
- 495 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
About this book
This book unravels the mystery of Big Data computing and its power to transform business operations. The approach it uses will be helpful to any professional who must present a case for realizing Big Data computing solutions or to those who could be involved in a Big Data computing project. It provides a framework that enables business and technical managers to make optimal decisions necessary for the successful migration to Big Data computing environments and applications within their organizations.
Tools to learn more effectively

Saving Books

Keyword Search

Annotating Text

Listen to it instead
Information
1
Computing Beyond the Moore’s Law Barrier While Being More Tolerant of Faults and Failures
Since the advent of computer in the 1950s, weather forecasting has been a hugely challenging computational problem. Right since the beginning, weather models ran on a single supercomputer that could fill a gymnasium and contained a couple of fast (for the 1970s) CPUs with very expensive memory. Software in the 1970s was primitive, so most of the performance at that time was in clever hardware engineering. By the 1990s, software had improved to the point where a large program running on monolithic supercomputers could be broken into a hundred smaller programs working simultaneously on a hundred workstations. When all the programs finished running, their results were stitched together to form a weeklong weather simulation. What used to take fifteen days to compute and simulate seven days of weather even in the 90’s, today the parallel simulations corresponding to a weeklong forecast can be accomplished in a matter of hours.
There are lots of data involved in weather simulation and prediction, but weather simulation is not considered a representative of “big data” problems because it is computationally intensive rather than being data intensive. Computing problems in science (including meteorology and engineering) are also known as high-performance computing (HPC) or scientific supercomputing because they entail solving millions of equations.
Big data is the commercial equivalent of HPC, which could also be called high-performance commercial computing or commercial supercomputing. Big data can also solve large computing problems, but it is less about equations and more about discovering patterns. Today companies such as Amazon, eBay, and Facebook use commercial supercomputing to solve their Internet-scale business problems. Big data is a type of supercomputing for commercial enterprises and governments that will make it possible to monitor a pandemic as it happens, anticipate where the next bank robbery will occur, optimize fast-food supply chains, predict voter behavior on election day, and forecast the volatility of political uprisings while they are happening.
Big data can be defined as data sets whose size is beyond the ability of typical database software tools to capture, store, manage, and analyze.
Big data is different from the traditional concept of data in terms of the following:
• Bigger volume: There is more than a half-a-trillion pieces of content (photos, notes, blogs, web links, and news stories) shared on Facebook every month and 4 billion hours of video are watched at YouTube every month. It is believed that there will be more than 50 billion connected devices in the world by 2020.
• Higher velocity: At 140 characters per tweet, Twitter-generated data volume is larger than 10 terabytes per day. It is believed that more data were created between 2008 and 2011 than in all history before 2008.
• More data variety: It is estimated that 95% of the world data are unstructured, which makes big data extremely challenging. Big data could exist in various formats, namely, video, image, audio, text/numbers, and so on.
• Different degree of veracity: The degree of authenticity or accuracy of data ranges from objective observations of physical phenomenon to subjective observations or opinions expressed on social media.
Storing, managing, accessing, and processing of this vast amount of data represent a fundamental need and an immense challenge in order to satisfy the need to search, analyze, mine, and visualize these data as information.
1.1 Moore’s Law Barrier
On April 19, 1965, Gordon Moore, the cofounder of Intel Corporation, published an article in Electronics Magazine titled “Cramming More Components onto Integrated Circuits” in which he identified and conjectured a trend that computing power would double every 2 years (this was termed as Moore’s law in 1970 by the CalTech professor and VLSI pioneer, Calvin Mead). This law has been able to predict reliably both the reduction in costs and the improvements in computing capability of microchips, and those predictions have held true (see Figure 1.1).
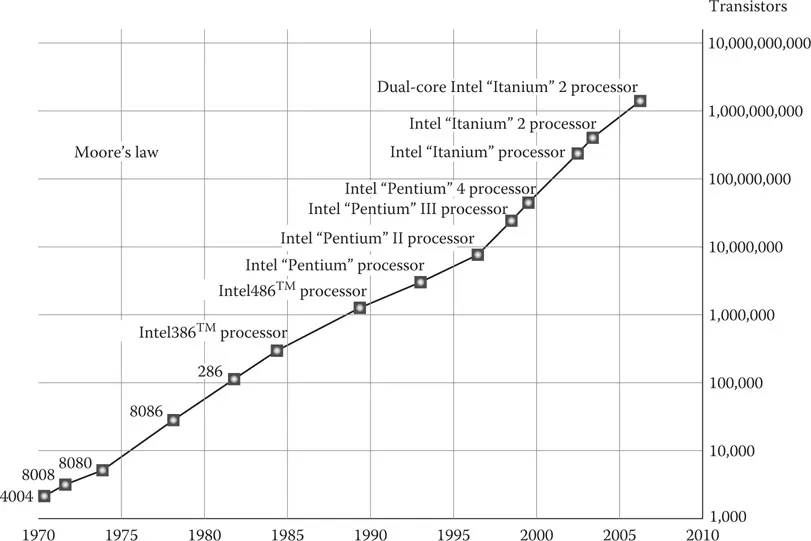
FIGURE 1.1
Increase in the number of transistors on an Intel chip.
Increase in the number of transistors on an Intel chip.
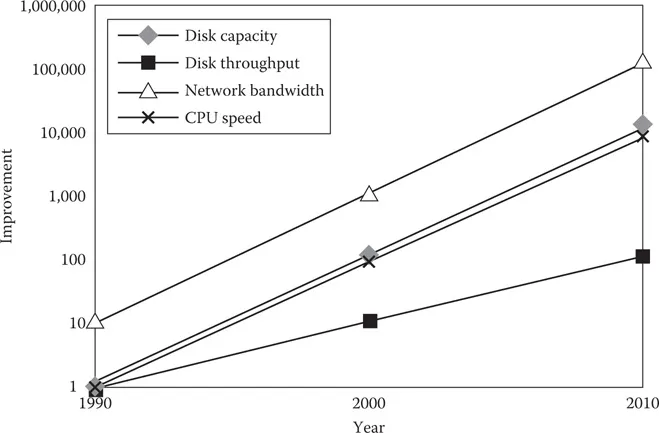
FIGURE 1.2
Hardware trends in the 1990s and the first decade.
Hardware trends in the 1990s and the first decade.
In 1965, the amount of transistors that fitted on an integrated circuit could be counted in tens. In 1971, Intel introduced the 4004 microprocessor with 2,300 transistors. In 1978, when Intel introduced the 8086 microprocessor, the IBM PC was effectively born (the first IBM PC used the 8088 chip)—this chip had 29,000 transistors. In 2006, Intel’s Itanium 2 processor carried 1.7 billion transistors. In the next couple of years, we will have chips with over 10 billion transistors. While all this was happening, the cost of these transistors was also falling exponentially, as per Moore’s prediction (Figure 1.2).
In real terms, this means that a mainframe computer of the 1970s that cost over $1 million had less computing power than the iPhone has today. The next generation of smartphone in the next few years will have GHz processor chips, which will be roughly one million times faster than the Apollo Guidance Computer that put “man on the moon.” Theoretically, Moore’s law will run out of steam somewhere in the not too distant future. There are a number of possible reasons for this.
First, the ability of a microprocessor silicon-etched track or circuit to carry an electrical charge has a theoretical limit. At some point when these circuits get physically too small and can no longer carry a charge or the electrical charge bleeds, we will have a design limitation problem. Second, as successive generations of chip technology are developed, manufacturing costs increase. In fact, Gordon Moore himself conjectured that as tolerances become tighter, each new generation of chips would require a doubling in cost of the manufacturing facility. At some point, it will theoretically become too costly to develop manufacturing plants that produce these chips.
The usable limit for semiconductor process technology will be reached when chip process geometries shrink to be smaller than 20 nanometers (nm) to 18 nm nodes. At those scales, the industry will start getting to the point where semiconductor manufacturing tools would be too expensive to depreciate with volume production; that is, their costs will be so high that the value of their lifetime productivity can never justify it.
Lastly, the power requirements of chips are also increasing. More power being equivalent to more heat equivalent to bigger batteries implies that at some point, it becomes increasingly difficult to power these chips while putting them on smaller platforms.
1.2 Types of Computer Systems
Today’s computer systems come in a variety of sizes, shapes, and computing capabilities. The Apollo 11 spacecraft that enabled landing men on the moon and returning them safely to the earth was equipped with a computer that assisted them in everything from navigation to systems monitoring, and it had a 2.048 MHz CPU built by MIT. Today’s standards can be measured in 4 GHz in many home PCs (megahertz [MHz] is 1 million computing cycles per second, while gigahertz [GHz] is 1 billion computing cycles per second). Further, the Apollo 11 computer weighed 70 pounds versus today’s powerful laptops weighing as little as 1 pound—we have come a long way. Rapid hardware and software developments and changing end user needs continue to drive the emergence of new models of computers, from the smallest handheld personal digital assistant/cell phone combinations to the largest multiple-CPU mainframes for enterprises. Categories such as microcomputer, midrange, mainframe, and supercomputer systems are still used to help us express the relative processing power and number of end users that can be supported by different types of computers. These are not precise classifications, and they do overlap each other.
1.2.1 Microcomputers
Microcomputers are the most important category of computer systems for both business and household consumers. Although usually called a personal computer, or PC, a microcomputer is much more than a small computer for use by an individual as a communication device. The computing power of microcomputers now exceeds that of the mainframes of previous computer generations, at a fraction of their cost. Thus, they have become powerful networked professional workstations for business professionals.
1.2.2 Midrange Computers
Midrange computers are primarily high-end network servers and other types of servers that can handle the large-scale processing of many business applications. Although not as powerful as mainframe computers, they are less costly to buy, operate, and maintain than mainframe systems and thus meet the computing needs of many organizations. Midrange systems first became popular as minicomputers in scientific research, instrumentation systems, engineering analysis, and industrial process monitoring and control. Minicomputers were able to easily handle such functions because these applications are narrow in scope and do not demand the processing versatility of mainframe systems. Today, midrange systems include servers used in industrial process control and manufacturing plants and play major roles in computer-aided manufacturing (CAM). They can also take the form of powerful technical workstations for computer-aided design (CAD) and other computation and graphics-intensive applications. Midrange systems are also used as front-end servers to assist mainframe computers in telecommunications processing and network management.
Midrange systems have become popular as powerful network servers (computers used to coordinate communications and manage resource sharing in network settings) to help manage large Internet websites, corporate intranets and extranets, and other networks. Internet functions and other applications are popular high-end server applications, as are integrated enterprise-wide manufacturing, distribution, and financial applications. Other applications, such as data warehouse management, data mining, and online analytical processing, are contributing to the demand for high-end server systems.
1.2.3 Mainframe Computers
Mainframe computers are large, fast, and powerful computer systems; they can process thousands of million instructions per second (MIPS). They can also have large primary storage capacities with main memory capacity ranging from hundreds of gigabytes to many terabytes. Mainframes have downsized drastically in the last few years, dramatically reducing their air-conditioning needs, electrical power consumption, and floor space requirements—and thus their acquisition, operating, and ownership costs. Most of these improvements are the result of a move from the cumbersome water-cooled mainframes to a newer air-cooled technology for mainframe systems.
Mainframe computers continue to handle the information processing needs of major corporations and government agencies with high transaction processing volumes or complex computational problems. For example, major international banks, airlines, oil companies, and other large corporations process millions of sales transactions and customer inquiries every day with the help of large mainframe systems. Mainframes are still used for computation-intensive applications, such as analyzing seismic data from oil field explorations or simulating flight conditions in designing aircraft.
Mainframes are also widely used as superservers for large client/server networks and high-volume Internet websites of large companies. Mainframes are becoming a popular business computing platform for data mining and warehousing, as well as electronic commerce applications.
1.2.4 Supercomputers
Supercomputers are a category of extremely powerful computer systems specifically designed for scientific, engineering, and business applications requiring extremely high speeds for massive numeric computations. Supercomputers use parallel processing architectures of interconnected microprocessors (which can execute many parallel instructions). They can easily perform arithmetic calculations at speeds of billions of floating-point -operations per second (gigaflops)—a floating point operation is a basic computer -arithmetic operation, such as addition, on numbers that include a decimal point. Supercomputers that can calculate in trillions of floating-point operations per second (teraflops), which use massively parallel processing (MPP) designs of thousands of microprocessors, are now in use (see Chapter 1 Sub-section 1.4.4,“Massively Parallel Processing”).
The market for supercomputers includes government research agencies, large universities, and major corporations. They use supercomputers ...
Table of contents
- Title Page
- Copyright Page
- Dedication Page
- Contents
- List of Figures
- List of Tables
- Preface
- Acknowledgments
- Author
- 1. Computing Beyond the Moore’s Law Barrier While Being More Tolerant of Faults and Failures
- Section I Genesis of Big Data Computing
- Section II Road to Big Data Computing
- Section III Big Data Computing
- Section IV Big Data Computing Applications
- Epilogue: Internet of Things
- References
- Index
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Big Data Computing by Vivek Kale in PDF and/or ePUB format, as well as other popular books in Business & Information Management. We have over one million books available in our catalogue for you to explore.