
- 100 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Data Mining for Bioinformatics Applications
About this book
Data Mining for Bioinformatics Applications provides valuable information on the data mining methods have been widely used for solving real bioinformatics problems, including problem definition, data collection, data preprocessing, modeling, and validation.
The text uses an example-based method to illustrate how to apply data mining techniques to solve real bioinformatics problems, containing 45 bioinformatics problems that have been investigated in recent research. For each example, the entire data mining process is described, ranging from data preprocessing to modeling and result validation.
- Provides valuable information on the data mining methods have been widely used for solving real bioinformatics problems
- Uses an example-based method to illustrate how to apply data mining techniques to solve real bioinformatics problems
- Contains 45 bioinformatics problems that have been investigated in recent research
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
1
An overview of data mining
Abstract
Data mining is the process of discovering knowledge from data, which consists of many steps. In each step, different techniques can be applied. In this chapter, we first present the data mining process model. Then, we discuss each step in this process with special emphasis on the key data modeling methods such as frequent pattern mining, discriminative pattern mining, classification, regression, and clustering. Finally, we suggest several data mining textbooks for further readings.
Keywords
Data mining
Pattern discovery
Classification
Clustering
Regression
1.1 What’s data mining?
Data mining lies at the intersection of computer science, optimization, and statistics, and often appears in other disciplines. Generally, data mining is the process of searching for knowledge in data from different perspectives. Here knowledge can refer to any kinds of summarized or unknown information that are hidden underlying the raw data. For instance, it can be a set of discriminative rules generated from the data collected on some patients of a certain disease and healthy people. These rules can be used for predicting the disease status of new patients.
In general, data mining tasks can be classified into two categories: descriptive and predictive. Descriptive mining tasks characterize a target data set in concise, informative, discriminative forms. Predictive mining tasks conduct the induction and inference on the current data to make future predictions.
1.2 Data mining process models
Data mining is an iterative process that consists of many steps. There are already some generic reference models on the data mining process, such as the Cross Industry Standard Process for Data Mining (CRISP-DM) process model. From a data-centric perspective, these models are structured as sequences of steps to transform the raw data into information or knowledge that is practically useful. As shown in Figure 1.1, a data mining process model typically involves the following phases: data collection, data preprocessing, data modeling, model assessment, and model deployment.
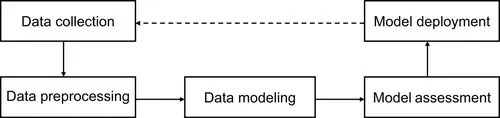
Figure 1.1 Typical phases involved in a data mining process model.
1.3 Data collection
The first step in the data mining process is to collect the relevant data according to the analysis goal in the applications. Generally, all the data that are helpful to achieve the objective in the analysis should be included. The key point here is how to define and understand the rather subjective term of “relevant data.” Its correct interpretation highly depends on our understanding of the target problem and application background. Although this point will be further illustrated in subsequent chapters, we offer some general remarks here:
• In some cases, people definitely know that some kinds of data are highly relevant to the data mining task at hand. However, the acquisition of such data is very difficult or even impossible due to the device deficiency or cost. For instance, to accurately identify peptides in mass-spectrometry-based shotgun proteomics, it is necessary to generate at least one mass spectrum for each peptide in the sample. However, due to the limitation of current mass spectrometers, it is not always possible to obtain mass spectra data that can cover all peptides present in the sample.
• On the other hand, the inclusion of new relevant data may significantly change the models and methods in the consequent steps of the data mining process. Furthermore, it is necessary to check thoroughly if the use of more relevant data will boost the performance of data mining procedures.
1.4 Data preprocessing
The objective of data preprocessing is twofold: (1) The real-world data are usually low quality; hence preprocessing is used to improve the quality of data, and consequently, the quality of data mining results. (2) In the data modeling step, some specific modeling algorithms cannot operate on the raw data, which should be transformed into some predefined data formats.
There are several general-purpose data preprocessing methods: data cleaning, data integration, data reduction, and data transformation.
Data cleaning: Real-world data are usually noisy, inconsistent, and incomplete. Data cleaning procedures aim at removing the noise, correcting inconsistencies, and filling in missing values in the data.
Data integration: In the data collection phase, data sets from different sources are relevant to the analysis problem. Data integration merges data from different sources into an integrated data set for subsequent data mining analysis. The main objective of data integration is to reduce and avoid redundancies and inconsistencies in the resulting data set.
Data reduction: The purpose of data reduction is to generate a new yet smaller representation of the original data set. Generally, the reduced data should contain approximately the same information of the original data that is of primary importance to the analysis target. The most commonly used data reduction technique includes dimension reduction (vertically, reduce the number of features) and sampling (horizontally, reduce the number of samples).
Data transformation: Different data mining algorithms may require different forms of data. Data transformation techniques consolidate the original data into forms appropriate for subsequent mining tasks. For instance, data normalization will transform the feature values into a predefined range such as [0.0, 1.0]. Data discretization will replace a continuous feature with a discrete one by dividing numeric values into intervals.
1.5 Data modeling
Before discussing the data modeling algorithms, it would be best to explain some terminology. Typically, the data preprocessing step would transform the raw data into a tabular form, in which the columns represent features/variables and rows correspond to samples/instances. For instance, Table 1.1 is a sample data set that has eight samples and five features (class is a special feature for which we are aiming to predict its feature value for a new given sample). The first four features are called predictive features and the class feature is the target feature. Here the predictive features can be symptoms of some disease, where the value of 1 indicates the existence of a symptom and 0 indicates otherwise. Similarly, the class feature value is 1 if the corresponding person (sample) has the disease.
Table 1.1
An ex...
Table of contents
- Cover image
- Title page
- Table of Contents
- Copyright
- List of figures
- List of tables
- About the author
- Dedication
- 1: An overview of data mining
- 2: Introduction to bioinformatics
- 3: Phosphorylation motif discovery
- 4: Phosphorylation site prediction
- 5: Protein inference in shotgun proteomics
- 6: PPI network inference from AP-MS data
- 7: Protein complex identification from AP-MS data
- 8: Biomarker discovery
- Conclusions
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Data Mining for Bioinformatics Applications by He Zengyou in PDF and/or ePUB format, as well as other popular books in Commerce & Business Intelligence. We have over one million books available in our catalogue for you to explore.