
- 368 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
About this book
This book brings all of the elements of database design together in a single volume, saving the reader the time and expense of making multiple purchases. It consolidates both introductory and advanced topics, thereby covering the gamut of database design methodology ? from ER and UML techniques, to conceptual data modeling and table transformation, to storing XML and querying moving objects databases. The proposed book expertly combines the finest database design material from the Morgan Kaufmann portfolio. Individual chapters are derived from a select group of MK books authored by the best and brightest in the field. These chapters are combined into one comprehensive volume in a way that allows it to be used as a reference work for those interested in new and developing aspects of database design. This book represents a quick and efficient way to unite valuable content from leading database design experts, thereby creating a definitive, one-stop-shopping opportunity for customers to receive the information they would otherwise need to round up from separate sources.
- Chapters contributed by various recognized experts in the field let the reader remain up to date and fully informed from multiple viewpoints.
- Details multiple relational models and modeling languages, enhancing the reader's technical expertise and familiarity with design-related requirements specification.
- Coverage of both theory and practice brings all of the elements of database design together in a single volume, saving the reader the time and expense of making multiple purchases.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Chapter 1. Introduction
Database technology has evolved rapidly in the three decades since the rise and eventual dominance of relational database systems. While many specialized database systems (object-oriented, spatial, multim, etc.) have found substantial user communities in the science and engineering fields, relational systems remain the dominant database technology for business enterprises.
Relational database design has evolved from an art to a science that has been made partially implementable as a set of software design aids. Many of these design aids have appeared as the database component of computer-aided software engineering (CASE) tools, and many of them offer interactive modeling capability using a simplified data modeling approach. Logical design—that is, the structure of basic data relationships and their definition in a particular database system—is largely the domain of application designers. These designers can work effectively with tools such as ERwin Data Modeler or Rational Rose with UML, as well as with a purely manual approach. Physical design, the creation of efficient data storage and retrieval mechanisms on the computing platform being used, is typically the domain of the database administrator (DBA). Today's DBAs have a variety of vendor-supplied tools available to help them design the most efficient databases. This book is devoted to the logical design methodologies and tools most popular for relational databases today. This chapter reviews the basic concepts of database management and introduce the role of data modeling and database design in the database life cycle.
1.1. Data and Database Management
The basic component of a file in a file system is a data item, which is the smallest named unit of data that has meaning in the real world—for example, last name, first name, street address, ID number, or political party. A group of related data items treated as a single unit by an application is called a record. Examples of types of records are order, salesperson, customer, product, and department. A file is a collection of records of a single type. Database systems have built upon and expanded these definitions: In a relational database, a data item is called a column or attribute; a record is called a row or tuple; and a file is called a table.
A database is a more complex object. It is a collection of interrelated stored data—that is, interrelated collections of many different types of tables—that serves the needs of multiple users within one or more organizations. The motivations for using databases rather than files include greater availability to a diverse set of users, integration of data for easier access to and updating of complex transactions, and less redundancy of data.
A database management system (DBMS) is a generalized software system for manipulating databases. A DBMS supports a logical view (schema, subschema); physical view (access methods, data clustering); data definition language; data manipulation language; and important utilities, such as transaction management and concurrency control, data integrity, crash recovery, and security. Relational database systems, the dominant type of systems for well-formatted business databases, also provide a greater degree of data independence than the earlier hierarchical and network (CODASYL) database management systems. Data independence is the ability to make changes in either the logical or physical structure of the database without requiring reprogramming of application programs. It also makes database conversion and reorganization much easier. Relational DBMSs provide a much higher degree of data independence than previous systems; they are the focus of our discussion on data modeling.
1.2. The Database Life Cycle
The database life cycle incorporates the basic steps involved in designing a global schema of the logical database, allocating data across a computer network, and defining local DBMS-specific schemas. Once the design is completed, the life cycle continues with database implementation and maintenance. This chapter contains an overview of the database life cycle, as shown in Figure 1.1. The result of each step of the life cycle is illustrated with a series of diagrams in Figure 1.2. Each diagram shows a possible form of the output of each step, so the reader can see the progression of the design process from an idea to actual database implementation.
Figure 1.1. The database life cycle.
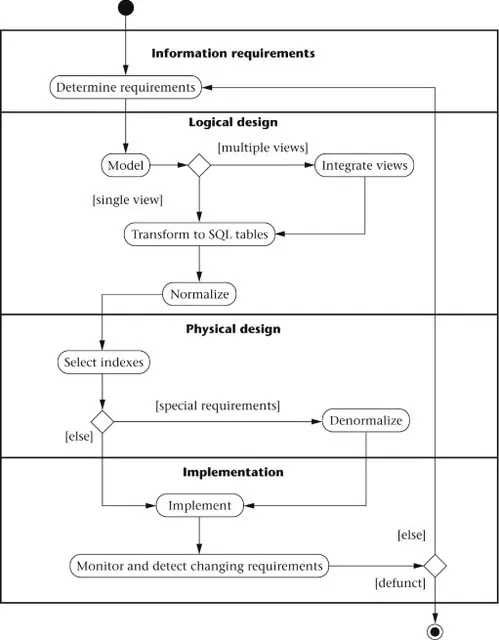
Figure 1.2. Life cycle results, step-by-step.
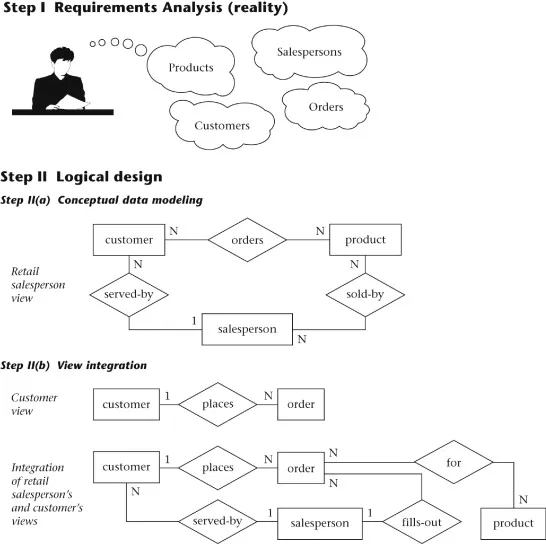
- Requirements analysis. The database requirements are determined by interviewing both the producers and users of data and using the information to produce a formal requirements specification. That specification includes the data required for processing, the natural data relationships, and the software platform for the database implementation. As an example, Figure 1.2 (step I) shows the concepts of products, customers, salespersons, and orders being formulated in the mind of the end user during the interview process.
- Logical design. The global schema, a conceptual data model diagram that shows all the data and their relationships, is developed using techniques such as entity–relationship (ER) or UML. The data model constructs must ultimately be transformed into normalized (global) relations, or tables. The global schema development methodology is the same for either a distributed or centralized database.
- Conceptual data modeling. The data requirements are analyzed and modeled using an ER or UML diagram that includes, for example, semantics for optional relationships, ternary relationships, supertypes, and subtypes (categories). Processing requirements are typically specified using natural language expressions or SQL commands, along with the frequency of occurrence. Figure 1.2 (step II(a)) shows a possible ER model representation of the product/customer database in the mind of the end user.
- View integration. Usually, when the design is large and more than one person is involved in requirements analysis, multiple views of data and relationships result. To eliminate redundancy and inconsistency from the model, these views eventually must be “rationalized” (resolving inconsistencies due to variance in taxonomy, context, or perception) and then consolidated into a single global view. View integration requires the use of ER semantic tools such as identification of synonyms, aggregation, and generalization. In Figure 1.2 (step II(b)), two possible views of the product/customer database are merged into a single global view based on common data for customer and order. View integration is also important for application integration.
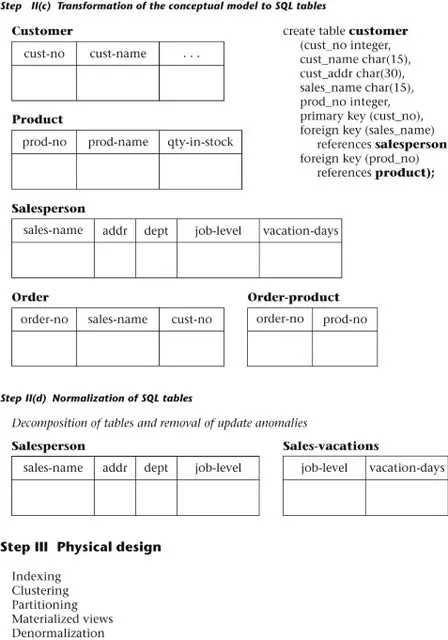
- Transformation of the conceptual data model to SQL tables. Based on a categorization of data modeling constructs and a set of mapping rules, each relationship and its associated entities are transformed into a set of DBMS-specific candidate relational tables. Redundant tables are eliminated as part of this process. In our example, the tables in step II(c) of Figure 1.2 are the result of transformation of the integrated ER model in step II(b).
- Normalization of tables. Functional dependencies (FDs) are derived from the conceptual data model diagram and the semantics of data relationships in the requirements analysis. They represent the dependencies among data elements that are unique identifiers (keys) of entities. Additional FDs that represent the dependencies among key and nonkey attributes within entities can be derived from the requirements specification. Candidate relational tables associated with all derived FDs are normalized (i.e., modified by decomposing or splitting tables into smaller tables) using standard techniques. Finally, redundancies in the data in normalized candidate tables are analyzed further for possible elimination, with the constraint that data integrity must be preserved. An example of normalization of the Salesperson table into the new Salesperson and Sales-vacations tables is shown in Figure 1.2 from step II(c) to step II(d).We note here that database tool vendors tend to use the term logical model to refer to the conceptual data model, and they use the term physical model to refer to the DBMS-specific implementation model (e.g., SQL tables). Note also that many conceptual data models are obtained not from scratch, but from the process of reverse engineering from an existing DBMS-specific schema (Silberschatz, Korth, & Sudarshan, 2002).
- Physical design. The physical design step involves the selection of indexes (access methods), partitioning, and clustering of data. The logical design methodology in step II simplifies the approach to designing large relational databases by reducing the number of data dependencies that need to be analyzed. This is accomplished by inserting conceptual data modeling and integration steps (II(a) and II(b) of Figure 1.2) into the traditional relational design approach. The objective of these steps is an accurate representation of reality. Data integrity is preserved through normalization of the candidate tables created when the conceptual data model is transformed into a relational model. The purpose of physical design is to optimize performance as closely as possible.As part of the physical design, the global schema can sometimes be refined in limited ways to reflect processing (query and transaction) requirements if there are obvious, large gains to be made in efficiency. This is called denormalization. It consists of selecting dominant processes on the basis of high frequency, high volume, or explicit priority; defining simple extensions to tables that will improve query performance; evaluating total cost for query, update, and storage; and considering the side effects, such as possible loss of integrity. This is particularly important for Online Analytical Processing (OLAP) applications.
- Database implementation, monitoring, and modification. Once the design is completed, the database can be created through implementation of the formal schema using the data definition language (DDL) of a DBMS. Then the data manipulation language (DML) can be used to query and update the database, as well as to set up indexes and establish constraints, such as referential integrity. The language SQL contains both DDL and DML constructs; for example, the create table command represents DDL, and the select command represents DML.As the database begins operation, monitoring indicates whether performance requirements are being met. If they are not being satisfied, modifications should be...
Table of contents
- Copyright
- Brief Table of Contents
- Table of Contents
- List of Figures
- List of Tables
- Copyright Page
- About This Book
- Contributing Authors
- Chapter 1. Introduction
- Chapter 2. Entity–Relationship Concepts
- Chapter 3. Data Modeling in UML
- Chapter 4. Requirements Analysis and Conceptual Data Modeling
- Chapter 5. Logical Database Design
- Chapter 6. Normalization
- Chapter 7. Physical Database Design
- Chapter 8. Denormalization
- Chapter 9. Business Metadata Infrastructure
- Chapter 10. Storing
- Chapter 11. Modeling and Querying Current Movement
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Database Design: Know It All by Toby J. Teorey,Tony Morgan,Thomas P. Nadeau,Bonnie O'Neil,Elizabeth O'Neil,Patrick O'Neil,Markus Schneider,Graeme Simsion,Graham Witt,Stephen Buxton,Lowell Fryman,Ralf Hartmut Güting,Terry Halpin,Jan L. Harrington,W.H. Inmon,Sam S. Lightstone,Jim Melton in PDF and/or ePUB format, as well as other popular books in Computer Science & Databases. We have over one million books available in our catalogue for you to explore.