
eBook - ePub
TCP/IP Sockets in C#
Practical Guide for Programmers
- 175 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
TCP/IP Sockets in C#
Practical Guide for Programmers
About this book
"TCP/IP sockets in C# is an excellent book for anyone interested in writing network applications using Microsoft .Net frameworks. It is a unique combination of well written concise text and rich carefully selected set of working examples. For the beginner of network programming, it's a good starting book; on the other hand professionals could also take advantage of excellent handy sample code snippets and material on topics like message parsing and asynchronous programming."Adarsh Khare, SDT, .Net Frameworks Team, Microsoft CorporationThe popularity of the C# language and the .NET framework is ever rising due to its ease of use, the extensive class libraries available in the .NET Framework, and the ubiquity of the Microsoft Windows operating system, to name a few advantages. TCP/IP Sockets in C# focuses on the Sockets API, the de facto standard for writing network applications in any programming language. Starting with simple client and server programs that use TCP/IP (the Internet protocol suite), students and practitioners quickly learn the basics and move on to firsthand experience with advanced topics including non-blocking sockets, multiplexing, threads, asynchronous programming, and multicasting. Key network programming concepts such as framing, performance and deadlocks are illustrated through hands-on examples. Using a detailed yet clear, concise approach, this book includes numerous code examples and focused discussions to provide a solid understanding of programming TCP/IP sockets in C#.Features*Tutorial-based instruction in key sockets programming techniques complemented by numerous code examples throughout *Discussion moves quickly into the C# Sockets API definition and code examples, desirable for those who want to get up-to-speed quickly*Important coverage of "under the hood" details that developers will find useful when creating and using a socket or a higher level TCP class that utilizes sockets*Includes end-of-chapter exercises to facilitate learning, as well as sample code available for download at the book's companion web site*Tutorial-based instruction in key sockets programming techniques complemented by numerous code examples throughout *Discussion moves quickly into the C# Sockets API definition and code examples, desirable for those who want to get up-to-speed quickly*Important coverage of "under the hood" details that developers will find useful when creating and using a socket or a higher level TCP class that utilizes sockets*Includes end-of-chapter exercises to facilitate learning, as well as sample code available for download at the book's companion web site
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
Chapter 1 Introduction
Millions of computers all over the world are now connected to the worldwide network known as the Internet. The Internet enables programs running on computers thousands of miles apart to communicate and exchange information. If you have a computer connected to a network, you have undoubtedly used a Web browser—a typical program that makes use of the Internet. What does such a program do to communicate with others over a network? The answer varies with the application and the operating system (OS), but a great many programs get access to network communication services through the “sockets” application programming interface (API). The goal of this book is to get you started writing programs that use the sockets API.
Before delving into the details of the API, it is worth taking a brief look at the big picture of networks and protocols to see how an application programming interface for TCP/IP fits in. Our goal here is not to teach you how networks and TCP/IP work—many fine texts are available for that purpose [2, 4, 10, 15, 20]—but rather to introduce some basic concepts and terminology.
1.1 Networks, Packets, and Protocols
A computer network consists of machines interconnected by communication channels. We call these machines hosts and routers. Hosts are computers that run applications such as your Web browser, the application programs running on hosts are really the users of the network. Routers are machines whose job is to relay or forward information from one communication channel to another. They may run programs but typically do not run application programs. For our purposes, a communication channel is a means of conveying sequences of bytes from one host to another; it may be a broadcast technology like Ethernet, a dial-up modem connection, or something more sophisticated.
Routers are important simply because it is not practical to connect every host directly to every other host. Instead, a few hosts connect to a router, which connects to other routers, and so on to form the network. This arrangement lets each machine get by with a relatively small number of communication channels; most hosts need only one. Programs that exchange information over the network, however, do not interact directly with routers and generally remain blissfully unaware of their existence.
By information we here mean a sequences of bytes that are constructed and interpreted by programs. In the context of computer networks these byte sequences are generally called packets. A packet contains control information that the network uses to do its job and sometimes also includes user data. An example is information about the packet’s destination. Routers use such control information to figure out how to forward each packet.
A protocol is an agreement about the packets exchanged by communicating programs and what they mean. A protocol tells how packets are structured—for example, where the destination information is located in the packet and how big it is—as well as how the information is to be interpreted. A protocol is usually designed to solve a specific problem using given capabilities. For example, the Hypertext Transfer Protocol (HTTP) solves the problem of transferring hypertext objects between servers where they are stored and Web browsers that make them available to human users.
Implementing a useful network requires that a large number of different problems be solved. To keep things manageable and modular, different protocols are designed to solve different sets of problems. TCP/IP is one such collection of solutions, sometimes called a protocol suite. It happens to be the suite of protocols used in the Internet, but it can be used in stand-alone private networks as well; henceforth when we say “the network,” we mean any network that uses the TCP/IP protocol family. The main protocols in the TCP/IP family are the Internet Protocol (IP), the Transmission Control Protocol (TCP), and the User Datagram Protocol (UDP).
It turns out to be useful to organize protocols in a family into layers; TCP/IP and virtually all other protocol families are organized this way. Figure 1.1 shows the relationships among the protocols, applications, and the sockets API in the hosts and routers, as well as the flow of data from one application (using TCP) to another. The boxes labeled TCP, UDP, and IP represent implementations of those protocols. Such implementations typically reside in the operating system of a host. Applications access the services provided by UDP and TCP through the sockets API. The arrow depicts the flow of data from the application, through the TCP and IP implementations, through the network, and back up through the IP and TCP implementations at the other end.
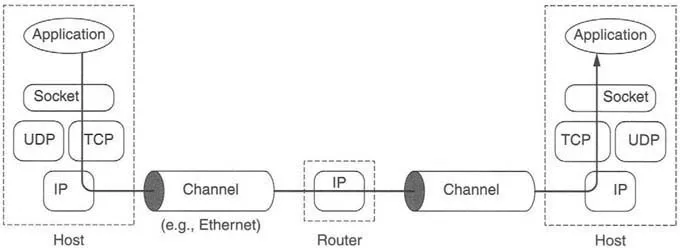
Figure 1.1: A TCP/IP network.
In TCP/IP, the bottom layer consists of the underlying communication channels, such as Ethernet or dial-up modem connections. Those channels are used by the network layer, which deals with the problem of forwarding packets toward their destination (i.e., what routers do). The single network layer protocol in the TCP/IP family is the Internet Protocol; it solves the problem of making the sequence of channels and routers between any two hosts look like a single host-to-host channel.
The Internet Protocol provides a datagram service: Every packet is handled and delivered by the network independently, like telegrams or parcels sent via the postal system. To make this work, each IP packet has to contain the address of its destination, just as every package you mail is addressed to somebody. (We’ll say more about addresses shortly.) Although most parcel delivery companies guarantee delivery of a package, IP is only a best-effort protocol: It attempts to deliver each packet, but it can (and occasionally does) lose, reorder, or duplicate packets in transit through the network.
The layer above IP is called the transport layer. It offers a choice between two protocols: TCP and UDP. Each builds on the service provided by IP, but they do so in different ways to provide different kinds of channels, which are used by application protocols with different needs. TCP and UDP have one function in common: addressing. Recall that IP delivers packets to hosts; clearly, a finer granularity of addressing is needed to get a packet to a particular application, perhaps one of many using the network in the same host. Both TCP and UDP use addresses called port numbers so that applications within hosts can be identified. They are called end-to-end transport protocols because they carry data all the way from one program to another (whereas IP carries data from one host to another).
TCP is designed to detect and recover from the losses, duplications, and other errors that may occur in the host-to-host channel provided by IP. TCP provides a reliable byte-stream channel, so that applications don’t have to deal with these problems. It is a connection-oriented protocol: Before using it to communicate, two programs must first establish a TCP connection, which involves completing an exchange of handshake messages between the TCP implementations on the two communicating computers. Using TCP is similar to file input/output (I/O). In fact, a file that is written by one program and read by another is a reasonable mode of communication over a TCP connection. UDP, on the other hand, does not attempt to recover from errors experienced by IP; it simply extends the IP best-effort datagram service so that it works between applications programs instead of between hosts. Thus, applications that use UDP must be prepared to deal with losses, reordering, and so on.
1.2 About Addresses
When you mail a letter, you provide the address of the recipient in a form that the postal service can understand. Before you can talk to somebody on the phone, you must supply their number to the telephone system. In a similar way, before a program can communicate with another program, it must tell the network where to find the other program. In TCP/IP, it takes two pieces of information to identify a particular program: an Internet address, used by IP, and a port number, the additional address interpreted by the transport protocol (TCP or UDP).
Internet addresses are 32-bit binary numbers.1 In writing down Internet addresses for human consumption (as opposed to using them inside applications), we typically show them as a string of four decimal numbers separated by periods (e.g., 10.1.2.3); this is called the dotted-quad notation. The four numbers in a dotted-quad string represent the contents of the four bytes of the Internet address, thus each is a number between 0 and 255.
Technically, each Internet address refers to the connection between a host and an underlying communication channel, such as a dial-up modem or Ethernet card. Because each such network connection belongs to a single host, an Internet address identifies a host as well as its connection to the network. However, because a host can have multiple physical connections (interfaces) to the network, one host can have multiple Internet addresses.
The port number in TCP or UDP is always interpreted relative to an Internet address. Returning to our earlier analogies, a port number corresponds to a room number at a given street address, say, that of a large building. The postal service uses the street address to get the letter to a mailbox; whoever empties the mailbox is then responsible for getting the letter to the proper room within the building. Or consider a company with an internal telephone system: To speak to an individual in the company, you first dial the company’s main number to connect to the internal telephone system, and then dial the extension of the particular telephone of the individual you wish to speak with. In these analogies, the Internet address is the street address or the company’s main number, whereas the port corresponds to the room number or telephone extension. Port numbers are 16-bit unsigned binary numbers, so each one is in the range of 1 to 65,535 (0 is reserved).
1.3 About Names
Most likely you are accustomed to referring to hosts by name (e.g., host.example.com). However, the Internet protocols deal with numerical addresses, not names. You should understand that the use of names instead of addresses is a convenience feature that is independent of the basic service provided by TCP/IP—you can write and use TCP/IP applications without ever using a name. When you use a name to identify a communication endpoint, the system has to do some extra work to resolve the name into an address.
This extra step is often worth it, for a couple of reasons. First, names are generally easier for humans to remember than dotted-quads. Second, names provide a level of indirection, which insulates users from IP address changes. During the writing of this book, the Web server for the publisher of this text, Morgan Kaufmann, changed Internet addresses from 213.38.165.180 to 129.35.78.178. However, because we refer to that Web server as www.mkp.com (clearly much easier to remember than 213.38.165.180), and because the change is reflected in the system that maps names to addresses (www.mkp.com now resolves to the new Internet address instead of 213.38.165.180), the change is transparent to programs that use the name to access the Web server.
The name-resolution service can access information from a wide variety of sources. Two of the primary sources are the Domain Name System (DNS) and local configuration databases. The DNS [8] is a distributed database that maps domain names such as www.mkp.com to Internet addresses and other information; the DNS protocol [9] allows hosts connected to the Internet to retrieve information from that database using TCP or UDP. Local configuration databases are generally OS-specific mechanisms for local name-to-internet address mappings. Microsoft Windows provides a hosts text file where IP-to-domain-name mappings can be hard-coded or overridden. UNIX-based systems typically have a file called/etc/hosts that does the same thing.
1.4 Clients and Servers
In our postal and telephone analogies, each communication is initiated by one party, who sends a letter or dials a telephone call, while the other party responds to the initiator’s contact by sending a return letter or picking up the phone and talking. Internet communication is similar. The terms client and server refer to these roles: The client program initiates communication, while the server program waits passively for and then responds to clients that contact it. Together, the client and server compose the application. The terms client and server are descriptive of the typical situation in which the server makes a particular capability—for example, a database service—available to any client that is able to communicate with it.
Whether a program is acting as a client or server determines the general form of its use of the sockets API to communicate with its peer. (The client is the peer of the server ...
Table of contents
- Cover
- Title Page
- Copyright
- Table of Contents
- Preface
- Chapter 1: Introduction
- Chapter 2: Basic Sockets
- Chapter 3: Sending and Receiving Messages
- Chapter 4: Beyond the Basics
- Chapter 5: Under the Hood
- Handling Socket Errors
- Bibliography
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access TCP/IP Sockets in C# by David Makofske,Michael J. Donahoo,Kenneth L. Calvert in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Networking. We have over one million books available in our catalogue for you to explore.