
- 106 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
About this book
With the rapid growth of Cloud computing, the size of Cloud data is expanding at a dramatic speed. A huge amount of data is generated and processed by Cloud applications, putting a higher demand on cloud storage. While data reliability should already be a requirement, data in the Cloud needs to be stored in a highly cost-effective manner. This book focuses on the trade-off between data storage cost and data reliability assurance for big data in the Cloud. Throughout the whole Cloud data lifecycle, four major features are presented: first, a novel generic data reliability model for describing data reliability in the Cloud; second, a minimum replication calculation approach for meeting a given data reliability requirement to facilitate data creation; third, a novel cost-effective data reliability assurance mechanism for big data maintenance, which could dramatically reduce the storage space needed in the Cloud; fourth, a cost-effective strategy for facilitating data creation and recovery, which could significantly reduce the energy consumption during data transfer.
- Captures data reliability with variable disk rates and compares virtual to physical disks
- Offers methods for reducing cloud-based storage cost and energy consumption
- Presents a minimum replication benchmark for data reliability requirements to evaluate various replication-based data storage approaches
Trusted by 375,005 students
Access to over 1 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
1
Introduction
Abstract
With the rapid growth in the size of Cloud data, cost-effective data storage has become one of the key issues in Cloud research, yet the reliability of the huge amounts of Cloud data needs to be fully assured. What we investigate in this book is the trade-off of cost-effective data storage and data reliability assurance in the Cloud. This chapter introduces the background knowledge and key issues of this research.
Keywords
background knowledge
Cloud storage
data reliability assurance technologies
data reliability definition
Introduction
key issue
With the rapid growth in the size of Cloud data, cost-effective data storage has become one of the key issues in Cloud research, yet the reliability of the huge amounts of Cloud data needs to be fully assured. In this book, we investigate the trade-off of cost-effective data storage and data reliability assurance in the Cloud. The novel research stands from the Cloud storage service providers’ perspective and investigates the issue on how to provide cost-effective data storage service while meeting the data reliability requirement throughout the whole Cloud data life cycle. This topic is important and has a practical value to Cloud computing technology. Especially, for data-intensive applications that are of data-intensive characteristics, our research could dramatically reduce its storage cost while meeting the data reliability requirement and hence has a positive impact on promoting the deployment of the Cloud.
This chapter introduces the background knowledge and key issues of this research. It is organized as follows. Section 1.1 gives the definition of data reliability and briefly introduces current data reliability assurance technologies in the Cloud. Section 1.2 introduces the background knowledge related to Cloud storage. Section 1.3 outlines the key issues of the research. Finally, Section 1.4 presents an overview for the book structure.
1.1. Data reliability in the Cloud
The term “reliability” is widely used as an aspect of the service quality provided by hardware, systems, Web services, etc. In Standard TL9000, it is defined as “the ability of an item to perform a required function under stated conditions for a stated time period” [1]. For data reliability specifically, which refers to the reliability provided by the data storage services and systems for the stored data, it can be defined as “the probability of the data surviving in the system for a given period of time” [2]. While the term “data reliability” is sometimes used in the industry as a superset of data availability and various other topics, in this book we will stick to the definition of data reliability given earlier.
Data reliability indicates the ability of the storage system to keep data consistent, hence it is always one of the key metrics of a data storage/management system. In large-scale distributed systems, due to the big quantity of storage devices being used, failures of storage devices occur frequently [3]. Therefore, the importance of data reliability is prominent, and these systems need better design and management to cope with frequent failures. Increasing the data redundancy level could be a good way for increasing data reliability [4,5]. Among several major approaches for increasing the data redundancy level, data replication is currently the most popular approach in distributed storage systems. At present, data replication has been widely adopted in many current distributed data storage/management systems in both industry and academia, which include examples such as OceanStore [6], DataGrid [7], Hadoop Distributed File System [8], Google File System [9], Amazon S3 [10], and so forth. In these storage systems, several replicas are created for each piece of data. These replicas are stored in different storage devices, so that the data have better chance to survive when storage device failures occur.
In recent years, Cloud computing is emerging as the latest distributed computing paradigm, which provides redundant, inexpensive, and scalable resources in a pay-as-you-go fashion to meet various application requirements [11]. Since the advent of Cloud computing in late 2007 [12], it has fast become one of the most promising distributed solutions in both industry and academia. Nowadays, with the rapid growth of Cloud computing, the size of Cloud storage is expanding at a dramatic speed. It is estimated that by 2015 the data stored in the Cloud will reach 0.8 ZB (i.e., 0.8 × 1021 bytes or 800,000,000 TB), while more data are “touched” by the Cloud within their life cycles [13]. For maintaining such a large amount of Cloud data, data reliability in the Cloud is considered more important than ever before. However, due to the accelerating growth of Cloud data, current replication-based data reliability management has become a bottleneck for the development of Cloud data storage. For example, storage systems such as Amazon S3, Google File System, and Hadoop Distributed File System all adopt similar data replication strategies called the “conventional multi-replica replication strategy,” in which a fixed number of replicas (normally three) are stored for all data to ensure the reliability requirement. For storage of the huge amounts of Cloud data, these conventional multi-replica replication strategies consume a lot of storage resources for additional replicas. This could cause negative effects for both the Cloud storage providers and users. On one hand, from the Cloud storage provider’s perspective, the excessive consumption of storage resources leads to a big storage overhead and increases the cost for providing the storage service. On the other hand, from the Cloud storage user’s perspective, according to the pay-as-you-go pricing model, the excessive storage resource usage will finally be paid by the storage users. For data-intensive Cloud applications specifically, the incurred excessive storage cost could be huge. Therefore, Cloud-based applications have put forward a higher demand for cost-effective management of Cloud storage. While the requirement of data reliability should be met in the first place, data in the Cloud needs to be stored in a highly cost-effective manner.
1.2. Background of Cloud storage
In this section, we briefly introduce the background knowledge of Cloud storage. First, we introduce the distinctive features of Cloud storage systems. Second, we introduce the Cloud data life cycle.
1.2.1. Distinctive features of Cloud storage systems
Data reliability is closely related to the structure of the storage system and how the storage system is being used. Different from other distributed storage systems, the Cloud storage system has some distinctive features that could either be advantages or challenges for the data reliability management of Cloud data.
1.2.1.1. On-demand self-service and pay-as-you-go pricing model
The on-demand usage of Cloud storage service and pay-as-you-go payment fashion have greatly facilitated the storage users that they only need to pay for the resources used for storing their data for a needed time period. The cost is easy to be estimated according to the size of data generated [14]. However, based on the pay-as-you-go model, every usage of the resources can be strictly reflected onto the bills payable at the end of the month. Therefore, minimizing resource consumption becomes demanding and critical. This principle is not only applicable to the service users, but also to the Cloud storage service providers. In most current Cloud storage services, excessive data redundancy is compulsorily generated to ensure data reliability. For data-intensive applications, such excessive data redundancy consumes a large amount of storage resources, and hence incurs a very high cost.
1.2.1.2. Redundant and scalable virtualized resources
In the Cloud, large amounts of virtualized computing and storage resources are pooled to serve users with various demands [1]. Redundant computing resources make it easy to conduct parallel processing, while the redundant storage resources make it easy to distribute data. For meeting a higher computing/storage demand, the resource pool can be scaled out rapidly, and the virtualization keeps the complex procedures transparent from the service users. However, the virtualization of resources has also led to a challenge that various kinds of data reliability requirement need to be fully assured to make the Cloud storage service trustworthy.
1.2.1.3. Dedicated Cloud network
Cloud systems (public Clouds specifically) are primarily running based on data centers with dedicated networks, which interconnect with each other using dedicated links [15]. Such a dedicated feature of the Cloud network has provided the Cloud the potential of full bandwidth control ability. The Cloud storage system could benefit from the dedicated Cloud network that the creation and recovery of data can be conducted in a fully controllable and predictable manner. At the meantime, there is still a great potential that data transfer in the Cloud network could be optimized for being conducted more cost-effectively.
1.2.1.4. Big data
“Big data” is the term for a collection of data sets so large and complex that it becomes difficult to store and process using traditional data storage and processing approaches. In Cloud storage systems, big data is one of the most distinctive features of the Cloud storage system. These data are generated by a large number of Cloud applications, many of which are data and computation intensive and of great importance to these applications. Moreover, the size of the Cloud data is growing even faster. Due to the huge amount of resources consumed by these data, efficient data management could generate huge value. For managing the massive amounts of Cloud data, the Cloud storage system needs to be powerful enough and able to meet the diverse needs of the data of different usages at different stages.
1.2.2. The Cloud data life cycle
The Cloud data life cycle refers to the period of time starting from the data being created (generated or uploaded) in the Cloud to the data being deleted when the storage space is reclaimed by the Cloud storage system. The life cycle of each piece of Cloud data consists of four stages, which are the data creation stage, the data maintenance stage, the data recovery stage, and the data deletion stage, as depicted in Figure 1.1.
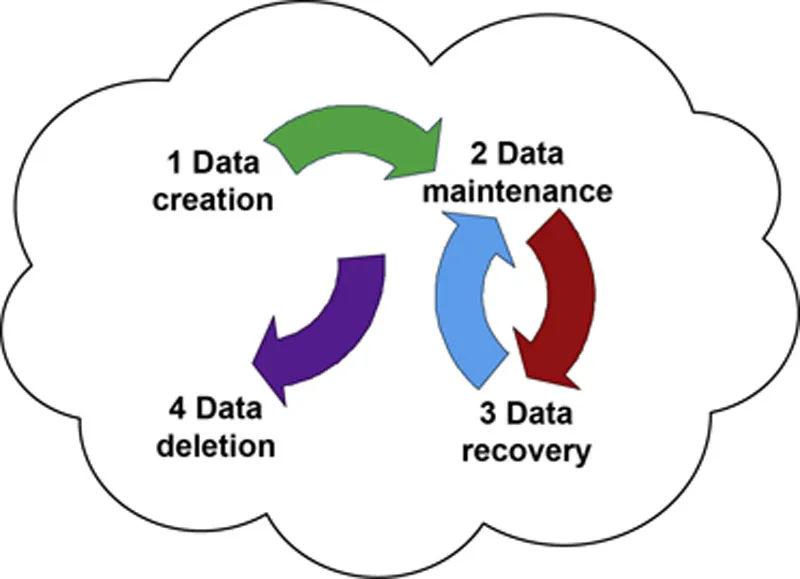
Figure 1.1 Cloud data life cycle
1.2.2.1. Data creation
The life cycle of Cloud data starts from the creation of the data in the Cloud storage system. When the original piece of Cloud data (the original replica for short) is created, certain numbers of additional replicas of the Cloud data also need to be created according to the specific reliability requirement of each piece of data and the storage policy [8,9]. All these replicas are transferred and stored on specific storage devices in a distributed fashion.
1.2.2.2. Data maintenance
After the data are created and stored, the data maintenance stage commences, which occupies the majority of the Cloud data life. At this stage, Cloud data are processed within applications to achieve different goals. However, for most of the time these data are just stored in storage devices waiting for later use. Certain mechanisms can be conducted to m...
Table of contents
- Cover
- Title page
- Table of Contents
- Copyright
- About the Authors
- Preface
- Acknowledgments
- 1: Introduction
- 2: Literature review
- 3: Motivating example and problem analysis
- 4: Generic data reliability model in the cloud
- 5: Minimum replication for meeting the data reliability requirement
- 6: Cost-effective data reliability assurance for data maintenance
- 7: Cost-effective data transfer for data creation and data recovery
- 8: Conclusions and future work
- Bibliography
- Appendix
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Reliability Assurance of Big Data in the Cloud by Yun Yang,Wenhao Li,Dong Yuan in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Science General. We have over one million books available in our catalogue for you to explore.