Designed to present some of the current research on student motivation, cognition, and learning, this book serves as a festschrift for Wilbert J. McKeachie who has been a leading figure in college teaching and learning. The contributions to this volume were written by former students, colleagues and friends.
A common focus on a general or social cognitive view of learning is shared throughout the volume, but there are significant differences in the perspectives the researchers bring to bear on the issues. They provide an excellent cross-section of current thinking and research on general cognitive topics such as students' knowledge structures, cognitive and self-regulated learning strategies, as well as reasoning, problem solving, and critical thinking. Social cognitive and motivational topics are also well represented, including self-worth theory and expectancy-value models. More importantly, an explicit attempt is made to link cognitive and motivational constructs theoretically and empirically. This area of research is one of the most important and promising areas of future research in educational psychology. Finally, most of the chapters address instructional implications, but several explicitly discuss instructional issues related to the improvement of college students' motivation and cognition.

eBook - ePub
Student Motivation, Cognition, and Learning
Essays in Honor of Wilbert J. Mckeachie
- 420 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Student Motivation, Cognition, and Learning
Essays in Honor of Wilbert J. Mckeachie
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Topic
EducationSubtopic
Education General1
The Autotnaticity of Similarity-Based Reasoning
Kevin Biolsi
Edward E. Smith
University of Michigan
A recurring theme in Bill McKeachie’s writings about teaching and learning has been the importance of understanding students’ cognition (e.g., McKeachie, 1980a, 1980b). For example, one line of McKeachie’s work has focused on students’ cognitive structures of key classroom concepts, and how the form and evolution of such structures reflect on student performance (Lin, McKeachie, Wernander, & Hedegard, 1970; Naveh-Benjamin, McKeachie, & Lin, 1989; Naveh-Benjamin, McKeachie, Lin, & Tucker, 1986). Other work on learning strategies (McKeachie, Pintrich, & Lin, 1985a) and learning to learn (McKeachie, Pintrich, & Lin, 1985b; Pintrich, McKeachie, & Lin, 1987) has emphasized the importance of teaching students key concepts of cognitive psychology along with the learning strategies that make use of these concepts. The importance of such considerations is underscored by the recent review of teaching and learning in the college classroom by McKeachie, Pintrich, Lin, Smith, and Sharma (1990); in this document, a considerable amount of space is devoted to student cognition, including such topics as knowledge structure, cognitive and metacognitive learning strategies, and thinking and problem solving. In this chapter we hope to contribute to such work on student cognition, focusing on issues that are relevant to probabilistic reasoning and to training such reasoning.
When people are asked to judge the probabilities of various events, rather than employing principles of probability theory they might have learned in academic settings, often they rely on a number of informal heuristics (e.g., Kahneman, Slovic, & Tversky, 1982; Nisbett & Ross, 1980). One such heuristic is representativeness, whereby an event is judged likely to the extent that it is “(i) similar in essential properties to its parent population; and (ii) reflects the salient features of the process by which it is generated” (Kahneman & Tversky, 1972, p. 431). When the problem elements are instances and categories, then the degree of representativeness reduces to the typicality of an instance in a category, or the degree to which the instance is similar to the prototype of the category (Shafir, Smith, & Osherson, 1990).
To illustrate the representativeness, or similarity, heuristic, consider the following description: “Bill is 34 years old. He is intelligent, but unimaginative, compulsive, and generally lifeless. In school, he was strong in mathematics but weak in social studies and humanities” (Tversky & Kahneman, 1983, p. 297). Given this description, subjects judge Bill more likely to be an accountant who plays jazz for a hobby than just someone who plays jazz for a hobby, presumably because of Bill’s similarity to the prototypical (or stereotypical) accountant. Such a judgment violates the conjunction rule of probability, which specifies that the conjunction of any two events can be no more probable than either event by itself. In other judgment tasks, subjects have been shown to ignore or severely underweight prior probabilities or base rates of events in favor of similarity information, even though the use of such base-rate information is prescribed by normative theory (see Kahneman et al., 1982). Such reliance on similarity has been demonstrated in a number of domains with a number of different subject populations, including medical decision making (Travis, Phillippi, & Tonn, 1989), clinical judgment (Dawes, 1986), legal decisions (Saks & Kidd, 1986), and developmental studies with grade-school children (Agnoli; 1991; Jacobs & Potenza, 1991). In addition, the potential implications of the representativeness heuristic for school psychologists have been described by Burns (1990) and Fagley (1988).
In this chapter we build on the idea that the similarity heuristic is widely used because it is a type of “natural assessment” (Tversky & Kahneman, 1983). In what follows, we first interpret natural assessment as an “automatic” computation,1 where the notion of automaticity is drawn from studies of attention and memory. We then describe two experiments that demonstrate that similarity assessments exhibit at least one important property of automatic processes, namely that their execution is obligatory, given that the appropriate inputs occur. Finally we tie these results to work in education.
As alluded to previously, automatic processes have been intensively studied in the domains of attention and memory (e.g., Schneider & Shiffrin, 1977; Shiffrin & Schneider, 1977). In these studies, automatic processes are generally characterized by some combination of the following properties: They are unavoidable or obligatory once the appropriate inputs occur, they are effortless or require relatively little of one’s attentional capacities, they occur in parallel, and they are relatively fast. In the experiments described here, we focus on the first of these properties, namely the obligatory nature of similarity computations. This property of automatic processes is often studied within the paradigm pioneered by Stroop (1935; see MacLeod, 1991, for a comprehensive review of Stroop experiments).
In a variant of Stroop’s original experiments, subjects are presented with lists of words printed in colored ink. The subjects’ task is to name the color of the ink for all words in the list as quickly as possible. In one condition the words are neutral with respect to color (e.g., “take,” “friend”), while in a second condition the words are color terms (e.g., “blue,” “red”) printed in ink colors different from the colors they named. For example, the word “blue” might be printed in red ink, whereas the word “brown” might be printed in green ink. In these experiments, color-naming times are found to be significantly longer and error rates higher in the second than in the first condition. Furthermore, when color words and ink colors are congruent (e.g., “blue” is printed in blue ink), facilitation occurs in the form of faster reading times and fewer errors as compared to control items. These results indicate that subjects are unable to suppress reading of the word, and that the encoding and interpretation of the color word can then interfere with or facilitate naming its print color. Thus, the encoding and interpretation of a word is obligatory and, hence, an automatic process.
Like the encoding of a word, the assessment of similarity might be obligatory in the sense that it is manditorily performed whenever input information of the proper kind is presented. To test this hypothesis, we should be able to employ a variation of the Stroop paradigm in which information that automatically activates similarity computations is presented in a task that also requires computations of a second type, for example, computations of relative base rates or frequencies. By varying the degree to which the two processes lead to the same answer, we should observe both interference effects, in the form of increased response times and error rates, and facilitation effects, in the form of decreased response times and error rates, of similarity on frequency-based responses.
To illustrate, consider the description of Linda as “bright, outspoken and concerned with social issues” and the two categories bankteller and prominent feminist writer. If the task is to choose the category with the higher frequency, then bankteller should be chosen. However, Linda as described seems to be more similar to the typical prominent feminist writer than to the typical bankteller, so similarity leads to a different answer than does frequency. Thus, to the extent that the computation of similarity occurs more rapidly than that of frequency, and that the results of the similarity computation cannot be ignored, we should expect the response to such an item to be slower or less accurate when compared to an appropriate control. Similarly, if the two choices used with the Linda description are social worker and president of a cosmetics company, then both frequency and similarity lead to the same response, namely social worker, and we should expect facilitation in the form of faster and/or more accurate responses.
In our experiments, subjects were trained to make choices as just described using two different criteria: (a) base rates of the categories and (b) similarity of the descriptions to category prototypes. The predictions are displayed schematically in Fig. 1.1. Consider first those trials for which base rates are used as the criterion (the dashed line in Fig. 1.1). When the similarity and base-rate information agree (e.g., “Linda is a social worker” vs. “Linda is president of a cosmetics company”), we expect facilitation in the form of shorter response times and/or lower error rates than for suitable control items. When the two types of information conflict with each other (e.g., “Linda is a bankteller” vs. “Linda is a prominent feminist writer”), we expect interference in the form of longer response times and/or higher error rates relative to the control items.
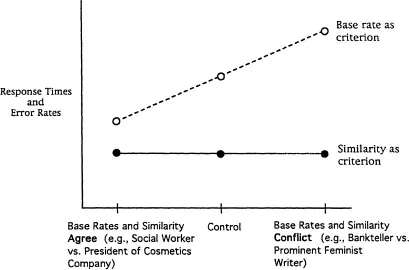
FIG. 1.1. Predicted patterns of error rates and response times for experimental conditions.
Now consider those trials for which similarity to category prototype is used as the decision criterion. Because we do not predict automatic activation of base-rate computations, we do not expect such computations to intrude on similarity-based choices. Therefore, the response times and error rates should be relatively constant across the three conditions for the similarity-based trials, as indicated by the solid line in Fig. 1.1.
EXPERIMENT 1
Method
Procedure
Subjects were first given training materials that instructed them in judging relative likelihood using two different criteria: similarity to category prototype and frequency of category. The training materials briefly described the principles behind the two criteria and provided several examples with personality descriptions of the “Linda” type. Decisions based on similarities and frequencies are referred to as similarity decisions and probability decisions, respectively.
Following training, each subject performed the experiment seated at a computer terminal with a response panel. On each trial, a personality description was presented and remained on the screen until the subjects had read and understood it, and then pressed the appropriate response key. Following the description, either the word “Probability” or the word “Similarity” appeared on the screen for one second, instructing the subjects as to which criterion to use for their subsequent decision. Next, two category statements appe...
Table of contents
- Front Cover
- Half Title
- Title Page
- Copyright
- Contents
- Preface
- 1 The Automaticity of Similarity-Based Reasoning
- 2 Problem Solving, Transfer, and Thinking
- 3 Measuring and Improving Students’ Disciplinary Knowledge Structures
- 4 Science Students’ Learning: Ethnographic Studies in Three Disciplines
- 5 Self-Regulated Learning in College Students: Knowledge, Strategies, and Motivation
- 6 Goals as the Transactive Point Between Motivation and Cognition
- 7 Self-Worth and College Achievement: Motivational and Personality Correlates
- 8 Seeking Academic Assistance as a Strategic Learning Resource
- 9 Situated Motivation
- 10 Investigating Self-Regulatory Processes and Perceptions of Self-Efficacy in Writing by College Students
- 11 Strategic Learning/Strategic Teaching: Flip Sides of a Coin
- 12 Teaching Dialogically: Its Relationship to Critical Thinking in College Students
- 13 Competition, Achievement, and Gender: A Stress Theoretical Analysis
- 14 Research on College Student Learning and Motivation: Will It Affect College Instruction?
- 15 Concluding Remarks
- Wilbert J. McKeachie’s Vita
- Author Index
- Subject Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Student Motivation, Cognition, and Learning by Paul R. Pintrich,Donald R. Brown,Claire Ellen Weinstein in PDF and/or ePUB format, as well as other popular books in Education & Education General. We have over 1.5 million books available in our catalogue for you to explore.