![]()
FROM SOUND TO MEANING
A FRAMEWORK FOR ANALYSING COMPREHENSION
Language is so readily acquired and so universal in human affairs that it is easy to forget what a complex phenomenon it is. Despite years of research, we still understand remarkably little about how language works. Consider the problems there have been in developing computers that can process human language. What an advantage it would be to have an automatic system that could listen to a person talking and translate their speech into a written form—a combined Dictaphone and word processor that did all the work of an audio-typist. Technology is now advancing to the stage where this kind of machine is possible, but it has taken more than 30 years of intensive research to achieve this goal, and the best contemporary speech recognition devices are less good than a four-year-old child at recognising a stream of continuous speech spoken by an unfamiliar speaker. Suppose, though, we try to crack a different problem: rather than getting a machine to recognise spoken words, let us present it with ready-typed sentences, and see if it can decode meaning well enough to translate from one language to another. Here too, enormous effort has been expended in trying to achieve a solution, yet the results so far are unimpressive (see Machine translation, overleaf). One thing that makes language comprehension such an intriguing topic is that it is something that computers are relatively bad at, despite their enormous power and speed of operation. Against this background, it is all the more remarkable that nearly all children soak up language in the first few years of life, apparently requiring only a modest amount of linguistic stimulation in order to develop, by the age of four years or so, into language users who are far more competent than the most sophisticated computer.
This chapter will set the scene for the rest of the book by giving a preliminary overview of the different stages involved in comprehension. In Chapter 2, we turn to consider what is known about children with a specific language impairment (SLI), many of whom have difficulty in learning to understand as well as to produce language. The later chapters explore individual processes in more detail and ask how far a deficit at a specific level might be the root of the language difficulties seen in children with SLI. Although the emphasis is on understanding, abnormalities of children's expressive language will also be discussed, insofar as these help illuminate the types of linguistic representations that might be affected in SLI.
MACHINE TRANSLATION
In the 1950s, there was optimism that computers would readily be able to tackle the task of translating between languages. All that would be required would be knowledge of vocabulary and grammar of source and target languages and rules for converting one to another. It was only when computer scientists began to tackle this task that we started to appreciate just how much understanding of meaning depends on general knowledge as well as the words in a sentence. A high proportion of the words in a language are ambiguous, as was illustrated in a famous example by the philosopher Bar-Hillel (cited in Arnold, Balkan, Humphreys, Meijer, & Sadler, 1994), who noted the problems that would be encountered by a machine translation system confronted with a sequence such as:
Little Peter was looking for his toy box. The box was in the pen.
To interpret this correctly, one needs to have knowledge of the relative size of typical pens and boxes, to recognise that it would be well nigh impossible to put a box in a pen, as in Fig. 1.1, below, and to appreciate that in the context of a small child, ‘pen’ can refer to a playpen. Bar-Hillel's view was that computers could never be given sufficient knowledge to deal with this kind of problem, and so machine translation was doomed.
Ambiguity is also found in the grammar of a language. For instance, computer programs designed to translate technical manuals can have difficulty with a sentence such as:
Put the paper in the printer and then switch it on.
Humans have sufficient knowledge of paper and printers to realise that ‘it’ must be the printer, but for a program equipped with only vocabulary and grammatical rules, this would be ambiguous.
Despite these difficulties, machine translation systems have been developed to do a reasonable ‘first pass’ translation in a specific domain, such as weather reports or timetable enquiries. However, they cope poorly when presented with material outside the subject area for which they have been adapted. Cheap, nonspecialised translation devices that are on the market for use with personal computers may produce output that gives the gist of a meaning, but they have a long way to go before they can match a human translator, as illustrated by this example from Arnold et al. (1994).
Source text (German Teletext travel news)
Summerurlauber an den Küsten Südeuropas oder der Ost- und Nordsee müssen vereinzelt mit Beeinträchtigungen des Badespasses rechnen.
An der Adria wird bei Eraclea Mare und Caorle wegen bakterieller Belastungen vom Baden abgeraten.
Computer translation
Summer vacationers at the coasts of South Europe or the east- and North Sea must calculate isolated with impairments of the bath joke.
At the Adria Mare and Caorle is dissuaded at Eraclea because of bacterial burdens from the bath.
Stages and representations
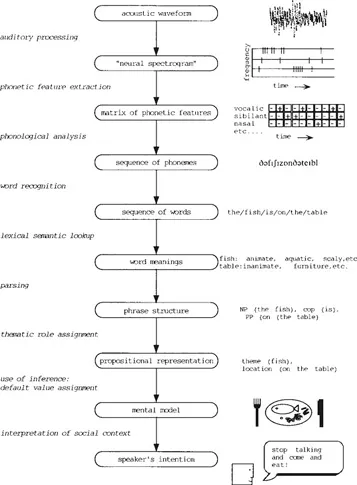
Figure 1.2 depicts a simplified model of the stages involved in processing a spoken message from acoustic waveform to meaning. This kind of model conceptualises comprehension as a process whereby information is successfully transformed from one kind of representation to another. Initially, the information is available in the form of a complex acoustic signal. This is encoded into a phonological representation which retains all the linguistically salient detail, but ignores other information, dramatically reducing the amount of information to be processed. Phonological representations then make contact with long-term representations in a mental lexicon, enabling one to associate a given sound pattern with meaning. As we proceed down the information-processing chain, our representation becomes increasingly abstract and remote from the surface characteristics in the original signal. This type of information-processing model became popular in the 1960s and, although it has limitations which will become apparent as we proceed, it is still widely used in neuropsychology, where it provides a useful framework for distinguishing the different levels at which a cognitive process may be disrupted. We shall illustrate the model by tracing through the mental representations that are generated by the listener on hearing the utterance ‘The fish is on the table’.
FIGURE 1.2 Model of the stages of processing involved in transforming a sound wave into meaning when comprehending the utterance ‘the fish is on the table’. In this model, comprehension is depicted as a purely ‘bottom-up’ process, with incoming information being subject to successive transformations in sequential order. As we shall see, this is a gross oversimplification.
Speech recognition
Someone speaks, and a sound wave is generated. This is converted in the ear into a neural signal which then is processed by the brain and interpreted by the listener as a meaningful message. Chapter 3 is concerned with the first three stages of information processing shown in Fig. 1.2, from ‘auditory processing’, through to ‘phonological analysis’.
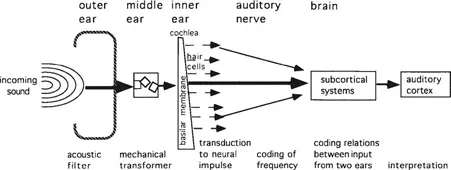
Figure 1.3 shows a simplified representation of the stages involved in converting an acoustic signal (i.e. a sound waveform) into an auditory form
FIGURE 1.3 Schematic diagram of initial stages of auditory processing of incoming speech. For a more detailed account see Evans (1992).
(i.e. a neural representation). A mechanical transformation of the signal is carried out in the middle ear, with neural encoding achieved in the inner ear. Vibrations of the basilar membrane in the cochlea stimulate the hair cells, which feed impulses into the auditory nerve. A neurally encoded representation of the frequency and intensity characteristics of the sound is conveyed via the auditory nerve and subcortical systems to the auditory cortex of the brain. In the auditory cortex there are brain cells that fire selectively in response to sounds of specific frequencies, as well as others that respond to changes in frequency over a given range or direction (Kay & Matthews, 1972). The brain thus maps sound into a neural representation that contains crucial information about the amount of energy in different frequency bands and its rate of change, a so-called ‘neural spectrogram’.
The usual use of the term ‘spectrogram’ is to describe a visual representation of frequency and intensity of an acoustic signal over time (see Spectrograms, overleaf). Figure 1.5 shows a spectrogram of the utterance ‘the fish is on the table’. The first thing that is apparent is that the signal is not neatly chunked into words: gaps are as likely to occur within a word as at a word boundary. The perceptual experience of a sequence of individual words is achieved by the brain's interpretative processes which convert a continuous stream into discrete units. (We become all too aware of this when listening to an unfamiliar language; when we can't identify the words, speech is perceived as both rapid and continuous.) There are other problems that the listener has to contend with in interpreting a speech signal. The characteristics of the acoustic signal will vary from speaker to speaker, and will vary for the same speaker depending on such factors as speech rate or emotional state. Furthermore, speech typically occurs against background noise: the listener has to extract the critical speech material from a welter of acoustic information. Cocktail parties are well-loved by psychologists, not just for their social and alcoholic possibilities, but because they demonstrate so convincingly the human capacity to attend to a single speech stream against a babble of background chatter.
SPECTROGRAMS
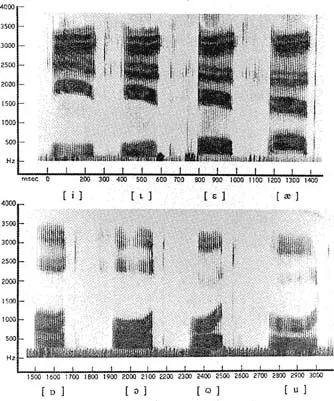
The spectrograph is a device that converts speech signals into a three-dimensional visual representation, the spectrogram. Variations in intensity (which are perceived as changes in loudness) are represented by the darkness of the trace, with the most intense being the blackest. Variations in frequency are represented on the y-axis, and time is shown on the x-axis.
The spectrograms in Fig. 1.4 show the sound patterns corresponding to syllables differing by a single vowel.
In the 1950s, a ‘pat tern play back’ was devised, which converted spectrograms back to an auditory form. This enabled researchers to modify the spectrogram, or even create hand-painted spectrograms, to investigate the auditory perceptual correlates of particular changes in the signal (Cooper, Liberman, & Borst, 1951).
FIGURE 1.4 A spectrogram of the words ‘heed’, ‘hid’, ‘head’, ‘had’, ‘hod’, ‘hawed’, ‘hood’, ‘who'd’ as spoken in a British accent. (Reproduced from Ladefoged, 1993.)
How do we extract the systematic information from such variable input? For many years it was assumed that children must first learn to recognise the phonemes from which all words are composed (see Phones and phonemes, below). The phonemes of English are shown on the table in the appendix. The argument for a level of representation between the acoustic signal and the word is strengthened by the evidence that people have no difficulty in operating with unfamiliar stimuli at this level. Even young children can repeat back unfamiliar strings of speech sounds, provided these are reasonably short and do not overload their memory capacity (Gathercole & Adams, 1993). If I say ‘prindle’ and you repeat it accurately, this must mean that you are able to perform some analysis that enables you to extract the articulatory correlates of the signal. Thus a level of representation between a relatively unprocessed auditory stimulus and the word, as shown in Fig. 1.2, is motivated both on the grounds of efficiency and because it would explain our ability to analyse and reproduce novel sequences of speech sounds with such facility.
PHONES AND PHONEMES
In using symbols to represent speech sounds, a distinction is ma...