
eBook - ePub
DW 2.0: The Architecture for the Next Generation of Data Warehousing
- 400 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
DW 2.0: The Architecture for the Next Generation of Data Warehousing
About this book
DW 2.0: The Architecture for the Next Generation of Data Warehousing is the first book on the new generation of data warehouse architecture, DW 2.0, by the father of the data warehouse. The book describes the future of data warehousing that is technologically possible today, at both an architectural level and technology level.
The perspective of the book is from the top down: looking at the overall architecture and then delving into the issues underlying the components. This allows people who are building or using a data warehouse to see what lies ahead and determine what new technology to buy, how to plan extensions to the data warehouse, what can be salvaged from the current system, and how to justify the expense at the most practical level. This book gives experienced data warehouse professionals everything they need in order to implement the new generation DW 2.0.
It is designed for professionals in the IT organization, including data architects, DBAs, systems design and development professionals, as well as data warehouse and knowledge management professionals.
- First book on the new generation of data warehouse architecture, DW 2.0
- Written by the "father of the data warehouse", Bill Inmon, a columnist and newsletter editor of The Bill Inmon Channel on the Business Intelligence Network
- Long overdue comprehensive coverage of the implementation of technology and tools that enable the new generation of the DW: metadata, temporal data, ETL, unstructured data, and data quality control
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Chapter 1 A brief history of data warehousing and first-generation data warehouses
In the beginning there were simple mechanisms for holding data. There were punched cards. There were paper tapes. There was core memory that was hand beaded. In the beginning storage was very expensive and very limited.
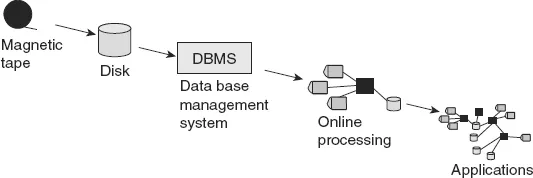
A new day dawned with the introduction and use of magnetic tape. With magnetic tape, it was possible to hold very large volumes of data cheaply. With magnetic tape, there were no major restrictions on the format of the record of data. With magnetic tape, data could be written and rewritten. Magnetic tape represented a great leap forward from early methods of storage.
But magnetic tape did not represent a perfect world. With magnetic tape, data could be accessed only sequentially. It was often said that to access 1% of the data, 100% of the data had to be physically accessed and read. In addition, magnetic tape was not the most stable medium on which to write data. The oxide could fall off or be scratched off of a tape, rendering the tape useless.
Disk storage represented another leap forward for data storage. With disk storage, data could be accessed directly. Data could be written and rewritten. And data could be accessed en masse. There were all sorts of virtues that came with disk storage.
DATA BASE MANAGEMENT SYSTEMS
Soon disk storage was accompanied by software called a “DBMS” or “data base management system.” DBMS software existed for the purpose of managing storage on the disk itself. Disk storage managed such activities as

Among all the benefits of disk storage, by far and away the greatest benefit was the ability to locate data quickly. And it was the DBMS that accomplished this very important task.
ONLINE APPLICATIONS
Once data could be accessed directly, using disk storage and a DBMS, there soon grew what came to be known as online applications. Online applications were applications that depended on the computer to access data consistently and quickly. There were many commercial applications of online processing. These included ATMs (automated teller processing), bank teller processing, claims processing, airline reservations processing, manufacturing control processing, retail point of sale processing, and many, many more. In short, the advent of online systems allowed the organization to advance into the 20th century when it came to servicing the day-to-day needs of the customer. Online applications became so powerful and popular that they soon grew into many interwoven applications.
Figure 1.1 illustrates this early progression of information systems.
In fact, online applications were so popular and grew so rapidly that in short order there were lots of applications.
And with these applications came a cry from the end user—“I know the data I want is there somewhere, if I could only find it.” It was true. The corporation had a whole roomful of data, but finding it was another story altogether. And even if you found it, there was no guarantee that the data you found was correct. Data was being proliferated around the corporation so that at any one point in time, people were never sure about the accuracy or completeness of the data that they had.
PERSONAL COMPUTERS AND 4GL TECHNOLOGY
To placate the end user’s cry for accessing data, two technologies emerged—personal computer technology and 4GL technology.
Personal computer technology allowed anyone to bring his/her own computer into the corporation and to do his/her own processing at will. Personal computer software such as spreadsheet software appeared. In addition, the owner of the personal computer could store his/her own data on the computer. There was no longer a need for a centralized IT department. The attitude was—if the end users are so angry about us not letting them have their own data, just give them the data.
At about the same time, along came a technology called “4GL” — fourth-generation technology. The idea behind 4GL technology was to make programming and system development so straightforward that anyone could do it. As a result, the end user was freed from the shackles of having to depend on the IT department to feed him/her data from the corporation.
Between the personal computer and 4GL technology, the notion was to emancipate the end user so that the end user could take his/her own destiny into his/her own hands. The theory was that freeing the end user to access his/her own data was what was needed to satisfy the hunger of the end user for data.
And personal computers and 4GL technology soon found their way into the corporation.
But something unexpected happened along the way. While the end users were now free to access data, they discovered that there was a lot more to making good decisions than merely accessing data. The end users found that, even after data had been accessed,
It was only after the end users got access to data that they discovered all the underlying problems with the data.
THE SPIDER WEB ENVIRONMENT
The result was a big mess. This mess is sometimes affectionately called the “spider’s web” environment. It is called the spider’s web environment because there are many lines going to so many places that they are reminiscent of a spider’s web.
Figure 1.2 illustrates the evolution of the spider’s web environment in the typical corporate IT environment.
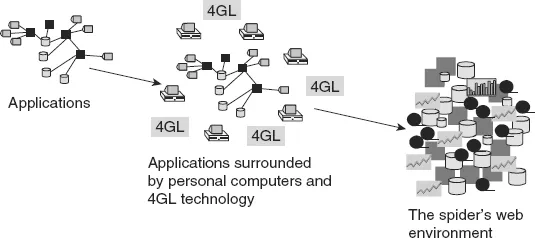
The spider’s web environment grew to be unimaginably complex in many corporate environments. As testimony to its complexity, consider the real diagram of a corp...
Table of contents
- Cover
- Title Page
- Copyright
- Dedication
- Preface
- Acknowledgments
- About the Authors
- Table of Contents
- Chapter 1: A brief history of data warehousing and first-generation data warehouses
- Chapter 2: An introduction to DW 2.0
- Chapter 3: DW 2.0 components—about the different sectors
- Chapter 4: Metadata in DW 2.0
- Chapter 5: Fluidity of the DW 2.0 technology infrastructure
- Chapter 6: Methodology and approach for DW 2.0
- Chapter 7: Statistical processing and DW 2.0
- Chapter 8: Data models and DW 2.0
- Chapter 9: Monitoring the DW 2.0 environment
- Chapter 10: DW 2.0 and security
- Chapter 11: Time-variant data
- Chapter 12: The flow of data in DW 2.0
- Chapter 13: ETL processing and DW 2.0
- Chapter 14: DW 2.0 and the granularity manager
- Chapter 15: DW 2.0 and performance
- Chapter 16: Migration
- Chapter 17: Cost justification and DW 2.0
- Chapter 18: Data quality in DW 2.0
- Chapter 19: DW 2.0 and unstructured data
- Chapter 20: DW 2.0 and the system of record
- Chapter 21: Miscellaneous topics
- Chapter 22: Processing in the DW 2.0 environment
- Chapter 23: Administering the DW 2.0 environment
- Index
- Instructions for online access
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access DW 2.0: The Architecture for the Next Generation of Data Warehousing by W.H. Inmon,Derek Strauss,Genia Neushloss in PDF and/or ePUB format, as well as other popular books in Business & Business Intelligence. We have over 1.5 million books available in our catalogue for you to explore.