
eBook - ePub
Lexical Ambiguity Resolution
Perspective from Psycholinguistics, Neuropsychology and Artificial Intelligence
- 518 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Lexical Ambiguity Resolution
Perspective from Psycholinguistics, Neuropsychology and Artificial Intelligence
About this book
The most frequently used words in English are highly ambiguous; for example, Webster's Ninth New Collegiate Dictionary lists 94 meanings for the word "run" as a verb alone. Yet people rarely notice this ambiguity. Solving this puzzle has commanded the efforts of cognitive scientists for many years. The solution most often identified is "context": we use the context of utterance to determine the proper meanings of words and sentences. The problem then becomes specifying the nature of context and how it interacts with the rest of an understanding system. The difficulty becomes especially apparent in the attempt to write a computer program to understand natural language. Lexical ambiguity resolution (LAR), then, is one of the central problems in natural language and computational semantics research.
A collection of the best research on LAR available, this volume offers eighteen original papers by leading scientists. Part I, Computer Models, describes nine attempts to discover the processes necessary for disambiguation by implementing programs to do the job. Part II, Empirical Studies, goes into the laboratory setting to examine the nature of the human disambiguation mechanism and the structure of ambiguity itself.
A primary goal of this volume is to propose a cognitive science perspective arising out of the conjunction of work and approaches from neuropsychology, psycholinguistics, and artificial intelligence--thereby encouraging a closer cooperation and collaboration among these fields.
Lexical Ambiguity Resolution is a valuable and accessible source book for students and cognitive scientists in AI, psycholinguistics, neuropsychology, or theoretical linguistics.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Topic
InformaticaPART I
COMPUTER MODELS
Chapter 1
Word Expert Parsing Revisited in a Cognitive Science Perspective
Geert Adriaens, Siemens AI Research, Leuven, Belgium
Steven L Small1, Department of Computer Science, University of Rochester
Publisher Summary
This chapter discusses word expert parsing from the perspective of cognitive science. It additionally describes the general principles, representations and implementation of a computational model of natural language understanding—the Word Expert Parser—that attaches great importance to lexical ambiguity resolution. The chapter also discusses its flaws and merits as a model to understand human language. The greatest flaws are: (1) the absence of an implemented large-scale semantic network, (2) the absence of important psychological concept of spreading activation within that kind of network, (3)the impreciseness of the relationship between the time course of its operations, and (4) impreciseness of human language processing along with absence of true parallelism. The model has a number of merits as well: (1) its stress on the lexicon fits in with the general lexicalist approach in linguistics, (2) implements interactive view of language processing, (3) it works in accordance with a number of important results in psycho- and neurolinguistics, and (4) it yields interesting predictions about normal and aphasic behavior. These features make the model a valuable computational tool for cognitive science research in human natural language understanding.
1 Introduction
The Word Expert Parser (WEP) [Small, 1980] was an early AI model of natural language understanding to make a serious attempt at handling multiple senses of the words in its vocabulary.2 WEP was a semantic parsing program in which lexical ambiguity resolution was considered the essence of language understanding. This view led to a radical departure from other parsing models, and a system architecture based upon disambiguation mechanisms, which will be discussed in the next section of this chapter. Besides being a working AI program, WEP also claimed to be a model of the process of language comprehension in the human being. Although at the time little was done to confront these claims with results of linguistic, psychological, and neurological research, the growing importance of cognitive science has inspired such a confrontation. The third (and main) section of this chapter directly addresses this issue; we shall put WEP in a broader cognitive science perspective, discussing its flaws and merits through a confrontation with linguistics and psycholinguistics (for a confrontation with neurolinguistic research, see [Adriaens, 1986b]). The final section briefly discusses some issues for future research.
2 Lexical Ambiguity Resolution
2.1 General Principles
When we look at the words of a natural language (by skimming through a dictionary, or by introspection), we find that they are objects with a very rich and highly idiosyncratic content. Some help tie other words together (e.g., “a,” “the,” “in”), while others display a great number of different meanings (e.g., “deep,” “throw,” “pit”), from among which the human being is capable of picking the contextually appropriate one during comprehension.
A large number of existing parsing systems ignore this richness of individual words and the entirety of the sense selection problem. They advocate instead an approach that captures generalities about language in syntactic and/or semantic rules, treating the words as tokens that simply participate in comprehension by virtue of their inclusion in these rules (see [Rieger and Small, 1981]).
The apparent incompatibility of the sense selection problem and the rule-based approaches led to a radically different model organization. Instead of having a number of components (e.g., morphological, syntactic, semantic), consisting of static rule structures spanning sentence constituents or complete sentences, with some central interpreter taking care of the application of these rules to the input, the words themselves are considered as active agents, or word experts. They trigger processes that idiosyncratically control the whole parsing process. This process involves continuous interaction of a word with a number of knowledge sources in memory: the words in its immediate context, the concepts processed so far or expected locally, knowledge of the overall process state, knowledge of the discourse, and real-world knowledge. These knowledge sources are not invoked uniformly by a general interpreter, but are accessible at all times by the word expert processes throughout the overall process of sense discrimination. They help the experts to eventually agree on a context-specific semantic interpretation of a fragment of text. This overall parsing process makes crucial use of word-based expectations guiding the word experts in their sense discrimination.
In summary, word expert parsing is seen as a data-driven (word-by-word), expectation-based, highly interactive process coordinated by the individual words that are viewed as active knowledge sources (word experts). We will now take a closer look at matters of representation and implementation that turn these principles into a working program.
2.2 Representation
Informally, word experts can be viewed as sense discrimination networks consisting of nodes of context-probing questions and arcs corresponding to the range of possible answers. Each of the leaves of the network represents a specific contextual meaning of the word in question reached after network traversal during sentence processing. Figure 1.1 shows such an informal network for the highly ambiguous word “deep.” The left half of the net represents its adjectival usages ((1) through (4)), the right half its nominal ones ((5) through (7)). Meaning (1) would be arrived at in a context like “The deep philosopher likes Levinas,” (2) in a context like “He throws the ring into the deep pit”; meaning (5) would be chosen in the context “The giant squid still lives in the deep,” etc. for the other usages.
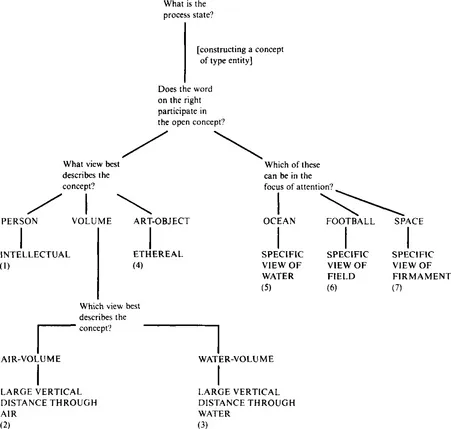
Figure 1.1 A sense discrimination network
These nets form the basis for the design and development of word experts, but have to be translated into a formal declarative representation used procedurally by the WEP process. Such a representation is a graph composed of designated subgraphs without cycles. Each subgraph (an “entry point”) consists of question nodes that probe the multiple knowledge sources mentioned above and action nodes that build and refine concepts, keep track of their lexical sequences, etc. These questions and actions constitute the formal representation language for word experts. We will not give a full description of the syntax and semantics of the word expert representation language here, but briefly mention the most important questions and actions that deal specifically with sense discrimination (excluding bookkeeping actions that keep track of lexical sequences, and internal expert control actions). The actions that deal with expert interaction are discussed in Section 2.3, the subsection about implementation. The Appendix contains an example word expert (the expert for “deep” that implements part of the network of Figure 1.1). A full description can be found in [Small, 1980], and partial descriptions in [Small and Rieger, 1982], [Small and Lucas, 1983], and [Adriaens, 1986b]. Figure 1.2 shows the questions and actions performing sense discrimination within the word experts.3

Figure 1.2 Sense discrimination questions and actions
The actions build concept structures as a side effect of the course of the overall parsing process. In WEP, these structures have received much less attention than the processing issues (how to control the expert interactions). Hence, not much will be said about them here. Nouns build entity concepts, that are refined by their modifiers; verbs assign roles to the entities, deciding on the contextually appropriate caseframe (the ROLEC action and its counterpart ASPECTC—see also Section 3.4). The result is a kind of dependency structure linking together all the concepts built up during the process.
The questions deserve a little more attention, since they direct the sense disambiguation process. An example of the SIGNAL question can be found in the word expert for “deep” in the Appendix. In order to find out at what point it enters the process, “deep” probes its incoming signal (if it is entity-construction, “deep...
Table of contents
- Cover image
- Title page
- Table of Contents
- Copyright
- Foreword
- Preface
- PART I: COMPUTER MODELS
- PART II: EMPIRICAL STUDIES
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Lexical Ambiguity Resolution by Steven L. Small,Garrison W Cottrell,Michael K Tanenhaus in PDF and/or ePUB format, as well as other popular books in Informatica & Intelligenza artificiale (IA) e semantica. We have over 1.5 million books available in our catalogue for you to explore.