
eBook - ePub
Modern Enterprise Business Intelligence and Data Management
A Roadmap for IT Directors, Managers, and Architects
- 96 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Modern Enterprise Business Intelligence and Data Management
A Roadmap for IT Directors, Managers, and Architects
About this book
Nearly every large corporation and governmental agency is taking a fresh look at their current enterprise-scale business intelligence (BI) and data warehousing implementations at the dawn of the "Big Data Era"…and most see a critical need to revitalize their current capabilities. Whether they find the frustrating and business-impeding continuation of a long-standing "silos of data" problem, or an over-reliance on static production reports at the expense of predictive analytics and other true business intelligence capabilities, or a lack of progress in achieving the long-sought-after enterprise-wide "single version of the truth" – or all of the above – IT Directors, strategists, and architects find that they need to go back to the drawing board and produce a brand new BI/data warehousing roadmap to help move their enterprises from their current state to one where the promises of emerging technologies and a generation's worth of best practices can finally deliver high-impact, architecturally evolvable enterprise-scale business intelligence and data warehousing.
Author Alan Simon, whose BI and data warehousing experience dates back to the late 1970s and who has personally delivered or led more than thirty enterprise-wide BI/data warehousing roadmap engagements since the mid-1990s, details a comprehensive step-by-step approach to building a best practices-driven, multi-year roadmap in the quest for architecturally evolvable BI and data warehousing at the enterprise scale. Simon addresses the triad of technology, work processes, and organizational/human factors considerations in a manner that blends the visionary and the pragmatic.
- Takes a fresh look at true enterprise-scale BI/DW in the "Dawn of the Big Data Era"
- Details a checklist-based approach to surveying one's current state and identifying which components are enterprise-ready and which ones are impeding the key objectives of enterprise-scale BI/DW
- Provides an approach for how to analyze and test-bed emerging technologies and architectures and then figure out how to include the relevant ones in the roadmaps that will be developed
- Presents a tried-and-true methodology for building a phased, incremental, and iterative enterprise BI/DW roadmap that is closely aligned with an organization's business imperatives, organizational culture, and other considerations
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Chapter 1
The Rebirth of Enterprise Data Management
Abstract
Tremendous interest exists today in enterprise data management, largely because of the “dawn of the Big Data era.” Yet organizations have been pursuing the idea of well-architected data management at the enterprise level since the 1960s and 1970s, largely with very little lasting success. Understanding the timeline and history of enterprise data management is essential to making intelligent architecture decisions with today’s and tomorrow’s new technologies and to avoid repeating mistakes of the past. From early visions of a single common, mainframe-hosted “data base” to the consequences of Y2K efforts, a comprehensive yet concise history of enterprise data management is presented.
Keywords
Data
Enterprise Data
Enterprise Data History
Enterprise Data Trends
Big Data
Data Warehousing
Business Intelligence
Predictive Analytics
1.1. In the beginning: how we got to where we are today
Those who cannot remember the past, are condemned to repeat it.
- George Santayana (1863–1952)
To best understand the state of enterprise data management (EDM) today, it’s important to understand how we arrived at this point during a journey that dates back nearly 50 years to the days when enormous, expensive mainframe computers were the backbone of “data processing” (as Information Technology was commonly referred to long ago) and computing technology was still in its adolescence.
1.1.1. 1960s and 1970s
Many data processing textbooks of the 1960s and 1970s proposed a vision much like that depicted in Figure 1.1.

Fig. 1.1 1960s/1970s vision of a common “data base.”
The simplified architecture envisioned by many prognosticators called for a single common “data base”1 that would provide a single primary store of data for core business applications such as accounting (general ledger, accounts payable, accounts receivable, payroll, etc.), finance, personnel, procurement, and others. One application might write a new record into the data base that would then be used by another application.
In many ways, this “single data base” vision is similar to the capabilities offered today by many enterprise systems vendors in which a consolidated store of data underlies enterprise resource planning (ERP), customer relationship management (CRM), supply chain management (SCM), human capital management (HCM), and other applications that have touch-points with one another. Under this architecture the typical company or governmental agency would face far fewer conflicting data definitions and semantics; conflicting business rules; unnecessary data duplication; and other hindrances than what is found in today’s organizational data landscape.
Despite this vision of a highly ordered, quasi-utopian data management architecture, the result for most companies and governmental agencies looked far more like the diagram in Figure 1.2, with each application “owning” its own file systems, tapes, and first-generation database management systems (DBMSs).
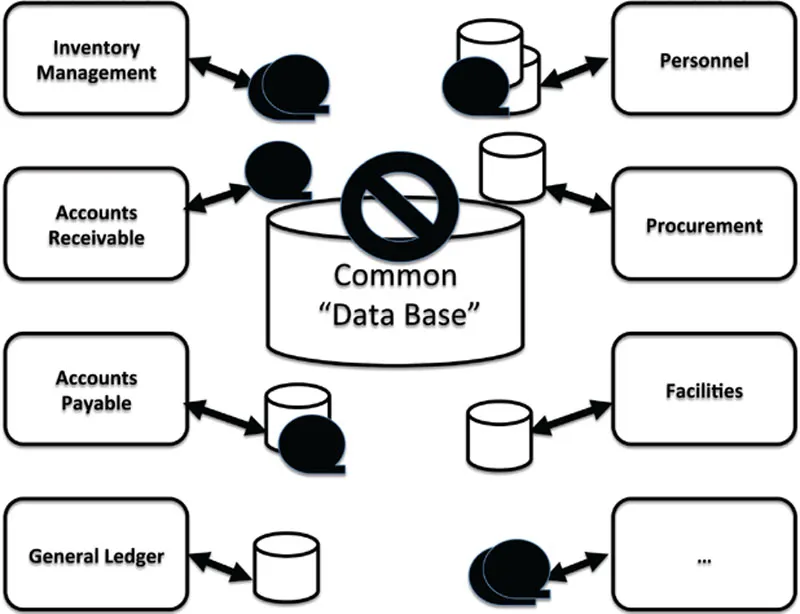
Fig. 1.2 The reality of most 1960s/1970s data environments.
Even when an organization’s portfolio of applications was housed on a single mainframe, the vision of a shared pool of data among those applications was typically nowhere in the picture. However, the various applications – many of which were custom-written in those days – still needed to share data among themselves. For example, Accounts Receivable and Accounts Payable applications needed to feed data into the General Ledger application. Most organizations found themselves rapidly slipping into the “spider’s web quagmire” of numerous one-by-one data exchange interfaces as depicted in Figure 1.3.
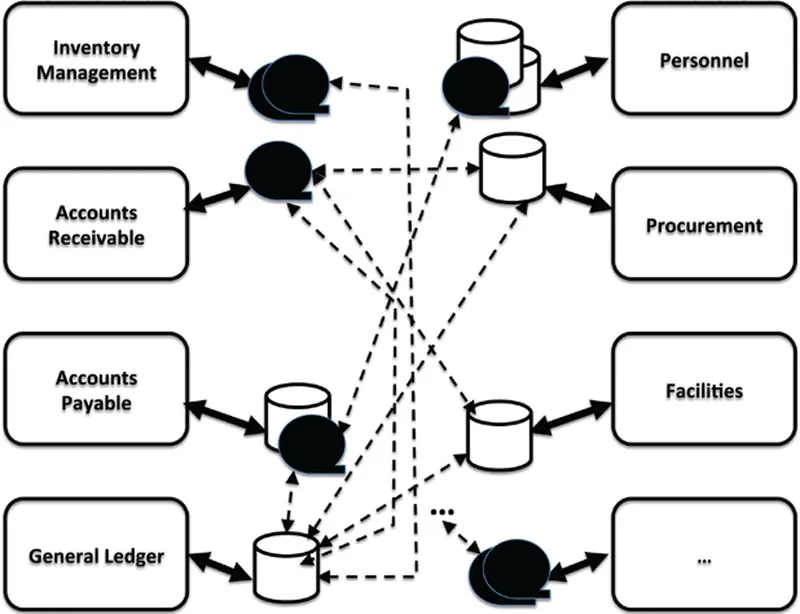
Fig. 1.3 Ungoverned data integration via proliferating one-by-one interfaces.
By the time the 1970s drew to a close and computing was becoming more and more prevalent within business and government, any vision of managing one’s data assets at an enterprise level was far from a reality for most organizations. Instead, a world of uncoordinated, often conflicting data silos was what we were left with.
1.1.2. 1980s
As the 1980s progressed, the data silo problem actually began to worsen. Minicomputers had been introduced in the 1960s and had grown in popularity during the 1970s, led by vendors such as Digital Equipment Corporation (DEC) and Data General. Increasingly, the fragmentation of both applications and data moved from the realm of the mainframe into minicomputers as organizations began deploying core applications on these newer, smaller-scale platforms. Consequently, the one-by-one file transfers and other types of data exchange depicted in Figure 1.3 were now increasingly occurring across hardware, operating system platforms, and networks, many of which were only beginning to “talk” to one another. As the 1980s proceeded and personal computers (often called “microcomputers” at the time) grew wildly in popularity, the typical enterprise’s data architecture grew even more fragmented and chaotic.
Many organizations realized that they now were facing a serious problem with their fragmented data silos, as did many of the leading technology vendors. Throughout the 1980s, two major approaches took shape in an attempt to overcome the fragmentation problem:
• Enterprise data models
• Distributed database management systems (DDBMSs)
1.1.2.1. Enterprise Data Models
Companies and governmental agencies attempted to get their arms around their own data fragmentation problems by embarking on enterprise data model initiatives. Using conceptual and logical data modeling techniques that began in the 1970s such as entity-relationship modeling, teams of data modelers would attempt to understand and document the enterprise’s existing data elements and attributes as well as the details of relationships among those elements. The operating premise governing these efforts was that by investing the time and resources to analyze, understand, and document all of the enterprise’s data across any number of barriers – application, platform, and organizational, in particular – the “data chaos” would begin to dissipate and new systems could be built leveraging the data structures, relationships, and data-oriented business rules that already existed.
While many enterprise data modeling initiatives did produce a better understanding of an organization’s data assets than before a given initiative had begun, these efforts largely withered over time and tended not to yield anywhere near the economies of scale originally envisioned at project inception. The application portfolio of the typical organization in the 1980s was both fast-growing and very volatile, and an enterprise data modeling initiative almost certainly fell behind new and rapidly changing data under the control of any given application or system. The result even before completion, most enterprise data models became “stale” and outdated, and were quietly mothballed.
(As most readers know, data modeling techniques are still widely used today, although primarily as part of the up-front analysis and design phase for a specific software development or package implementation project rather than attempting to document the entire breadth of an enterprise’s data assets.)
1.1.2.2. Distributed Database Management Systems (DDBMSs)
Enterprise data modeling efforts on the parts of companies and governmental agencies were primarily an attempt to understand an organization’s highly fragmented data. The data models themselves did nothing to help facilitate the integration of data across platforms, databases, organizational boundaries, etc.
To address the data fragmentation problem from an integration perspective, most of the leading computer companies and database vendors of the 1980s began work on DDBMSs. The specific technical approaches from companies such as IBM (Information Warehouse), Digital Equipment Corporation (RdbStar), Ingres (Ingres Star), and others varied from one to another, but the fundamental premise of most DDBMS efforts was as depicted in Figure 1.4.
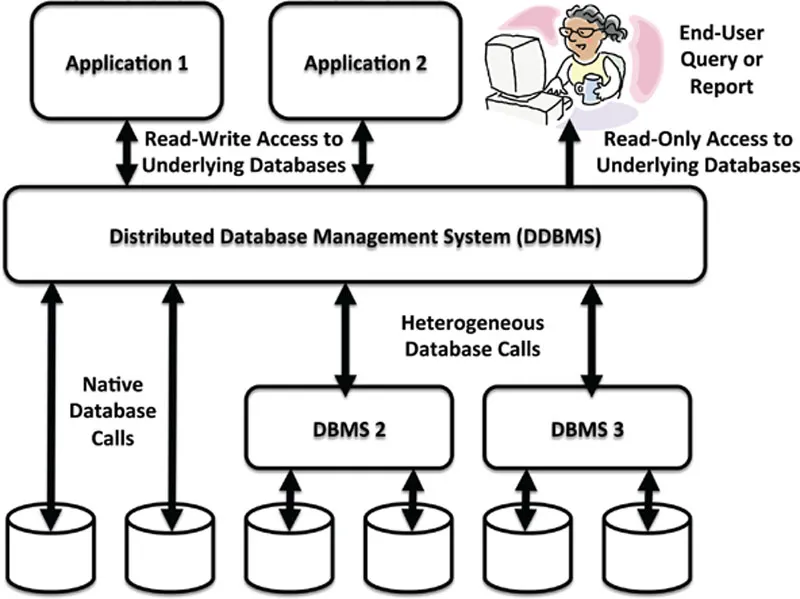
Fig. 1.4 The DDBMS concept.
The DDBMS story went like this: regardless of how scattered an organization’s data might be, a single data model-driven interface could sit between applications and end-users and the underlying databases, including those from other vendors operating under different DBMSs (#2 and #3 in Figure 1.4). The DDBMS engine would provide location and platform transparency to abstract applications and users from the underlying data distribution and heterogeneity, and both read-write access as well as read-only access to the enterprise’s data through the DDBMS would be possible.
For a number of reasons the DDBMS approach of the late 1980s faltered. Computing technology of the day wasn’t robust or powerful enough to handle the required levels of cross-referencing, filtering, and other data management operations across vast networks. Consequently, the state of the art in distributed transaction management to allow relational database COMMIT and ROLLBACK operations across multiple physical databases – and in particular, multiple databases under the control of heterogeneous DBMSs – became the undoing of the DDBMS movement. Other reasons also came into play that are beyond the scope of our discussion here; but the key takeaway is that as the 1980s gave way to the 1990s, organizations were still left with an enterprise data fragmentation problem that was becoming worse by the year.
1.1.3. 1990s
Throughout the 1980s and even back into the 1970s, many organizations built extract files that pulled select data from an operational system and loaded the data into a separate file system or database to produce reports. The primary reason for creating duplicate data was to avoid adversely impacting the op...
Table of contents
- Cover
- Title page
- Table of Contents
- Copyright Page
- Preface
- About the Author
- Chapter 1: The Rebirth of Enterprise Data Management
- Chapter 2: Assessing Your Organization’s Current State of Enterprise Data Management
- Chapter 3: Identifying and Cataloguing Key Business Imperatives
- Chapter 4: Surveying Relevant Enterprise Data Management Technologies
- Chapter 5: Building an Enterprise Data Management and Business Intelligence Roadmap
- Chapter 6: The End Game
- Appendix: Further Resources and References
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Modern Enterprise Business Intelligence and Data Management by Alan Simon in PDF and/or ePUB format, as well as other popular books in Business & Business Intelligence. We have over 1.5 million books available in our catalogue for you to explore.