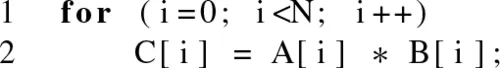Heterogeneous Computing with OpenCL 2.0 teaches OpenCL and parallel programming for complex systems that may include a variety of device architectures: multi-core CPUs, GPUs, and fully-integrated Accelerated Processing Units (APUs). This fully-revised edition includes the latest enhancements in OpenCL 2.0 including: • Shared virtual memory to increase programming flexibility and reduce data transfers that consume resources • Dynamic parallelism which reduces processor load and avoids bottlenecks • Improved imaging support and integration with OpenGLDesigned to work on multiple platforms, OpenCL will help you more effectively program for a heterogeneous future. Written by leaders in the parallel computing and OpenCL communities, this book explores memory spaces, optimization techniques, extensions, debugging and profiling. Multiple case studies and examples illustrate high-performance algorithms, distributing work across heterogeneous systems, embedded domain-specific languages, and will give you hands-on OpenCL experience to address a range of fundamental parallel algorithms.- Updated content to cover the latest developments in OpenCL 2.0, including improvements in memory handling, parallelism, and imaging support- Explanations of principles and strategies to learn parallel programming with OpenCL, from understanding the abstraction models to thoroughly testing and debugging complete applications- Example code covering image analytics, web plugins, particle simulations, video editing, performance optimization, and more
This chapter introduces the book. The key elements are the concepts of parallelism, the general model of OpenCL (versus CUDA or other parallel languages).
Keywords
Introduction
Heterogeneous computing
Parallel programming
Parallelism
Grain of computation
1.1 Introduction to Heterogeneous Computing
Heterogeneous computing includes both serial and parallel processing. With heterogeneous computing, tasks that comprise an application are mapped to the best processing device available on the system. The presence of multiple devices on a system presents an opportunity for programs to utilize concurrency and parallelism, and improve performance and power. Open Computing Language (OpenCL) is a programming language developed specifically to support heterogeneous computing environments. To help the reader understand many of the exciting features provided in OpenCL 2.0, we begin with an introduction to heterogeneous and parallel computing. We will then be better positioned to discuss heterogeneous programming in the context of OpenCL.
Today’s heterogeneous computing environments are becoming more multifaceted, exploiting the capabilities of a range of multicore microprocessors, central processing units (CPUs), digital signal processors, reconfigurable hardware (field-programmable gate arrays), and graphics processing units (GPUs). Presented with so much heterogeneity, the process of mapping the software task to such a wide array of architectures poses a number of challenges to the programming community.
Heterogeneous applications commonly include a mix of workload behaviors, ranging from control intensive (e.g. searching, sorting, and parsing) to data intensive (e.g. image processing, simulation and modeling, and data mining). Some tasks can also be characterized as compute intensive (e.g. iterative methods, numerical methods, and financial modeling), where the overall throughput of the task is heavily dependent on the computational efficiency of the underlying hardware device. Each of these workload classes typically executes most efficiently on a specific style of hardware architecture. No single device is best for running all classes of workloads. For instance, control-intensive applications tend to run faster on superscalar CPUs, where significant die real estate has been devoted to branch prediction mechanisms, whereas data-intensive applications tend to run faster on vector architectures, where the same operation is applied to multiple data items, and multiple operations are executed in parallel.
1.2 The Goals of This Book
The first edition of this book was the first of its kind to present OpenCL programming in a fashion appropriate for the classroom. In the second edition, we updated the contents for the OpenCL 1.2 standard. In this version, we consider the major changes in the OpenCL 2.0 standard, and we also consider a broader class of applications. The book is organized to address the need for teaching parallel programming on current system architectures using OpenCL as the target language. It includes examples for CPUs, GPUs, and their integration in the accelerated processing unit (APU). Another major goal of this book is to provide a guide to programmers to develop well-designed programs in OpenCL targeting parallel systems. The book leads the programmer through the various abstractions and features provided by the OpenCL programming environment. The examples offer the reader a simple introduction, and then proceed to increasingly more challenging applications and their associated optimization techniques. This book also discusses tools for aiding the development process in terms of profiling and debugging such that the reader need not feel lost in the development process. The book is accompanied by a set of instructor slides and programming examples, which support its use by an OpenCL instructor. Please visit http://store.elsevier.com/9780128014141 for additional information.
1.3 Thinking Parallel
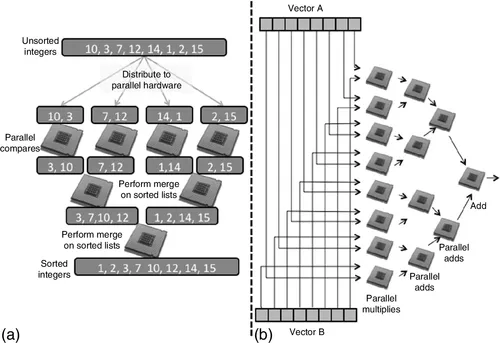
Most applications are first programmed to run on a single processor. In the field of high-performance computing, different approaches have been used to accelerate computation when provided with multiple computing resources. Standard approaches include “divide-and-conquer” and “scatter-gather” problem decomposition methods, providing the programmer with a set of strategies to effectively exploit the parallel resources available in high-performance systems. Divide-and-conquer methods iteratively break a problem into smaller subproblems until the subproblems fit well on the computational resources provided. Scatter-gather methods send a subset of the input data set to each parallel resource, and then collect the results of the computation and combine them into a result data set. As before, the partitioning takes account of the size of the subsets on the basis of the capabilities of the parallel resources. Figure 1.1 shows how popular applications such as sorting and a vector-scalar multiply can be effectively mapped to parallel resources to accelerate processing.
Figure 1.1 (a) Simple sorting: a divide-and-conquer implementation, breaking the list into shorter lists, sorting them, and then merging the shorter sorted lists. (b) Vector-scalar multiply: scattering the multiplies and then gathering the results to be summed up in a series of steps.
Programming has become increasingly challenging when faced with the growing parallelism and heterogeneity present in contemporary computing systems. Given the power and thermal limits of complementary metal-oxide semiconductor (CMOS) technology, microprocessor vendors find it difficult to scale the frequency of these devices to derive more performance, and have instead decided to place multiple processors, sometimes specialized, on a single chip. In their doing so, the problem of extracting parallelism from a application is left to the programmer, who must decompose the underlying tasks and associated algorithms in the application and map them efficiently to a diverse variety of target hardware platforms.
In the past 10 years, parallel computing devices have been increasing in number and processing capabilities. During this period, GPUs appeared on the computing scene, and are today providing new levels of processing capability at very low cost. Driven by the demands of real-time three-dimensional graphics rendering (a highly data-parallel problem), GPUs have evolved rapidly as very powerful, fully programmable, task- and data-parallel architectures. Hardware manufacturers are now combining CPU cores and GPU cores on a single die, ushering in a new generation of heterogeneous computing. Compute-intensive and data-intensive portions of a given application, called kernels, may be offloaded to the GPU, providing significant performance per watt and raw performance gains, while the host CPU continues to execute non-kernel tasks.
Many systems and phenomena in both the natural world and the man-made world present us with different classes of parallelism and concurrency:
•Molecular dynamics—every molecule interacting with every other molecule.
•Weather and ocean patterns—millions of waves and thousands of currents.
•Multimedia systems—graphics and sound, thousands of pixels and thousands of wavelengths.
•Automobile assembly lines—hundreds of cars being assembled, each in a different phase of assembly, with multiple identical assembly lines.
Parallel computing, as defined by Almasi and Gottlieb [1], is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently (i.e. in parallel). The degree of parallelism that can be achieved is dependent on the inherent nature of the problem at hand (remember that there exists significant parallelism in the world), and the skill of the algorithm or software designer to identify the different forms of parallelism present in the underlying problem. We begin with a discussion of two simple examples to demonstrate inherent parallel computation: multiplication of two integer arrays and text searching.
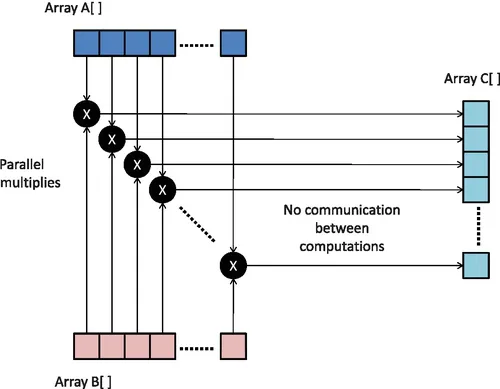
Our first example carries out multiplication of the elements of two arrays A and B, each with N elements storing the result of each multiply in the corresponding element of array C. Figure 1.2 shows the computation we would like to carry out. The serial C++ program code would be follows:
Figure 1.2 Multiplying elements in arrays A and B, and storing the result in an array C.
Listing 1.1 Multiplying elements of an array.
This code possesses significant parallelism, though a very low compute intensity. Low compute intensity in this context refers to the fact that the ratio of arithmetic operations to memory operations is small. The multiplication of each element in A and B is independent of every other element. If we were to parallelize this code, we could choose to generate a separate execution instance to perform the computation of each element of C. This code possesses significant data-level parallelism because the same operation is applied across all of A and B to produce C.
We could also view this breakdown as a simple form of task-level parallelism. A task is a piece of work to be done or undertaken, sometimes used instead of the operating system term process. In our discussion here, a task operates on a sub...
Table of contents
Cover image
Title page
Table of Contents
Copyright
List of Figures
List of Tables
Foreword
Acknowledgments
Chapter 1: Introduction
Chapter 2: Device architectures
Chapter 3: Introduction to OpenCL
Chapter 4: Examples
Chapter 5: OpenCL runtime and concurrency model
Chapter 6: OpenCL host-side memory model
Chapter 7: OpenCL device-side memory model
Chapter 8: Dissecting OpenCL on a heterogeneous system
Chapter 9: Case study: Image clustering
Chapter 10: OpenCL profiling and debugging
Chapter 11: Mapping high-level programming languages to OpenCL 2.0: A compiler writer’s perspective
Chapter 12: WebCL: Enabling OpenCL acceleration of Web applications
Chapter 13: Foreign lands: Plugging OpenCL in
Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Heterogeneous Computing with OpenCL 2.0 by David R. Kaeli,Perhaad Mistry,Dana Schaa,Dong Ping Zhang in PDF and/or ePUB format, as well as other popular books in Computer Science & Programming Languages. We have over one million books available in our catalogue for you to explore.