This classic volume outlines, for both students and professionals, the mathematical theories and equations that are necessary for evaluating a test and for quantifying its characteristics. The author utilizes formulas that evaluate both the reliability and the validity of tests. He also provides the means for evaluating the reliability and validity of total test scores and individual item analysis. The work remains one of the only books on classical test theory to discuss applications, "true score" theory, the effect of test length on reliability and validity, and the effects of univariate and multivariate selection on validity.

- 508 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Theory of Mental Tests
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Topic
EducationSubtopic
Education General1
Introduction
It is interesting to note that during the 1890’s several attempts were made in this country to utilize the new methods of measurement of individual differences in order to predict College grades. J. McKeen Cattell and his student Clark Wissler tried a large number of psychological tests and correlated them with grades in various subjects at Columbia University; see Cattell (1890), Cattell and Farrand (1896), and Wissler (1901). The correlations between the psychological tests and the grades were around zero, the highest correlation being .19. A similar attempt by Gilbert (1894), at Yale, produced similarly disappointing results.
Scientific confidence in the possibilities of measuring individual differences revived in this country with the introduction of the Binet scale and the quantitative techniques developed by Karl Pearson and Charles Spearman at the beginning of the twentieth Century. Nearly all the basic formulas that are particularly useful in test theory are found in Spearman’s early papers; see Spearman (1904a), (1904b), (1907), (1910), and (1913). Since then development of both the theory and the practical aspects of aptitude and achievement testing has progressed rapidly. Aptitude and achievement tests are widely used in education and in industry.
Since 1900 great progress has been made toward a unified quantitative theory that describes the behavior of test items and test scores under various conditions. This mathematical rationale applicable to mental tests should not be confused with statistics. A good foundation in elementary statistics and elementary mathematics is a prerequisite for work in the theory of mental tests. In addition, as the theory of mental tests is developed, the necessity arises for various statistical criteria to determine whether or not a given set of test data agrees with the theory, within reasonable sampling limits. The theory, however, must first be developed without consideration of sampling errors, and then the statistical problems in conjunction with sampling can be considered.
This book deals with the mathematical theory and statistical methods used in interpreting test results. There are numerous non-quantitative Problems involved in constructing aptitude or achievement tests that are not considered here. Non-quantitative problems such as choice of item types or matching the examination to the objectives of a curriculum are discussed in the University of Chicago Manual of Examination Methods (1937); Englehart (1942); Hawkes, Lindquist, and Mann (1936); Hull (1928); Orleans (1937); Ruch (1929); and others. Therefore, no attempt is made here to familiarize the student with the various psychological and educational tests now available or with the scope of the many testing programs. Such material is surveyed in yearbooks by Buros (1936), (1937), (1938), (1941), and (1949); Hildreth (1939); Lee and Symonds (1934); the National Society for the Study of Education, the 17th Yearbook (1918); Ruger (1918); Whipple (1914), (1915); Freeman (1939); Mursell (1947); Ross (1947); Goodenough (1949); Cronbach (1949); and other general textbooks listed in the bibliography.
In constructing tests, analyzing and interpreting the results, there are five major types of problems:
- Writing and selecting the test items.
- Assigning a score to each person.
- Determining the accuracy (reliability or error of measurement) of the test scores.
- Determining the predictive value of the test scores (validity or error of estimate).
- Comparing the results with those obtained using other tests or other groups of subjects. In making these comparisons, it is necessary to consider the effect of test length and group heterogeneity on the various measures of the accuracy and the predictive value of the test scores.
In dealing with any given test these problems would arise chronologically in the order in which they are given above. However, the theory of the selection of test items depends upon comparing them with some test score or scores; therefore it is convenient to consider first the theory dealing with the accuracy of these test scores. Similarly the evaluation of experimental methods of determining reliability and the discussion of practical methods of setting up parallel tests depend upon a theoretical concept of reliability and of parallel tests. Therefore, instead of beginning with practical problems of item selection, experimental methods of determining reliability, or of setting up parallel tests, we shall begin with the theoretical constructs.
An ideal model will be set up giving the measures of accuracy of test scores and the theoretical effects of changes in test length and in group heterogeneity. The theory of these changes will be derived from assumptions regarding parallel tests and selection procedures, without inquiring very closely into the experimental methods that are appropriate for realizing these assumptions. Beginning with Chapter 14, various practical problems relating to the construction of parallel tests, criteria for parallel tests, experimental methods of determining reliability, etc., will be considered. It is felt that postponing such practical considerations until the latter part of the book has the advantage of giving the student a firm foundation in theory first. Then on the basis of this familiarity with the ideal Situation, various practical procedures can be evaluated in terms of the closeness with which they approximate the theoretically perfect method. To consider practical experimental procedures without such a grounding in the theoretical foundation leaves these procedures as approximations to something that is not yet clearly stated or understood.
The basic theoretical material on accuracy of test scores is presented in Chapters 2 through 5, which deal with the topics of test reliability and the error of measurement. The effect of test length upon reliability and validity is considered in Chapters 6 through 9, and the effect of group heterogeneity on measures of accuracy in Chapters 10 through 13. In these chapters we give only a theoretical definition of parallel tests, and we define reliability as the correlation between two parallel forms. This simplified presentation of the concept of parallel tests and of reliability makes it possible to concentrate on the theory of test reliability and test validity before taking up the short-cuts and approximations that are frequently used in actual practice. Practical problems of criteria for parallel tests are given in Chapter 14, and experimental methods of determining reliability when a parallel form is not used are considered in Chapters 15 and 16. Methods of scoring, scaling, and equating tests are considered in Chapters 18 and 19. Problems dealing with batteries of tests are considered in Chapter 20, and problems of item selection in Chapter 21.
2
Basic Equations Derived from a Definition of Random Error
1. Introduction
We shall begin by assuming the conventional objective testing procedure in which the person is presented with a number of items to be answered. Each answer is scored as correct or incorrect, and a simple or a weighted sum of the correct answers is taken as the test score. The various procedures for determining which items to use and the best weighting methods will be considered later. For the present we assume that the numerical score is based on a count, one or more points for each correct answer and zero for each incorrect answer, and we turn our attention to the determination of the accuracy of this score.
When psychological measurement is compared with the type of measurement found in physics, many points of similarity and difference are found. One of the very important differences is that the error of measurement in most psychological work is very much greater than it is in physics. For example, Jackson and Ferguson (1941) resorted to specially constructed “rubber rulers” in order to reduce the reliability of length measurements to values appreciably below .99. The estimation of the error in a set of test scores and the differentiation between “error” and “true” score on a test are central problems in mental measurement.
2. The basic assumption of test theory
It is necessary to make some assumption regarding the relationship between true scores and error scores. Let us define three basic symbols.
- Xi = the score of the ith person on the test under consideration.
- Ti = the true score of the ith person on this test.
- Ei = the error component for the same person.
In defining these symbols it is assumed that the gross score has two components. One of these components (T) represents the actual ability of the person, a quantity that will be relatively stable from test to test as long as the tests are measuring the same thing. The other component (E) is an error. It is due to the various factors that may cause a person sometimes to answer correctly an item that he does not know, and sometimes to answer incorrectly an item that he does know. So far, it will be observed, there is no proposition subject to any experimental check. We have simply said that there is some number T that would be the person’s correct score, and that the obtained score (X) does not necessarily equal T.
It is possible to make many different assumptions regarding the relationship between the three terms X, T, and E. The one made in test theory is the simplest possible assumption, namely, that
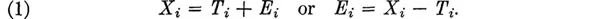
This equation may be regarded as an assumption that states the relationship between true and error score; or it may be regarded as an equation defining what we are going to mean by error. In other words, once we accept the concept of a tr...
Table of contents
- Cover
- Title
- Copyright
- Contents
- 1. INTRODUCTION
- 2. BASIC EQUATIONS DERIVED FROM A DEFINITION OF RANDOM ERROR
- 3. FUNDAMENTAL EQUATIONS DERIVED FROM A DEFINITION OF TRUE SCORE
- 4. ERRORS OF MEASUREMENT, SUBSTITUTION, AND PREDICTION
- 5. VARIOUS INTERPRETATIONS OF THE ERROR OF MEASUREMENT
- 6. EFFECT OF DOUBLING TEST LENGTH ON OTHER TEST PARAMETERS
- 7. EFFECT OF TEST LENGTH ON MEAN AND VARIANCE (GENERAL CASE)
- 8. EFFECT OF TEST LENGTH ON RELIABILITY (GENERAL CASE)
- 9. EFFECT OF TEST LENGTH ON VALIDITY (GENERAL CASE)
- 10. EFFECT OF GROUP HETEROGENEITY ON TEST RELIABILITY
- 11. EFFECT OF GROUP HETEROGENEITY ON VALIDITY (BIVARIATE CASE)
- 12. CORRECTION FOR UNIVARIATE SELECTION IN THE THREE-VARIABLE CASE
- 13. CORRECTION FOR MULTIVARIATE SELECTION IN THE GENERAL CASE
- 14. A STATISTICAL CRITERION FOR PARALLEL TESTS
- 15. EXPERIMENTAL METHODS OF OBTAINING TEST RELIABILITY
- 16. RELIABILITY ESTIMATED FROM ITEM HOMOGENEITY
- 17. SPEED VERSUS POWER TESTS
- 18. METHODS OF SCORING TESTS
- 19. METHODS OF STANDARDIZING AND EQUATING TEST SCORES
- 20. PROBLEMS OF WEIGHTING AND DIFFERENTIAL PREDICTION
- 21. ITEM ANALYSIS
- BIBLIOGRAPHY
- APPENDIX A. EQUATIONS FROM ALGEBRA, ANALYTICAL GEOMETRY, AND STATISTICS, USED IN TEST THEORY
- APPENDIX B. TABLE OF ORDINATES AND AREAS OF THE NORMAL CURVE
- APPENDIX C. SAMPLE EXAMINATION QUESTIONS IN STATISTICS FOR USE AS A REVIEW EXAMINATION AT THE BEGINNING OF THE COURSE IN TEST THEORY
- APPENDIX D. SAMPLE EXAMINATION ITEMS IN TEST THEORY
- ANSWERS TO PROBLEMS
- AUTHOR INDEX
- TOPIC INDEX
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Theory of Mental Tests by Harold Gulliksen in PDF and/or ePUB format, as well as other popular books in Education & Education General. We have over 1.5 million books available in our catalogue for you to explore.