-publication stages, and three books have appeared: the much belated volumes II and III of the Foundations of Measurement (Luce, Krantz, Suppes, & Tversky, 1990; Suppes, Krantz, Luce, & Tversky, 1989) and a textbook, based on the core course given at Harvard and repeated several times at UCI, Sound & Hearing (Luce, 1993). Although favorably reviewed, it has not spawned the courses I had hoped it might.
1. RESEARCH THEMES
During the period from 1975 through the late 1980’s roughly half of my work centered on the representational (or axiomatic or algebraic) theory of measurement. Although we are far from completing that program of research – witness the list of 15 open problems suggested in Luce and Narens (1994) – much of my research energy has shifted from the abstract themes to more concrete attempts to apply what we have learned about measurement theory to empirically interesting problems. Several things lay behind the shift: criticism of representational measurement as seemingly irrelevant to substantive issues, e.g. Cliff (1992), but also see Narens and Luce (1993), my own scientific disposition to develop theory that makes empirical predictions and to test these, and perhaps some attenuation of my abstract skills which is said to occur with age – although occasionally it seems to be less of an issue than is commonly believed, witness, e.g., Patrick Suppes. In any event, beginning with Luce (1988), I began participating in the rather lively developments in our understanding of how to measure utility.
Applications of Measurement Theory to Utility Theory. Much recent economic literature on individual decision making under risk1 and under uncertainty has focused on how to adapt the subjective expected utility (SEU) model of Savage (1954) to some of the empirical findings that seem to undermine the basic tenets of rationality embodied in that model. Two main avenues have been pursued. One, mostly followed by economists and well summarized by one of its originators J. Quiggin (Quiggin, 1993), focused on weakening what economists call the independence axiom, which is explicated below, and deriving from modifications of that axiom and the other axioms new forms of the numerical representation. The other tack, mostly pursued by psychologists, involved directly modifying the SEU representation to accommodate some of the empirical anomalies. The most important example of this approach was D. Kahneman and A. Tversky’s prospect theory (Kahneman & Tversky, 1979) which, beyond doubt, has been more widely cited than any other paper in this area in the past few decades. It seemed to me that both approaches had significant difficulties, and part of my effort was to try to overcome them.
Economists often begin by restricting the domain of alternatives to lotteries: money consequences with known probabilities. They interpret such lotteries as random variables with probability distributions over money. That seems innocent enough, a mere mathematical notation for a lottery. But, empirically, it isn’t innocent at all for the following simple reason. Suppose X and Y are random variables and A is a probability, i.e., a number between 0 and 1. Then
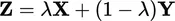
is the mixture random variable having the distribution
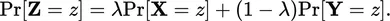
The mathematics of random variable theory automatically reduces any compound mixture lottery to its equivalent first order form. No distinction is made among compound random variables having the same bottom line. It is unlikely that people treat them as the same, and substantial empirical data support differential treatment except for the simplest reductions. Nonetheless, that strong assumption is built into the meaning of random variables.
The problem is illustrated vividly by the following example of consequence monotonicity and its reduced form in the case of random variable representations. Suppose g, g′, and h are lotteries (not interpreted as random variables) and λ, 0 < λ < 1, is a probability. Then a compound lottery can be formed as (g, λ; h), meaning that when the chance experiment underlying λ is run, one receives g with probability λ and h with probability 1 − λ. Let g ≿ h denote a weak preference ordering, where g ≻ h denotes that g is strictly preferred to h, g ~ h denotes that g and h are indifferent, and ≿ = ≻ ∪ ~. A major assumption of rational behavior in many theories, called consequence monotonicity, is:
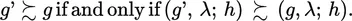 | (1) |
In words, replacing one consequence by another that is viewed as better improves matters. Now, suppose we think of g,g′, and h as random variables, say X, X′, and Y, respectively. Then in the usual random variable notation we write the above condition as:
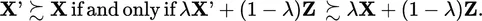 | (2) |
This property is called the independence axiom. The problem is that although it seems equivalent to consequence monotonicity, it really is not because it also assumes that one can reduce the compound form to its equivalent first order form. No such property holds for consequence monotonicity unless it is explicitly assumed.
Early in the history of utility theory for lotteries, M. Allais (Allais, 1953) described a compelling thought experiment where people violate independence; subsequently this and variants on it were confirmed experimentally (for summaries of much empirical work concerning the SEU model, see Schoemaker, 1982, 1990). Despite the fact that others, e.g. Brothers (1990) and Kahneman and Tversky (1979), provided evidence that, when the compound lotteries are presented without reduction to their first order form, consequence monotonicity holds, economists have continued to model alternatives as random variables and attempted to weaken the independence property. It seemed obvious to me that one should be very cautious, indeed, about invoking the reduction property of random variables, in which case it might be possible to retain the highly rational property of consequence monotonicty2. That observation has been one of three foundation stones of my work.
A second foundation stone, hardly original, is that the distinction between gains and losses matters greatly. The economist H. Markowitz (Markowitz, 1952) and the psychologist W. Edwards (Edwards, 1962) were among the first to emphasize that fact and to point out that the extant theories ignored it. But once again the paper that made a real difference on this score was Kahneman and Tversky (1979). The issue of how gains and losses are to be defined is still far from resolved. In experiments we typically treat no exchange of money to define the status quo, and any addition to the status quo is a gain and any reduction from it is a loss. But we are acutely aware that this is inadequate. For a person desperately in need of $100, a “net win” of $50 in an evening at a casino may functionally seem more like a loss than a gain. More commonly, a choice set of gambles may define a temporary status quo somewhere between the smallest and largest possible consequences.
So the problem has been partitioned into developing theories in which the status quo is assumed to exist and gains and losses are carefully distinguished and in working out theories to describe how the status quo or reference levels are constructed. The former theories are by now rather well developed. But, for all practical purposes, no work on the latter has begun in any serious way. I have been unable to come up with a useful empirical way to estimate reference levels and, beyond what is in Luce, Mellers, and Chang (1993), I know of no theoretical proposals. L. L. Lopes has studied experimentally the impact of various distributions of money on reference levels (Lopes, 1984, 1987).
The third foundation stone is the observation that utility can be constructed for riskless consequences3 using a binary operation rather than studying the trade-off between consequences and chance, which has been the basis of all theories of weighted or expected utilities. The operation, which I have called joint receipt, is the simplest thing in the world. You often receive two or more things at once: checks and bills in the mail, gifts on birthdays and holidays, purchases when shopping, etc. The key fact is that if x and y are valued objects, then their joint receipt, which I denote by x ⊕ y, is also a valued “object.” This basis for measurement is much like that underlying the measurement of mass, and indeed the pan balance analogy seems quite close.
These are the ideas that I have been able to pursue with some success. The details are far too complex to cover here in detail, but the main outlines are describable. Let e denote the status quo and consider for the moment just gains, i.e., consequences x such that x ≿ e. We assume, in all cases, that e ∼ (e, E; e) and that the utility function ...
Table of contents
- Cover
- Half Title
- Title Page
- Copyright Page
- Table of Contents
- Preface
- List of Contributors
- List of Referees
- PART 1. Introduction
- PART 2. Decision Making and Risk
- PART 3. Preference, Measurement Theory, and Axiomatic Systems
- PART 4. Psychophysics and Response Time
- PART 5. Choice and Categorization
- PART 6. Scientific Publications of R. Duncan Luce
- References
- Author Index
- Subject Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Choice, Decision, and Measurement by A.A.J. Marley in PDF and/or ePUB format, as well as other popular books in Psychology & Experimental Psychology. We have over 1.5 million books available in our catalogue for you to explore.