![]()
Part 1
Introduction to Data Integration
Chapter 1 The Importance of Data Integration
Chapter 2 What Is Data Integration?
Chapter 3 Types and Complexity of Data Integration
Chapter 4 The Process of Data Integration Development
![]()
Chapter 1
The Importance of Data Integration
Information in this Chapter
The natural complexity of data interfaces
The rise of purchased vendor packages
Key enablement of big data and virtualization
The natural complexity of data interfaces
The average corporate computing environment is comprised of hundreds or even thousands of disparate and changing computer systems that have been built, purchased, and acquired. The data from these various systems needs to be integrated for reporting and analysis, shared for business transaction processing, and converted from one system format to another when old systems are replaced and new systems are acquired. Effectively managing the data passing between systems is a major challenge and a concern for every information technology organization.
Most data management focus is around data stored in structures such as databases and files, and a much smaller focus is on the data flowing between and around the data structures. Yet, management of the data interfaces in organizations is rapidly becoming a main concern for business and information technology (IT) management. As more systems are added to an organization’s portfolio, the number and complexity of the interfaces between the systems grow dramatically, making management of those interfaces overwhelming.
Traditional interface development quickly leads to a level of complexity that is unmanageable. The number of interfaces between applications and systems may become an exponential factor of the number of systems. In practice, not every system needs to interface with every other, but there may be multiple interfaces between systems for different types of data or needs. For an organization with 100 applications, there may be something like 5000 interfaces. A portfolio of 1000 applications may provide half a million interfaces to manage.
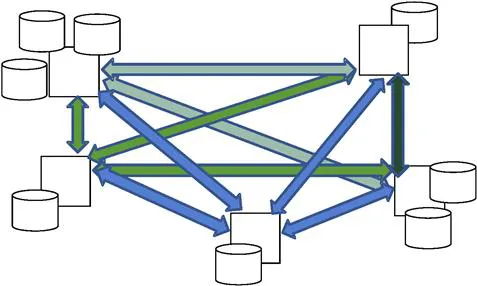
An implementation of some data integration best practice techniques can make the management of an organization’s interfaces much more reasonable than the traditional “point to point” data integration solutions, as depicted in Figure 1.1, which generate this type of management challenge. An organization that develops interfaces without an enterprise data integration strategy can quickly find managing the vast numbers of interfaces that ensue impossible.
Figure 1.1 Point-to-Point Interface Complexity.
The rise of purchased vendor packages
It has been the general consensus for years that, in most cases, except for strategically differentiating applications, it is more cost effective to purchase packages and configure appropriately for the organization, thus sharing the cost of developing functionality, supporting new feature development, and detecting and resolving problems across the various organizations using the software. Another term for purchased package is COTS (Commercial Off the Shelf) software.
Since the vast majority of software applications being implemented at organizations now are purchased vendor packages, the work and process of integrating the specific portfolio of software being run in a particular organization is one of the few remaining custom development activities. Software vendors can develop systems in ways to support integration and interactions with the other systems in the portfolio, but the specific portfolio of systems requiring integration in an organization, and therefore the data integration solution, are unique to each organization.
Most additions to the application system portfolio are purchased packages, but packages invariably will contain their own definition of important master data structures, such as customer, product, and organization hierarchy. Since master data will invariably exist in any custom applications as well as any other packages in the portfolio, it will be necessary to integrate the master data across the applications. Therefore, although the practice of purchasing application solutions rather than building custom makes the management and ongoing support of an application portfolio somewhat easier, it also makes the required integration of data across the application portfolio more complex than if all applications were custom developed and utilized common data structures.
Key enablement of big data and virtualization
In the emerging areas of big data, cloud processing, and data virtualization, critical components of the implementation of these technologies and solutions are data integration techniques.
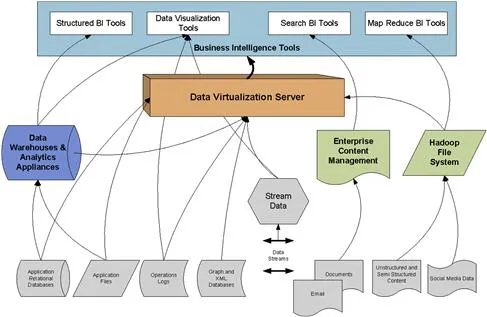
With big data, it is frequently a better solution, rather than consolidating data prior to analysis, to leave the vast amounts and various types of data where they are and distribute the processing out to the data, that is, a parallel processing solution. When the results of the requests have acted on the distributed data, the results need to be consolidated and returned. Data integration is critical to big data solutions, but the solutions may be significantly different from traditional data integration. As depicted in Figure 1.2, the arrows indicate the existence of data integration solutions to transport and consolidate data between the various and sundry data structures.
Figure 1.2 Big Data Architecture.
Cloud architectures with the external and virtual server solutions, data replication, and need for fault-tolerant solutions rely on data integration solutions. Again, however, the implementation of data integration solutions in a cloud environment is very different from those in traditional data centers, but builds on the basic concepts developed over the last two decades in data integration.
Infrastructure and server virtualization is widely implemented in many organizations because of the flexibility in infrastructure management it allows. These solutions play nicely with some data integration solutions but require adjustments with others, such as enterprise service bus technology.
In-memory data structures and processing can provide performance improvements of multiple magnitudes and rely on many data integration techniques, but they need to be implemented in ways that leverage the strengths of in-memory processing capabilities.
The capabilities of data virtualization represent the culmination of more than two decades of experience with data integration and many thousands of hours fine tuning various data integration techniques and technologies. With all its benefits, data virtualization can be viewed as a breakthrough that stands upon the experience with the disciplines of data warehousing, business intelligence, and, most critically, data integration.
![]()
Chapter 2
What Is Data Integration?
Information in this Chapter
Data in motion
Integrating into a common format—transforming data
Migrating data from one system to another
Moving data around the organization
Pulling information from unstructured data
Moving process to data
Data in motion
Planning the management of data in data stores is about “persistent” data that sits still. Managing the data that travels between systems, applications, data stores, and organizations—the “data in motion”—is central to the effectiveness of any organization and the primary subject of this book.
It shouldn’t be news that available, trusted data is absolutely critical to the success of every organization. The processes of making the data “trusted” is the subject of data governance and data quality, but making the data “available”—getting the data to the right place, at the right time, and in the right format—is the subject of data integration.
The practice associated with managing data that travels between applications, data stores, systems, and organizations is traditionally called data integration (DAMA international, 2009). This terminology may be a little misleading to those who are not used to the term. Data integration intuitively sounds to be more about the consolidation of data, but it is the movement, not the persistence that is the focus. Data interface refers to an applic...