![]()
Part II
Data Networks
![]()
3
Internet Protocol (IP) Address Lookup
CONTENTS
3.1 Introduction
3.2 Basic Binary Tree
3.3 Disjoint Trie
3.3.1 Procedure to Build a Disjoint Trie
3.4 Path-Compressed Trie
3.5 Multibit Trie
3.6 Level-Compressed Trie
3.7 Lulea Algorithm
3.7.1 Number of Prefix Levels
3.7.2 Representation of Prefixes as a Bit Vector
3.7.2.1 Code Field and Maptable
3.7.2.2 Code Field
3.7.2.3 Lulea Matching Process
3.8 DIR-24-8 Scheme
3.9 Bloom Filter-Based Algorithm
3.9.0.4 IP Address Lookup Using a Bloom Filter
3.10 Helix: A Parallel-Search Lookup Scheme
3.11 Ternary Content-Addressable Memory
3.12 Additional Readings
3.13 Exercises
Finding out the egress port a packet traversing a network node, or router, requires performing the longest prefix matching between the destination of the packet to a prefix in the forwarding table. This process is called Internet Protocol (IP) address lookup, or just IP lookup. It requires to access this table to retrieve the next-hop information (NHI), which is the IP address or the router’s egress port number where a packet is forwarded.
The forwarding table resides in the memory of the router. Every time a packet arrives in a router, memory storing the forwarding table is accessed to perform IP lookup. Unfortunately, memory is a component whose speed lags in comparison to the rates at which data can be transmitted through (optical) network links. This speed mismatch requires to perform lookup using the smallest number of memory accesses. In addition, to improve feasibility in building such schemes, the amount of required memory must be implementable. Furthermore, IP lookup mechanisms should be able to accommodate changes of the forwarding table caused by changes in routing tables, in an expeditious manner so as not to interrupt the lookup process.
3.1 Introduction
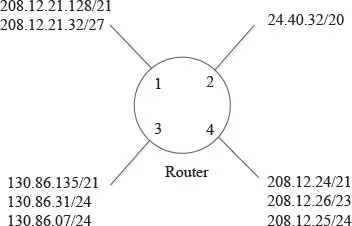
Classless Interdomain Routing (CIDR) [67] is an approach used to aggregate IP addresses as prefix. This aggregation of addresses has the objective of reducing the number of entries in a memory holding a forwarding table of an Internet router. CIDR uses a technique called supernetting to summarize a range of addresses represented as the combination of a prefix and prefix length. The prefix includes a range of addresses that are reachable by a given router port. Figure 3.1 shows an example of address aggregation at a router. In this figure, different networks, which are represented as ranges of addresses or prefixes, are reachable through different ports. Those addresses that share common most significant bits (MSBs) and are reachable through the same router port may be aggregated.
With CIDR, addresses can be aggregated at arbitrary levels, and IP lookup becomes a matching to the longest prefix. Specifically, a forwarding table consists of a set of IP routes. Each IP route is represented by a <prefix/prefix length> pair. The prefix length indicates the number of significant bits in the prefix, starting from the MSB. To perform IP lookup, the forwarding table is searched to obtain the longest matching prefix from among all the possible prefixes that match the destination IP address of an incoming packet. Then, the output port information for the longest matched prefix is retrieved and used for forwarding the packet. For example, a forwarding table may have three IP routes: <12.0.54.8/32>, <12.0.54.0/24>, and <12.0.0.0/16>. If an incoming packet has the destination IP address <12.0.54.2>, prefix <12.0.54.0/24> is the longest matched and its associated output port is retrieved and used for forwarding the packet.
Although CIDR resolves the aggregation of addresses to minimize the number of entries in a forwarding table (and in turn, in the memory of a router), the search for the matching prefix becomes more complex than performing exact matching (as used in label switching).
The complexity of address lookup is high because: 1) prefix lengths may be large and the adoption of IPv6 may increase these lengths even further, and 2) the number of prefixes is increasingly large for version 4 of the IP protocol, IPv4, and it is expected to grow with IPv6. In 1), the longest matching prefix is selected; so this selection requires a search for prefixes in all different lengths and to keep records of the longest prefix that last matched the destination address.
FIGURE 3.1
Forwarding information per port.
Prefixes have to be carefully stored and searched so as to minimize the number of times the memory storing the prefixes is accessed. The following example illustrates part of the search problem, whose complexity is affected by the relationship between the address of an entry and the entry content. Table 3.1 has eight entries (or rows) and each entry holds a number as content. Let’s consider the contents of the table as a 20-number set, where each can take a value between 0 and 19. Note that the range of values an entry can have is a larger than the table size. Let’s also consider that no entry has a duplicate. Let’s assume that the entry contents are the set {...