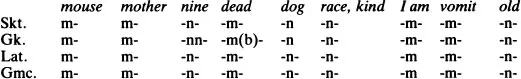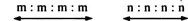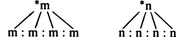Based on Comrie's much-praised The World's Major Languages , this is the first comprehensive guide in paperback to descibe in detail the language families of Eastern Europe, and includes an introduction which surveys the field.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
By the term Indo-European we are referring to a family of languages which by about 1000 BC were spoken over a large part of Europe and parts of southwestern and southern Asia. Indo-European is essentially a geographical term: it refers to the easternmost (India) and westernmost (Europe) expansion of the family at the time it was proven to be a linguistic group by scholars of the eighteenth and nineteenth centuries (the term was first used in 1813). Of course modern expansion and migrations which have taken Indo-European languages to Africa, Hawaii, Australia and elsewhere around the world now suggest another name for the family, but the term Indo-European (German Indogermanisch) is now well rooted in the scholarly tradition.
Claiming that a language is a member of a linguistic family is quite different from establishing such an assertion using proven methods and principles of scientific analysis. During the approximately two centuries in which the interrelationships among the Indo-European languages have been systematically studied, techniques to confirm or deny genetic affiliations between languages have been developed with great success. Chief among these methods is the comparative method, which takes shared features among languages as its data and provides procedures for establishing proto-forms. The comparative method is surely not the only available approach, nor is it by any means foolproof. Indeed, other methods of reconstruction, especially the method of internal reconstruction and the method of typological inference, work together with the comparative method to achieve reliable results. But since space is limited and the focus of this chapter is Indo-European and not methods of reconstruction, we will restrict ourselves here to a brief review of the comparative method using only data from Indo-European languages.
When we claim that two or more languages are genetically related, we are at the same time claiming that they share common ancestry. And if we make such a claim about common ancestry, then our methods should provide us with a means of recovering the ancestral system, attested or not. The initial demonstration of relatedness is the easy part; establishing well-motivated intermediate and ancestral forms is quite another matter. Among the difficulties are: which features in which of the languages being compared are older? which are innovations? which are borrowed? how many shared similarities are enough to prove relatedness conclusively, and how are they weighted for significance? what assumptions do we make about the relative importance of lexical, morphological, syntactic and phonological characteristics, and about directions of language change?
All of these questions come into play in any reconstruction effort, leaving us with the following assumption: if two or more languages share a feature which is unlikely to have arisen by accident, borrowing or as the result of some typological tendency or language universal, then it is assumed to have arisen only once and to have been transmitted to the two or more languages from a common source. The more such features are discovered and securely identified, the closer the relationship.
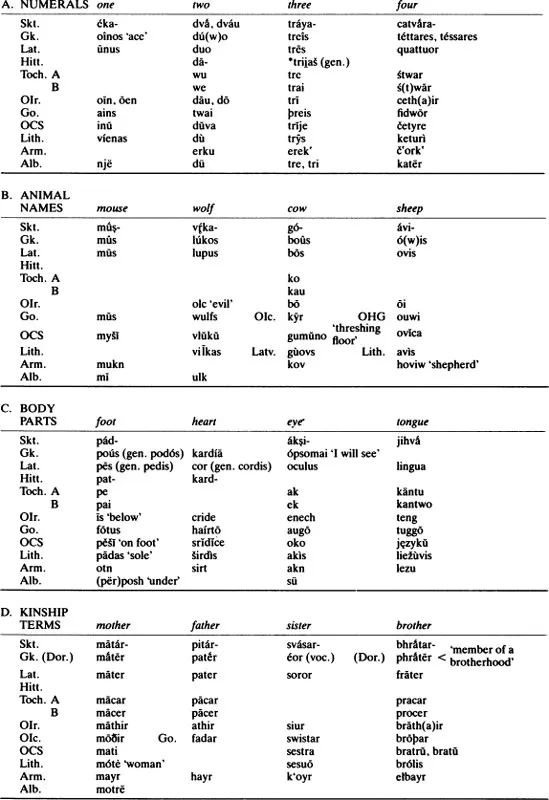
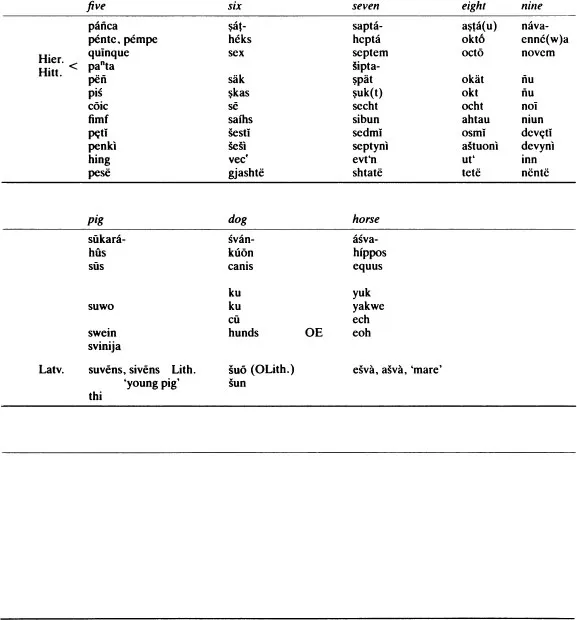
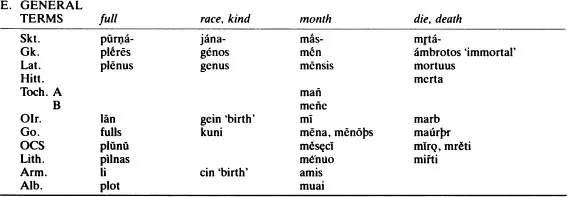
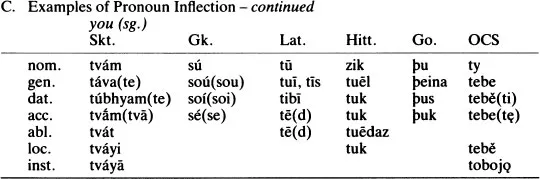
In determining genetic relationship and reconstructing proto-forms using the comparative method, we usually start with vocabulary. Table 1.1 contains a number of words from various Indo-European languages which will demonstrate a common core of lexical items too large and too basic to be explained either by accident or borrowing. A list of possible cognates which is likely to produce a maximum number of common inheritance items, known as the basic vocabulary list, provides many of the words we might investigate, such as basic kinship terms, pronouns, basic body parts, lower numerals and others. From these and other data we seek to establish sets of equations known as correspondences, which are statements that in a given environment X phoneme of one language will correspond to Y phoneme of another language consistently and systematically if the two languages are descended from a common ancestor.
Table 1.1 Some Basic Indo-European Terms
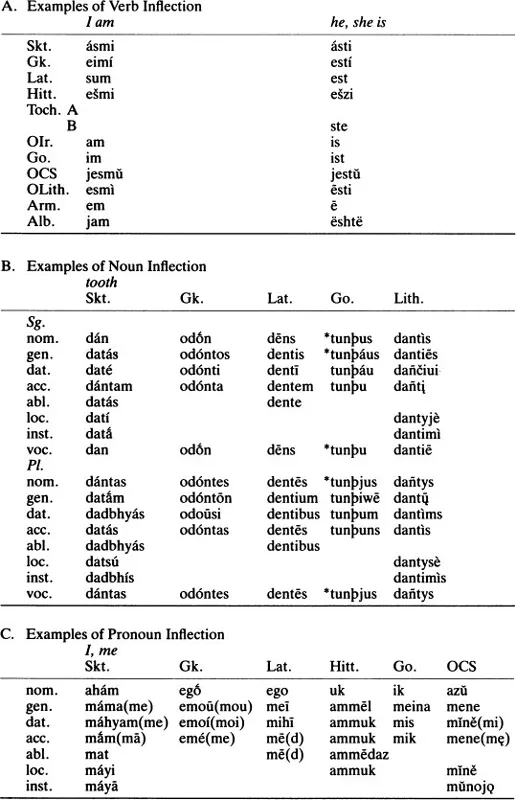
In order to illustrate the comparative method we will briefly and selectively choose a few items from tables 1.1 and 1.2, restricting our data to fairly clear cases.
Table 1.2 Inflectional Regularities in Indo-European Languages
Note: Forms in parentheses are enclitic variants.
old
vomit
sána-hénos
‘last year’s’
vámiti eméō
senex
vomō
sen sineigs
OIc.
vāma ‘sickness’
sēnas hin
vémti
We will first look only at the nasals m and n. Lined up for the comparative method they look like this:
Before we begin reconstructing we must be sure that we are comparing the appropriate segments. It is clear that this is the case in ‘mouse’, ‘mother’, ‘dog’, ‘race, kind’, ‘I am’, ‘vomit’ and ‘old’, but less clear in ‘nine’ and ‘dead’. What of the double n in Gk. enné(w)a? A closer look reveals that en- is a prefix; thus, the first n is outside the equation. Similarly with ámbrotos ‘immortal’: the á- is a prefix meaning ‘not’ (=Lat. in -, Go. un-, etc.), and the b results from a rule of Greek in which the sequence -mr- results in -mbr-, with epenthetic b (cf. Lat. camera > Fr. chambre). So the m’s do indeed align, leaving us with a consistent set of m and n correspondences:
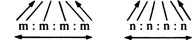
These alignments represent the horizontal or comparative dimension. Next we ‘triangulate’ the segments, adding the vertical, or historical dimension:
Finally, after checking all the relevant data and investigating their distributional patterns, we make a hypothesis concerning the proto-sound. In these two cases there is only one reasonable solution, namely *m and *n:
At this stage of the analysis we are claiming that *m > (develops into) m and *n > n in the various daughter languages.
Neat correspondences such as these are more the exception than the rule in historical-comparative linguistics. It is far more common to find sets in which only a few of the members have identical segments. But the method of comparative reconstruction, when supplemented with sufficient information about the internal structure of the languages in question, can still yield replicable results. Consider the following data from table 1.1, supplemented by some additional material:
We are concentrating here on the correspondences which include s, h, and r. In ‘six’ and ‘old’ we have the set s : h : s : s initially (cf. also ‘seven’ and ‘pig’). In final position we find
: s : s : s in ‘six’ and ‘old’ (cf. also ‘one’, ‘three’, ‘mouse’ and ‘wolf, among others). And in medial position we have s :
: r : s in ‘race, kind’ (gen.) and ‘be’. What is or are the proto-sound(s)?
A brief look at the languages in question takes us straight to *s for all three correspondences. *s > h in Greek initially (weakens), and disappears completely medially, yielding a phonetically common pattern of s > h >
(cf. Avestan, Spanish). Final
in the Sanskrit examples is only the result of citing the Sanskrit words in their root forms; the full nominative forms (as in the other languages) would contain s as well (e.g. jánas, sánas, etc.). And the medial Latin r is the result of rhotacism, whereby Latin consistently converts intervocalic s to r (cf. es- ‘be’, erō ‘I will be’; (nom.) flōs ‘flower’ (gen.) flōris).
From these few, admittedly simplified examples we see that the comparative method, when supplemented by adequate information about the internal structure of the languages in question and by a consideration of all the relevant data, can produce consist...
Table of contents
Cover
Half Title
Title Page
Copyright
Contents
Preface
List of Abbreviations
Introduction
1. Indo-European Languages
2. Slavonic Languages
3. Russian
4. Polish
5. Czech and Slovak
6. Serbo-Croat
7. Greek
8. Uralic Languages
9. Hungarian
10. Finnish
11. Turkish and the Turkic Languages
Language Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access The Major Languages of Eastern Europe by Bernard Comrie in PDF and/or ePUB format, as well as other popular books in Languages & Linguistics & Languages. We have over 1.5 million books available in our catalogue for you to explore.