
- 976 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Information Modeling and Relational Databases
About this book
Information Modeling and Relational Databases, Second Edition, provides an introduction to ORM (Object-Role Modeling)and much more. In fact, it is the only book to go beyond introductory coverage and provide all of the in-depth instruction you need to transform knowledge from domain experts into a sound database design. This book is intended for anyone with a stake in the accuracy and efficacy of databases: systems analysts, information modelers, database designers and administrators, and programmers.
Terry Halpin, a pioneer in the development of ORM, blends conceptual information with practical instruction that will let you begin using ORM effectively as soon as possible. Supported by examples, exercises, and useful background information, his step-by-step approach teaches you to develop a natural-language-based ORM model, and then, where needed, abstract ER and UML models from it. This book will quickly make you proficient in the modeling technique that is proving vital to the development of accurate and efficient databases that best meet real business objectives.
- Presents the most indepth coverage of Object-Role Modeling available anywhere, including a thorough update of the book for ORM2, as well as UML2 and E-R (Entity-Relationship) modeling
- Includes clear coverage of relational database concepts, and the latest developments in SQL and XML, including a new chapter on the impact of XML on information modeling, exchange and transformation
- New and improved case studies and exercises are provided for many topics
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
1 Introduction
1.1 Information Modeling
• Information = data + semantics
• Database systems
• The need for good design
1.2 Information Modeling Approaches
• ORM
• ER
• UML
1.3 Historical Background
• Computer language generations
• Database kinds
1.4 The Relevant Skills
• Modeling
• Querying
1.5 Summary
Information Modeling
It’s an unfortunate fact of life that names and numbers can sometimes be misinterpreted. This can prove costly, as experienced by senior citizens who had their social security benefits cut off when government agencies incorrectly pronounced them dead because of misreading “DOD” on hospital forms as “date of death” rather than the intended “date of discharge”.
A more costly incident occurred in 1999 when NASA’s $125 million Mars Climate Orbiter burnt up in the Martian atmosphere. Apparently, errors in its course settings arose from a failure to make a simple unit conversion. One team worked in U.S. customary units and sent its data to a second team working in metric, but no conversion was made. If a man weighs 180, does he need to go on a drastic diet? No if his mass is 180 lb, but yes if it’s 180 kg. Data by itself is not enough. What we really need is information, the meaning or semantics of the data. Since computers lack common sense, we need to pay special attention to semantics when we use computers to model some aspect of reality.
This book provides a modern introduction to database systems, with the emphasis on information modeling. At its heart is a very high level semantic approach that is fact-oriented in nature. If you model databases using either traditional or object-oriented approaches, you’ll find that fact orientation lifts your thinking to a higher level, illuminating your current way of doing things. Even if you’re a programmer rather than a database modeler, this semantic approach provides a natural and powerful way to design your data structures.
A database is basically a collection of related data (e.g., a company’s personnel records). When interpreted by humans, a database may be viewed as a set of related facts—an information base. In the context of our semantic approach, we’ll often use the popular term “database” instead of the more technical “information base”. Discovering the kinds of facts that underlie a business domain, and the rules that apply to the facts, is interesting and revealing. The quality of the database design used to capture these facts and rules is critical. Just as a house built from a good architectural plan is more likely to be safe and convenient for living, a well-designed database simplifies the task of ensuring that its facts are correct and easy to access. Let’s review some basic ideas about database systems, and then see how things can go wrong if they are poorly designed.
Each database models a business domain—we use this term to describe any area of interest, typically a part of the real world. Consider a library database. As changes occur in the library (e.g., a book is borrowed) the database is updated to reflect these changes. This task could be performed manually using a card catalog, or be automated with an online catalog, or both. Our focus is on automated databases. Sometimes these are implemented by means of special-purpose computer programs, coded in a general-purpose programming language (e.g., C#). More often, database applications are developed using a database management system (DBMS). This is a software system for maintaining databases and answering queries about them (e.g., DB2, Oracle, SQL Server). The same DBMS may handle many different databases.
Typical applications use a database to house the persistent data, an in-memory object model to hold transient data, and a friendly user interface for users to enter and access data. All these structures deal with information and are best derived from an information model that clearly reveals the underlying semantics of the domain. Some tools can use information models to automatically generate not just databases, but also object models and user interfaces.
If an application requires maintenance and retrieval of lots of data, a DBMS offers many advantages over manual record keeping. Data may be conveniently captured via electronic interfaces (e.g., screen forms), then quickly processed and stored compactly on disk. Many data errors can be detected automatically, and access rights to data can be enforced by the system. People can spend more time on creative design rather than on routine tasks more suited to computers. Finally, developing and documenting the application software can be facilitated by use of computer-assisted software engineering (CASE) tool support.
In terms of the dominant employment group, the Agricultural Age was supplanted late in the 19th century by the Industrial Age, which is now replaced by the Information Age. With the ongoing information explosion and mechanization of industry, the proportion of information workers is steadily rising. Most businesses achieve significant productivity gains by exploiting information technology. Imagine how long a newspaper firm would last if it returned to the methods used before word processing and computerized typesetting. Apart from its enabling employment opportunities, the ability to interact efficiently with information systems empowers us to exploit their information content.
Although most employees need to be familiar with information technology, there are vast differences in the amount and complexity of information management tasks required of these workers. Originally, most technical computer work was performed by computer specialists such as programmers and systems analysts. However, the advent of user-friendly software and powerful, inexpensive personal computers led to a redistribution of computing power. End users now commonly perform many information management tasks, such as spreadsheeting, with minimal reliance on professional computer experts.
This trend toward more users “driving” their own computer systems rather than relying on expert “chauffeurs” does not eliminate the need for computer specialists. There is still a need for programming in languages such as C# and Java. However, there is an increasing demand for high level skills such as modeling complex information systems.
The area of information systems engineering includes subdisciplines such as requirements analysis, database design, user interface design, and report writing. In one way or another, all these subareas deal with information. Since the database design phase selects the underlying structures to capture the relevant information, it is of central importance.
To highlight the need for good database design, let’s consider the task of designing a database to store movie details such as those shown in Table 1.1. The header of this table is shaded to help distinguish it from the rows of data. Even if the header is not shaded, we do not count it as a table row. The first row of data is fictitious.
Table 1.1 An output report about some motion pictures.
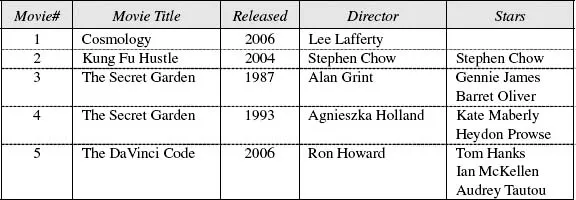
Different movies may have the same title (e.g., The Secret Garden). Hence movie numbers are used to provide a simple identifier. We interpret the data in terms of facts. For example, movie 5 has the title The DaVinci Code, was released in 2006, was directed by Ron Howard, and starred Tom Hanks, Ian McKellen, and Audrey Tautou. Movie 1, titled Cosmology, had no stars (it is a documentary). This table is an output report. It provides one way to view the data. This might not be the same as how the data is actually stored in a database.
In Table 1.1 each cell (row-column slot) may contain many values. For example, Movie 3 has two stars recorded in the row 3, column 5 cell. Some databases allow a cell to contain many values like this, but in a relational database each table cell may hold at most one value. Since relational database systems are dominant in the industry, our implementation discussion focuses on them. How can we design a relational database to store these facts?
Suppose we use the structure shown in Table 1.2. This has one entry in each cell. Here, “?” denotes a null (no star is recorded for Cosmology). Some DBMSs display nulls differently (e.g., “<NULL>” or a blank space). To help distinguish the rows, we’ve included lines between them. But from now on, we’ll omit lines between rows.
Table 1.2 A badly-designed relational database table.
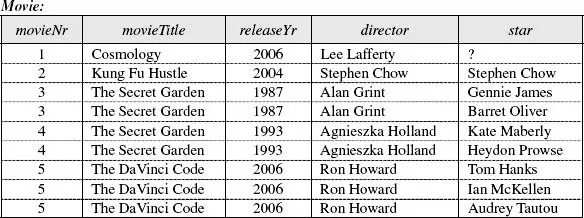
Each relational table must be named. Here we ca...
Table of contents
- Cover Image
- Title page
- The Morgan Kaufmann Series in Data Management Systems (Selected Titles)
- Copyright
- Dedication
- Foreword
- Foreword
- Foreword
- Preface
- Table of Contents
- Chapter 1: Introduction
- Chapter 2: Information Levels and Frameworks
- Chapter 3: Conceptual Modeling: First Steps
- Chapter 4: Uniqueness Constraints
- Chapter 5: Mandatory Roles
- Chapter 6: Value, Set-Comparison, and Subtype Constraints
- Chapter 7: Other Constraints and Final Checks
- Chapter 8: Entity Relationship Modeling
- Chapter 9: Data Modeling in UML
- Chapter 10: Advanced Modeling Issues
- Chapter 11: Relational Mapping
- Chapter 12: Relational Languages
- Chapter 13: Other Database Features
- Chapter 14: Schema Transformations
- Chapter 15: Process and State Modeling
- Chapter 16: Other Modeling Aspects and Trends
- ORM Glossary
- ER Glossary
- UML Glossary
- Useful Web Sites
- Bibliography
- Index
- About the Authors
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Information Modeling and Relational Databases by Terry Halpin,Tony Morgan in PDF and/or ePUB format, as well as other popular books in Informatica & Modellazione e design di dati. We have over one million books available in our catalogue for you to explore.